为了能够使得Kubernetes集群中的容器运行得更加稳定,用户需要熟练掌握Kubernetes集群的常用管理方法。例如,节点(Node)的管理、资源标签的管理以及监控方法等。本章将系统介绍这些方面的内容,以提高用户运维Kubernetes集群的水平。
节点(Node)是Kubernetes集群中各项应用服务的实际提供者。因此,节点能否正常运行将直接影响到整个Kubernetes集群的服务质量。本节将详细介绍在Kubernetes集群运维过程中经常用到的节点管理方法。
通常情况下,Kubernetes集群中的节点都是由Master节点统一调度、管理的。在Kubernetes集群运行的过程中,难免会遇到某些特殊的情况,例如节点所在主机的硬件维护或者升级。此时,用户需要避免新的计算任务被调度到当前节点。
Kubernetes提供了一种节点的隔离与恢复机制,通过隔离,使得当前的节点脱离Master节点的调度范围,在硬件维护完成之后,通过恢复机制又重新纳入到Master节点的调度范围中。
用户可以通过几种方式来实现节点的隔离和恢复,分别为配置文件、kubectl patch命令、kubectl cordon命令以及kubectl drain命令。下面分别进行介绍。
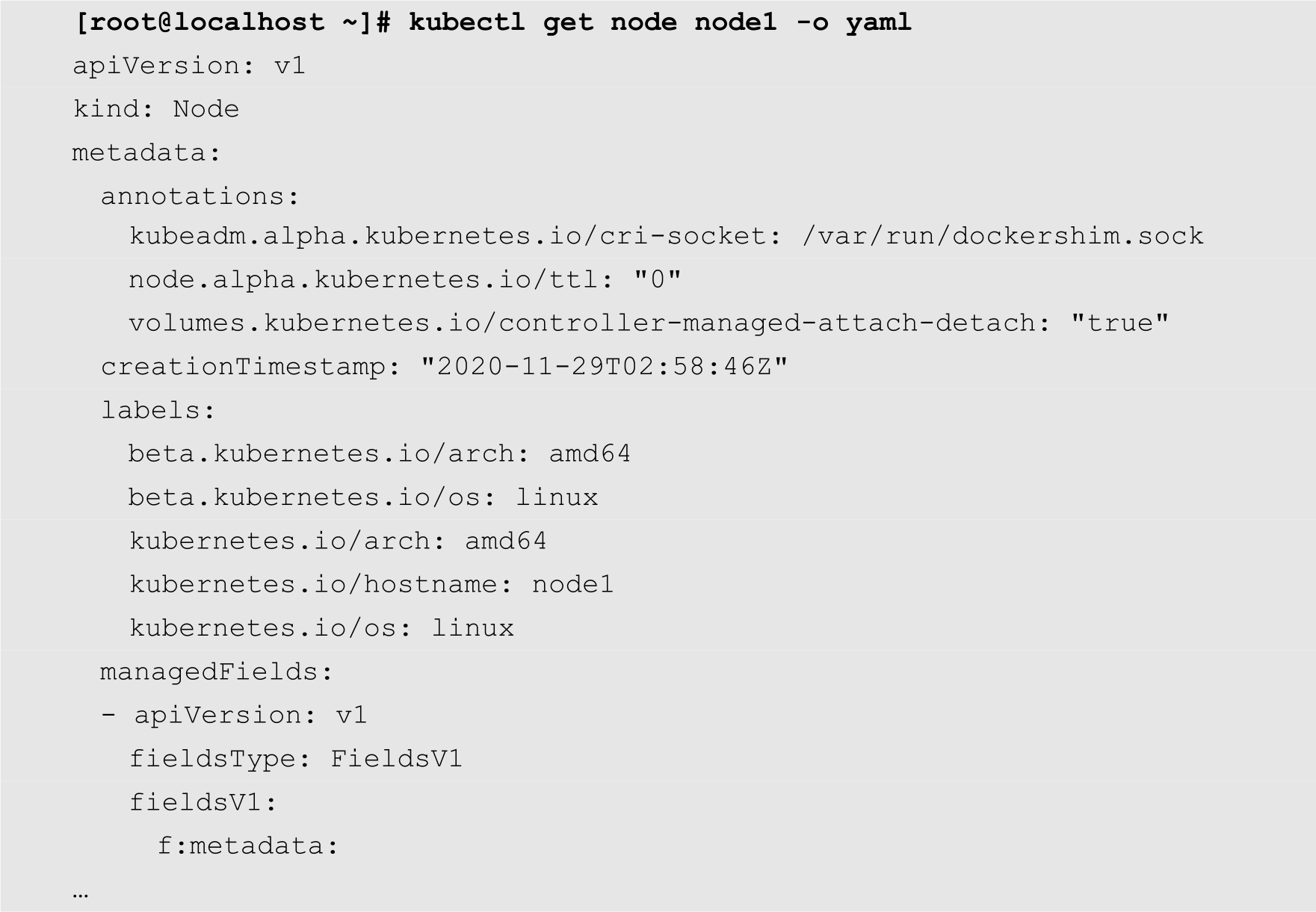
如果是通过配置文件来实现节点的隔离,需要提供节点的完整的配置文件。用户可以通过以下命令来获取某个节点的配置文件代码:
其中node1为节点的名称,-o选项用来指定输出格式为YAML。将以上代码保存为unschedulable.yaml文件,然后在其中的spec部分增加以下代码:
unschedulable: true
修改后的unschedulable.yaml文件的内容如下:
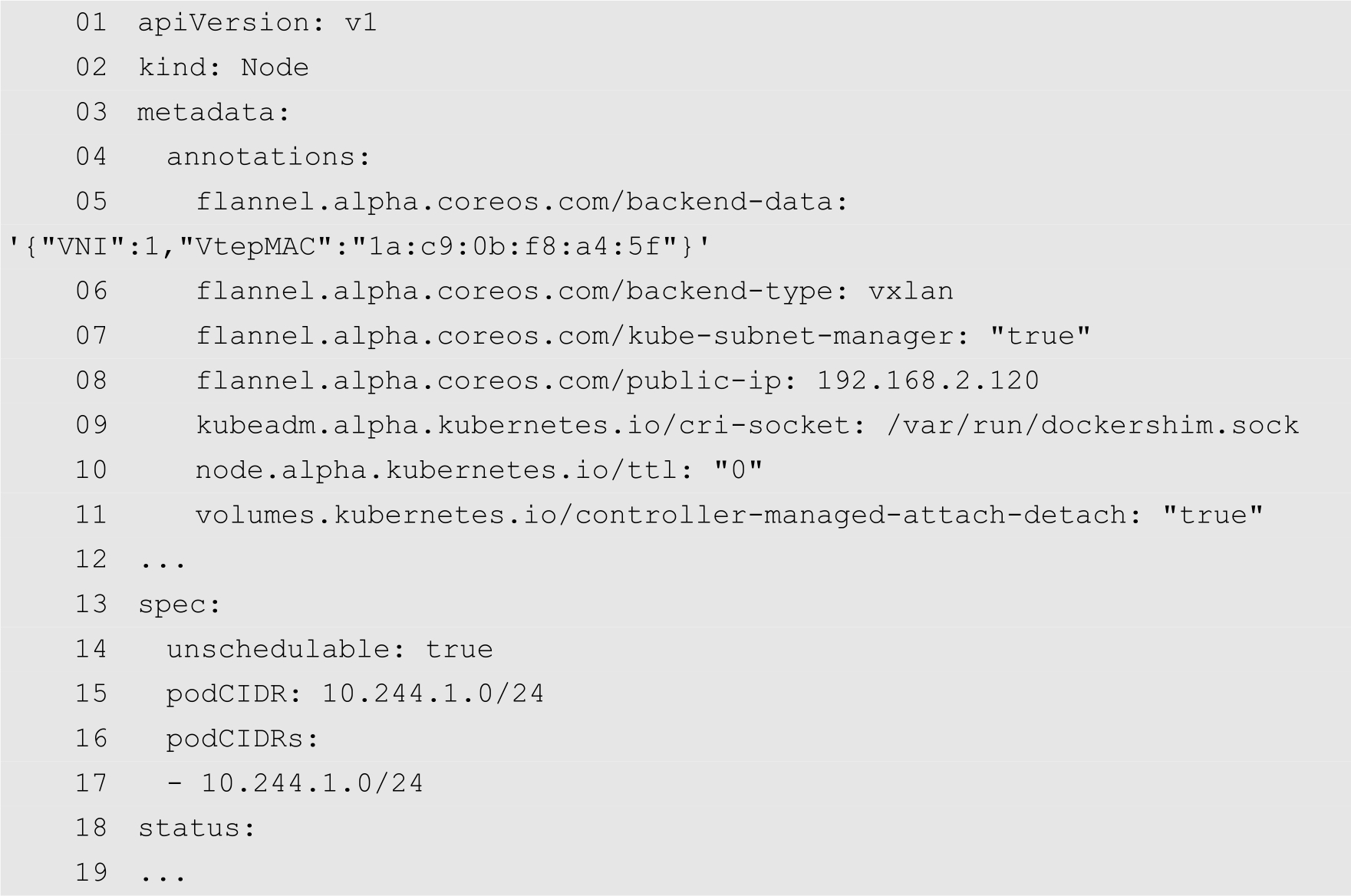
然后使用kubectl replace命令对节点状态进行修改,如下所示:
[root@localhost ~]# kubectl replace -f unschedulable.yaml node/node1 replaced
当以上命令成功执行以后,查看一下Node的状态,命令如下:

从上面的输出结果可知,名为node1的节点的状态列中增加了一个SchedulingDisabled状态项,表示当前的节点为隔离状态。查看node1的详细信息,也可以发现当前节点的Unschedulable的值为true,如下所示:
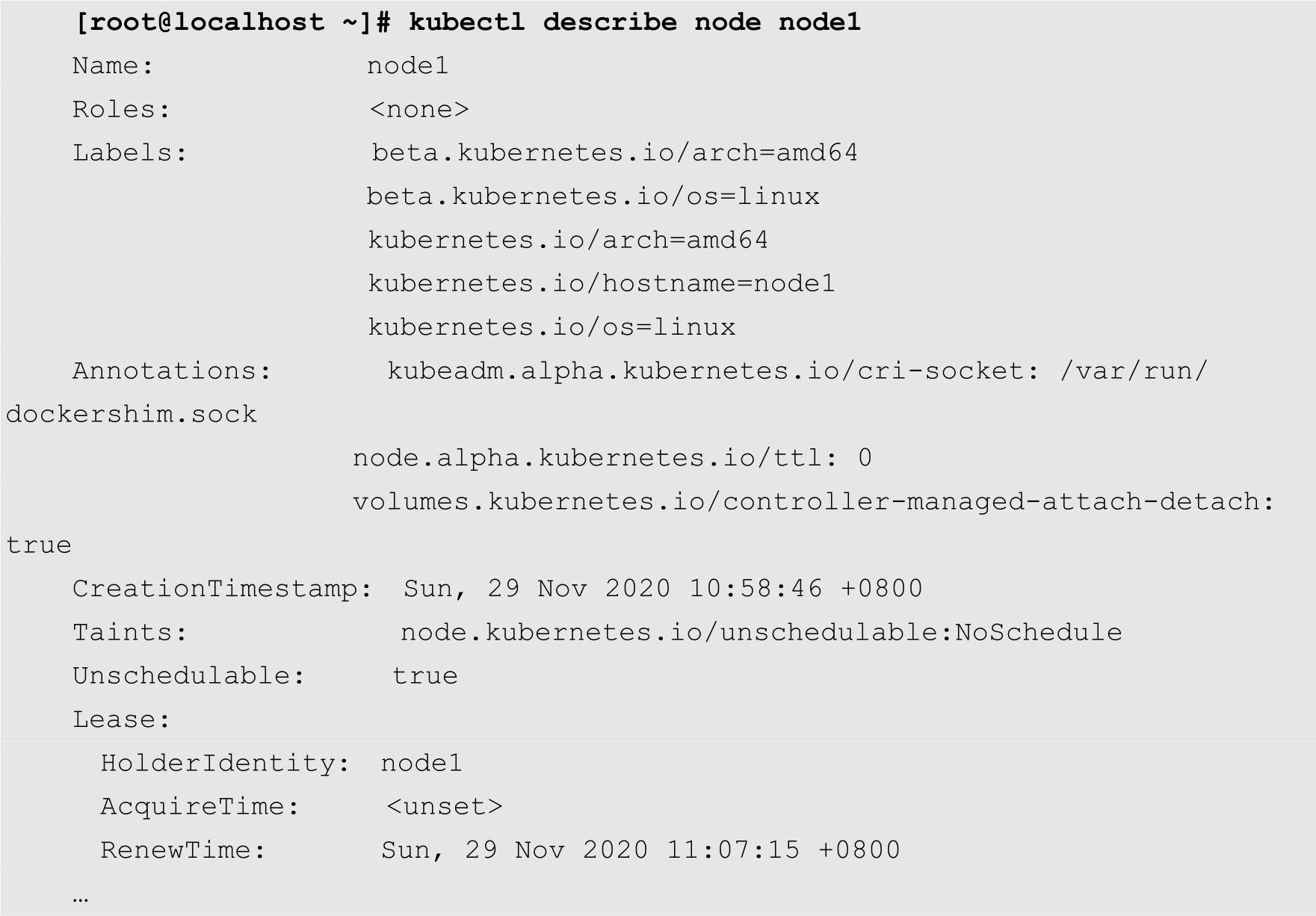
当用户在Kubernetes集群中创建新的Pod时,Kubernetes不会向处于SchedulingDisabled状态的节点进行调度,即Kubernetes不会在处于SchedulingDisabled状态的节点上创建新的Pod。对于已经运行在该节点上的Pod,则不会自动停止,用户需要手动停止这些Pod,然后再进行维护。
在节点维护工作完成之后,用户想要恢复该节点,将其恢复到Kubernetes集群的管理之下,那么只需要将前面的unschedulable.yaml配置文件中的unschedulable修改为false,其余代码无需修改,如下所示:

将修改后的代码保存为schedulable.yaml,然后使用kubectl replace命令将其恢复,如下所示:
[root@localhost ~]# kubectl replace -f schedulable.yaml node/node1 replaced
命令执行成功之后,查看节点的状态,如下所示:

从上面的输出结果可知,node1的状态中的SchedulingDisabled已经被去掉,此时node1处于Kubernetes的调度范围之中。
注意
如果在执行kubectl replace的时候出现以下错误:
Error from server (Conflict): error when replacing "schedulable.yaml": Operation cannot be fulfilled on nodes "node1": the object has been modified; please apply your changes to the latest version and try again
则表示资源的版本发生冲突,用户可以修改YAML配置文件,将其中的resourceVersion一行删除,如下所示:
resourceVersion: "11128"
然后再执行kubectl replace命令。
kubectl patch命令可以对Kubernetes集群中的资源进行更新,支持JSON和YAML两种格式。例如,下面的命令对名为node1的节点的配置进行修改,将其改为隔离状态:

在上面的命令中,-p选项用来指定要应用的修改内容,此处使用JSON格式表示。其功能是将node1的配置文件中的spec主键下面的unschedulable主键的值修改为true。当以上命令执行成功之后,查看node1的状态,如下所示:

从上面的输出结果可知,node1的状态中已经增加了SchedulingDisabled状态。
如果想要恢复node1,则只要将命令中的unschedulable主键的值修改为false即可,如下所示:

用户可以通过命令查看node1的状态。
前面介绍的kubectl patch不仅可以修改节点的状态,还可以修改Kubernetes中任何资源的配置。在新版本的Kubernetes中,kubectl cordon命令专门用来对节点进行隔离和恢复。
kubectl cordon命令的基本语法比较简单,只要提供节点的名称作为参数即可,如下所示:

如果想要恢复节点,则需要使用kubectl uncordon命令,如下所示:

前面介绍的命令在隔离节点之后,被隔离的节点上的Pod并不会停止,也不会被驱逐。而kubectl drain命令除了隔离节点之外,还对被隔离的节点上的Pod进行驱逐。如下所示:

对于使用kubectl drain命令隔离的节点,可以使用前面介绍的命令进行恢复,例如,下面调用kubectl uncordon命令恢复node1:
[root@localhost ~]# kubectl uncordon node1 node/node1 uncordoned
在Kubernetes集群运行一段时间之后,随着业务的增长,集群中的计算资源会出现不能满足需求的情况。此时,用户可以购买新的服务器,在上面部署Kubernetes的节点组件,并将其添加到Kubernetes集群中去,实现节点的扩容。下面详细介绍如何将一台新的CentOS 8的服务器加入到Kubernetes集群中。
(1)设置主机名。在加入到Kubernetes集群时,主机名会作为节点的名称,因此,新主机的主机名必须能够标识当前的主机,并且不能与Kubernetes集群中的其他节点的名称相同。
[root@localhost ~]# hostnamectl set-hostname node2
通过以上命令,将当前主机的主机名设置为node2,表示这是当前Kubernetes集群中的第2个节点。
(2)关闭firewalld防火墙,命令如下:

(3)关闭交换分区,命令如下:
[root@localhost ~]# swapoff -a && sysctl -w vm.swappiness=0 vm.swappiness = 0
修改/etc/fstab文件,注释掉关于交换分区的挂载选项,如下所示:

(4)开启iptable的桥接功能,如下所示:
(5)关闭SELinux,命令如下:

(6)配置Kubernetes的阿里云软件源,命令如下:
(7)配置Docker的阿里云软件源,命令如下:

(8)安装Docker,命令如下:
[root@localhost ~]# dnf install -y docker-ce
安装完成之后,启用并启动Docker,如下所示:

注意
如果在安装Docker的过程中出现以下错误:
Error: Problem: package docker-ce-3:19.03.13-3.el7.x86_64 requires containerd.io >= 1.2.2-3, but none of the providers can be installed
则表示当前的系统中的containerd.io组件的版本过低,用户可以使用以下命令安装高版本的containerd.io:
[root@localhost ~]# dnf install -y https://download.docker.com/linux/centos/8/ x86_64/edge/Packages/containerd.io-1.3.7-3.1.el8.x86_64.rpm
(9)安装Kubernetes组件,命令如下:
[root@localhost ~]# dnf install -y kubelet kubeadm --disableexcludes=
kubernetes
安装完成之后,启动kubelet服务,命令如下:

(10)拉取镜像,命令如下:
[root@localhost ~]# docker pull registry.aliyuncs.com/google_containers/
kube-proxy:v1.19.4
在节点主机上,用户需要安装kube-proxy组件,因此在上面的命令中,只需拉取kube-proxy的镜像文件。
(11)将新的节点注册到Kubernetes集群中,然后执行以下命令:
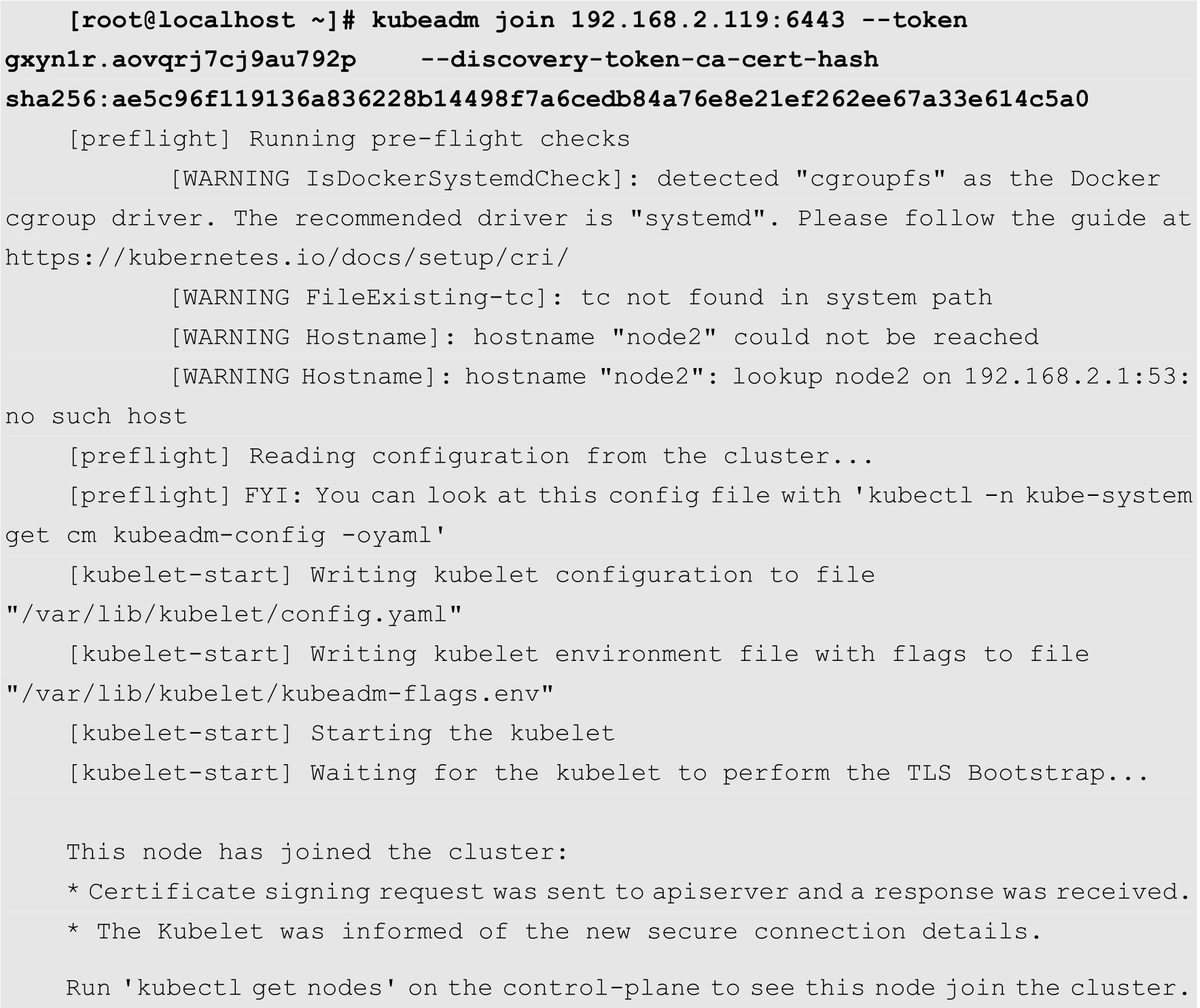
其中,192.168.2.119:6443为Kubernetes的Master主机的IP地址以及服务端口。--token用来指定认证所用的Token,该Token在初始化集群的时候自动生成。如果忘记了Token,用户可以在Master主机上通过以下命令查看:

在上面的输出结果中,TOKEN列就是当前集群的认证Token。
--discovery-token-ca-cert-hash选项用来指定当前集群的CA证书的Hash值。该Hash值是在初始化集群时自动生成的。如果忘记了该Hash值,用户可以使用以下命令获取:

其中,-in选项指定CA证书的路径。该命令的返回值即为所需要的Hash值。
(12)查看节点状态。在Master节点上面查看节点的状态,命令如下:

从上面的输出结果可知,新加入的node2已经处于Ready(就绪)状态。
标签是Kubernetes中一个非常重要的概念,一个标签就是一个“键-值对”。标签的主要功能是对集群中的各种资源进行多维度的分组管理。本节将详细介绍标签的使用方法。
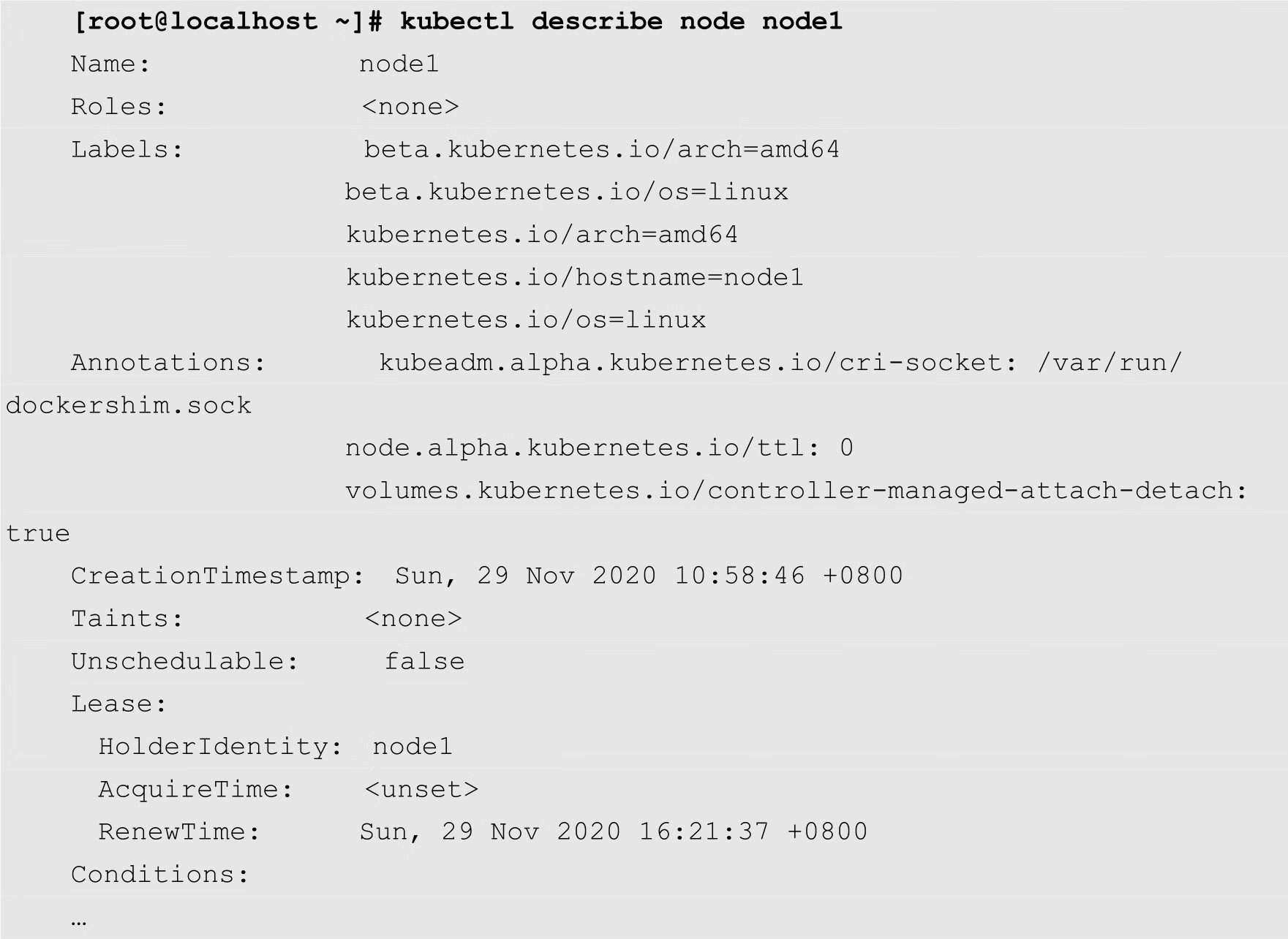
用户可以通过多种方式来查看资源的标签属性。例如,在查看节点的时候,用户可以使用--show-labels选项显示节点的标签,如下所示:

从上面的输出结果可知,一个资源可以拥有多个标签。例如,node1标签就包含beta.kubernetes.io/arch=amd64、beta.kubernetes.io/os=linux、kubernetes.io/arch=amd64、kubernetes.io/hostname=node1以及kubernetes.io/os=linux等5个标签。每个标签都是一个“键-值对”,等号前面的为键(K),等号后面的为值(Value)。
在使用kube describe命令查看资源信息的时候,也可以显示标签,如下所示:
用户可以使用kubectl label命令非常方便地为资源添加各种自定义标签。该命令的基本语法如下:
kubectl label [options]
其中常用的选项有--all和--overwrite等。下面以具体的例子来说明该命令的使用方法。
下面的命令为名称为kube-proxy-zc9q8的Pod设置一个标签,用来标识该Pod的状态,如下所示:

其中pods表示当前设置的资源类型为Pod,kube-proxy-zc9q8为资源的名称,unhealthy=true为要添加的标签,-n选项用来指定资源所在的命名空间。当所要设置的资源不在当前默认的命名空间中时,需要通过-n选项指定。
设置成功之后,用户就可以使用该标签来对资源进行筛选,如下所示:

在上面的命令中,-all-namespaces选项表示显示所有的命名空间的资源。-l选项表示通过标签对资源进行筛选,随后紧跟的就是标签。
以下命令对当前命名空间中所有的Pod设置标签:
[root@localhost ~]# kubectl label pods --all status=unhealthy
其中--all选项表示某个特定的命名空间中所有的指定类型的资源。
如果用户想要修改资源的标签,需要使用--overwrite选项,否则,会出现标签值已经存在的错误,导致标签修改失败。例如,下面的命令将名为kube-proxy-zc9q8的Pod的unhealthy标签的值修改为false:

删除资源标签非常简单,只要在标签的后面加上一个“-”即可。例如,假设名为node1的节点有一个名为role的标签,通过以下命令可以将其删除:
[root@localhost ~]# kubectl label node node1 role- node/node1 labeled
注意
“-”符号要紧跟在键的后面,中间不能有空格。
关于命名空间的基本概念,已经在第1章中介绍过了。在Kubernetes集群中,通过自定义命名空间,可以有效地对各种资源对象进行隔离管理。本节将详细介绍命名空间的使用方法。
命名空间的创建方法与其他的资源对象创建方法基本相同。首先编写一个YAML配置文件,然后通过kubectl create命令进行创建。
假设当前集群需要分成两个相互独立的工作区,其中一个区域作为生产环境,用来运行一些正式的服务;另外一个区域作为测试环境,开发人员可以在里面任意地创建和删除各种资源。
为了实现这个需求,我们需要创建两个命名空间,其中一个名称为development,另外一个名称为production。
其中development命名空间的YAML配置文件的名称为namespace-devel.yaml,其代码如下:
01 apiVersion: v1 02 kind: Namespace 03 metadata: 04 name: development
其中第4行通过name指定当前命名空间的名称为development。
production命名空间的YAML配置文件的名称为namespace-prod.yaml,其代码如下:
01 apiVersion: v1 02 kind: Namespace 03 metadata: 04 name: production
然后使用以下命令创建以上2个命名空间:

创建完成之后,可以使用以下命令查看是否创建成功:

从上面的输出结果可知,development和production这2个命名空间已经出现在列表中。除了创建命名空间之外,用户还需要创建2个Context,即上下文环境,这2个Context分别属于上面创建的2个命名空间。命令如下:

其中ctx-dev和ctx-prod分别为2个Context的名称。--namespace选项用来指定Context所属的命名空间。--cluster选项指定集群名称,--user选项为Context所属的用户。为了简化操作,此处分别使用Kubernetes集群本身的名称和用户名。
创建完成之后,用户可以使用以下命令查看当前集群中的Context:

从上面的输出结果可知,当前集群中有3个Context,分别为ctx-dev、ctx-prod和kubernetes-admin@kubernetes,其中current-context表示当前的Context为kubernetes-admin @kubernetes。
每个Context都相当于一个独立的空间。用户可以使用以下命令切换Context:
[root@localhost ~]# kubectl config use-context ctx-dev Switched to context "ctx-dev".
上面的命令将当前的Context设置为ctx-dev,然后再次查看Context:

从上面的输出结果可知,当前的Context已经变成了ctx-dev。
为了演示通过命名空间和Context实现资源对象的隔离,下面在当前的Context中创建一个Deployment,其配置文件如下:
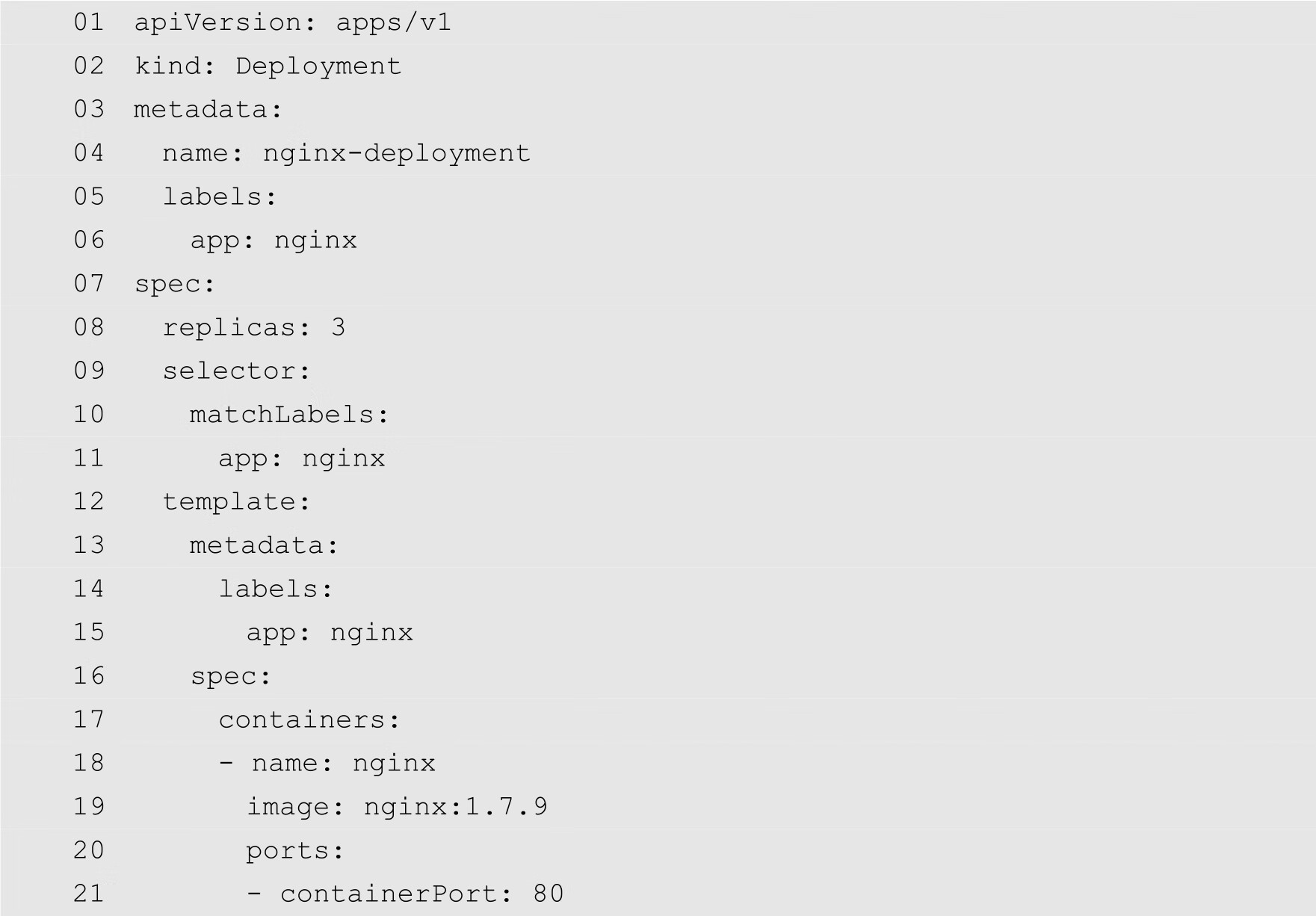
将以上代码保存为nginx-deployment.yaml,然后通过以下命令创建Deployment:
[root@localhost ~]# kubectl apply -f nginx-deployment.yaml deployment.apps/nginx-deployment created
接下来使用以下命令查看当前Context中的Deployment清单:

可以发现刚刚创建的Deployment出现在清单当中。
接下来,使用以下命令切换到名为ctx-prod的Context中,并查看Deployment清单,如下所示:
[root@localhost ~]# kubectl config use-context ctx-prod Switched to context "ctx-prod". [root@localhost ~]# kubectl get deployments No resources found in production namespace.
可以发现,名为production的命名空间中并没有前面创建的Deployment。这说明通过命名空间和Context,已经实现了资源对象的隔离。
命名空间本身也是一种资源。我们可以新建命名空间,而对于不再使用的命名空间,我们需要清理掉。例如,下面的命令将名为production的命名空间从当前的集群中删除:
在Kubernetes中,资源包括多种类型,例如计算资源(CPU、内存和GPU)、存储资源(磁盘和固态硬盘)和网络资源(网络带宽、IP地址以及端口)等。通常情况下,存储资源和网络资源管理起来相对比较容易。但是计算资源的管理,却相对比较复杂。本节将详细介绍如何对Kubernetes中的计算资源进行有效管理,以保证Kubernetes集群的稳定、高效地运行。
在Kubernetes集群中,节点是计算资源的提供者,是对资源的抽象。Pod是计算资源的使用者,是对容器的封装。计算资源通常包括CPU和内存。对于CPU而言,它的基本计算单位为核数;对于内存而言,它的基本计算单位为字节。
当用户创建容器时,可以使用requests和limits这两个属性来分别指定容器所期望得到的CPU和内存的资源量,以及容器所能使用的CPU和内存的资源量的上限。下面分别对这两个属性进行详细介绍。
requests是请求需要使用的计算资源数量,通常情况下,这个资源量也是保证容器能够正常运行的最低资源数量。Kubernetes会保证容器能够使用到requests属性指定的资源数量。因此,请求的资源是Kubernetes进行调度的依据,只有当某个节点上的可用资源大于容器请求的各项资源时,调度器才会把该容器所属的Pod调度到该节点上。
注意
调度器只关心节点上的可分配资源以及容器所请求的资源,而不关心节点上资源的实际使用情况。换句话说,如果节点上的容器申请的资源已经把节点上的资源用满,即使它们的使用率非常低,比如说CPU和内存使用率都低于10%,调度器也不会继续调度Pod到该节点上。
limits是Pod能够使用的资源的上限。通常情况下,requests属性的值应该不大于limits属性指定的值。
requests和limits属性都是可选的。如果只设置了requests属性,则limits属性的默认值被设置为当前节点的资源的最大值;如果只设置了limits属性,则requests属性的默认值被设置为与limits相等的值;如果requests和limits都没有设置,则在创建Pod时,Kubernetes会自动使用集群的默认值。
前面提到过,CPU的基本计算单位是核数,一个核相当于物理服务器的一个超线程内核。也就是通过以下命令查看到的CPU的核数:

例如,用户可以使用整数值1、2以及3等分别表示1个CPU内核、2个CPU内核以及3个CPU内核。除此之外,由于Kubernetes和Docker对计算资源进行了池化和虚拟化,使得用户可以指定非整数个CPU内核。在这种情况下,用户可以使用两种表示方式。首先是可以单独使用一个小数值。例如,用户可以在创建Pod时指定某个容器的CPU核数为0.5,表示使用0.5个CPU内核的计算量。此外,用户还可以使用m作为单位,其中1个CPU内核的计算量等于1000m。例如0.5个CPU内核可以表示为500m。
例如,下面的代码为一个Pod的YAML配置文件:
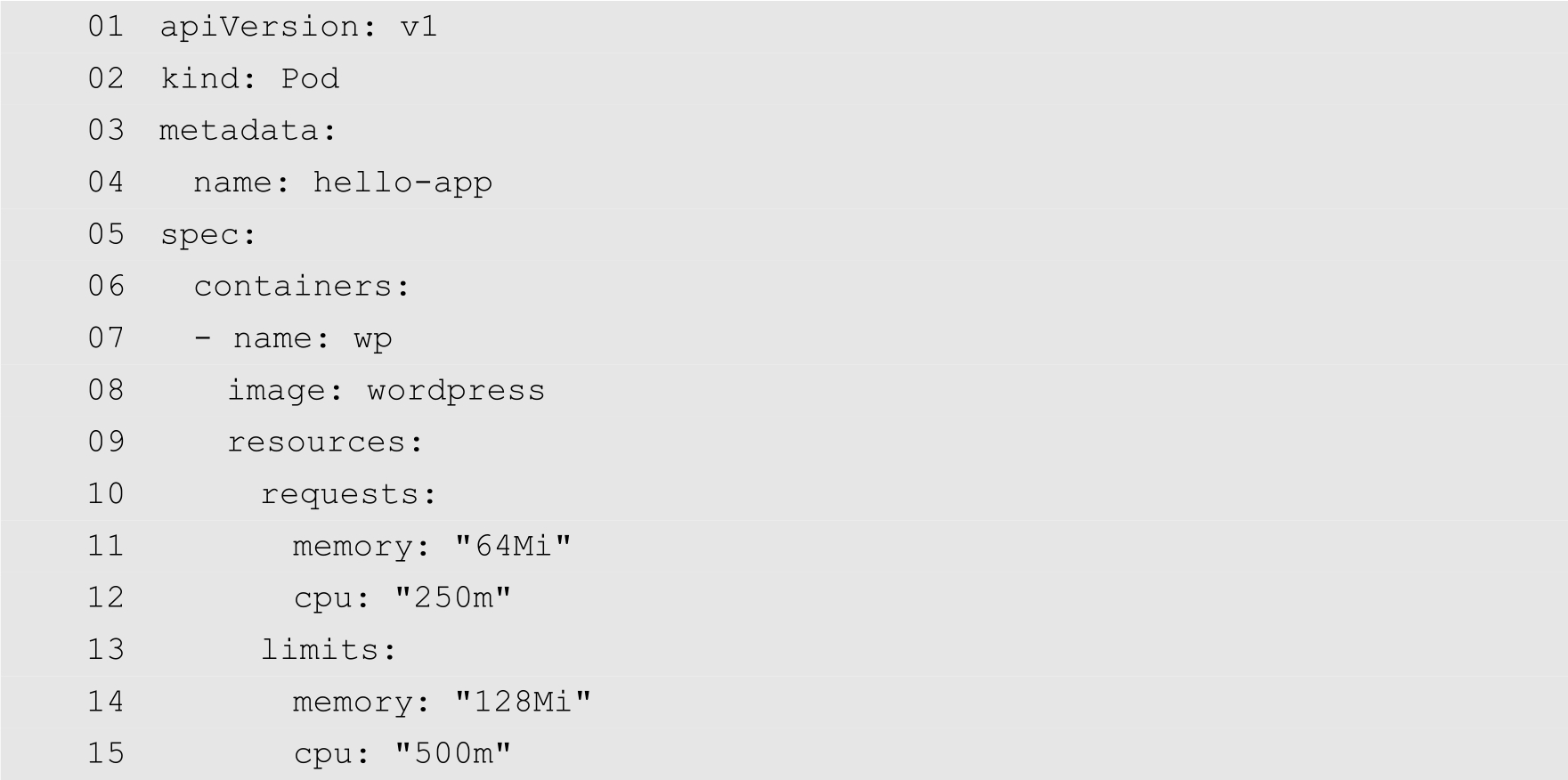
从第9行开始为资源的配置,其中第10~12行为requests属性,第11行指定请求的内存资源为64MB,第12行指定请求的CPU资源为250m,即1/4个CPU内核的计算量。第13~15行为limits属性,其中第14行指定内存的上限为128MB,第15行指定CPU资源的上限为500m,即0.5个CPU内核的计算量。
从上面的介绍可以得知,使用requests和limits这两个属性,用户为每个Pod分配合理的资源数量,从而能够提升整体的资源使用率。但是这个体系有个非常重要的问题需要考虑,那就是怎样准确地评估Pod所需要使用的资源量?如果评估得过低,会导致应用不稳定;如果过高,则会导致使用率降低。这个问题需要开发者和系统管理员共同讨论和设置。
在前面的内容中,我们详细介绍了使用requests和limits这2个属性来对Pod使用的计算资源进行限定。尽管这2个属性使用起来非常方便,但是在维护大量Pod的时候就显得工作量巨大。为了减轻开发人员的工作量,Kubernetes提供了一种名称为LimitRange资源类型。通过LimitRange,可以让用户为某个命名空间配置一个默认的requests和limits值,这样,在绝大部分情况下用户创建Pod时,就可以不用单独指定requests和limits值了。
为了能够使得读者快速地理解LimitRange的创建方法,下面首先看一个简单的例子。

第2行指定所创建的资源的类型为LimitRange。第4行指定LimitRange的名称为devel-limits。从第5行开始为LimitRange的规格描述,其中最重要的是limits。第7行指定当前LimitRange所应用的资源类型为Container,即容器。第8行的max属性指定了命名空间中所有容器的limits属性值的上限。第11行的min属性指定了命名空间中所有容器的requests属性值的下限。第14行default为默认的limits属性值,即如果在创建容器时没有单独指定limits属性值,则采用CPU资源量为500m,内存量为200Mi。第17行的defaultRequest属性指定了所有容器默认的requests的资源量。
将以上文件保存为devel-limits.yaml,然后使用以下命令创建LimitRange资源对象:

其中--namespace选项用来指定LimitRange所在命名空间。在本例中,development命名空间已经在前面创建。
创建完成之后,使用以下命令查看development命名空间中的LimitRange列表:

从上面的代码可以得知,通过LimitRange,可以非常方便地定义容器的计算资源的各项指标。下面对LimitRange的配置方法进行详细介绍。
在LimitRange中,所面向的资源不仅仅是Container,还可以是Pod。因此,type属性可以取Container和Pod这2个值。
在LimitRange的规格描述中,用户可以使用min、max和maxLimitRequestRatio这3个属性。对于Container而言,用户还可以使用defaultRequest和defaultLimit。下面分别介绍这些属性的含义。
对于Container来说,min属性是指特定命名空间中所有容器的requests属性值的下限,max属性是指特定命名空间中所有容器的limits属性值的上限。maxLimitRequestRatio是一个比值,它是limits值和requests值的比值。由于资源调度都是基于requests的值,因此可能会出现资源超售情况,这个比值显示了超售的比例。defaultRequest属性是命名空间中所有的容器的默认的requests的值,如果在创建容器时没有指定requests属性的资源量,则使用defaultRequest的值。defaultLimit是命名空间中所有容器的默认的limits的值,如果在创建容器时没有指定limits的值,则使用默认值。
对于Pod而言,min属性是指Pod中所有容器的requests属性值总和的下限,max属性是指Pod中所有容器的limits属性值总和的上限。maxLimitRequestRatio属性则限制了Pod中所有容器的limits属性值总和与requests属性值总和的比例的上限。
下面通过创建一个Pod来说明如何触发LimitRange的限制,该Pod的YAML配置文件如下:
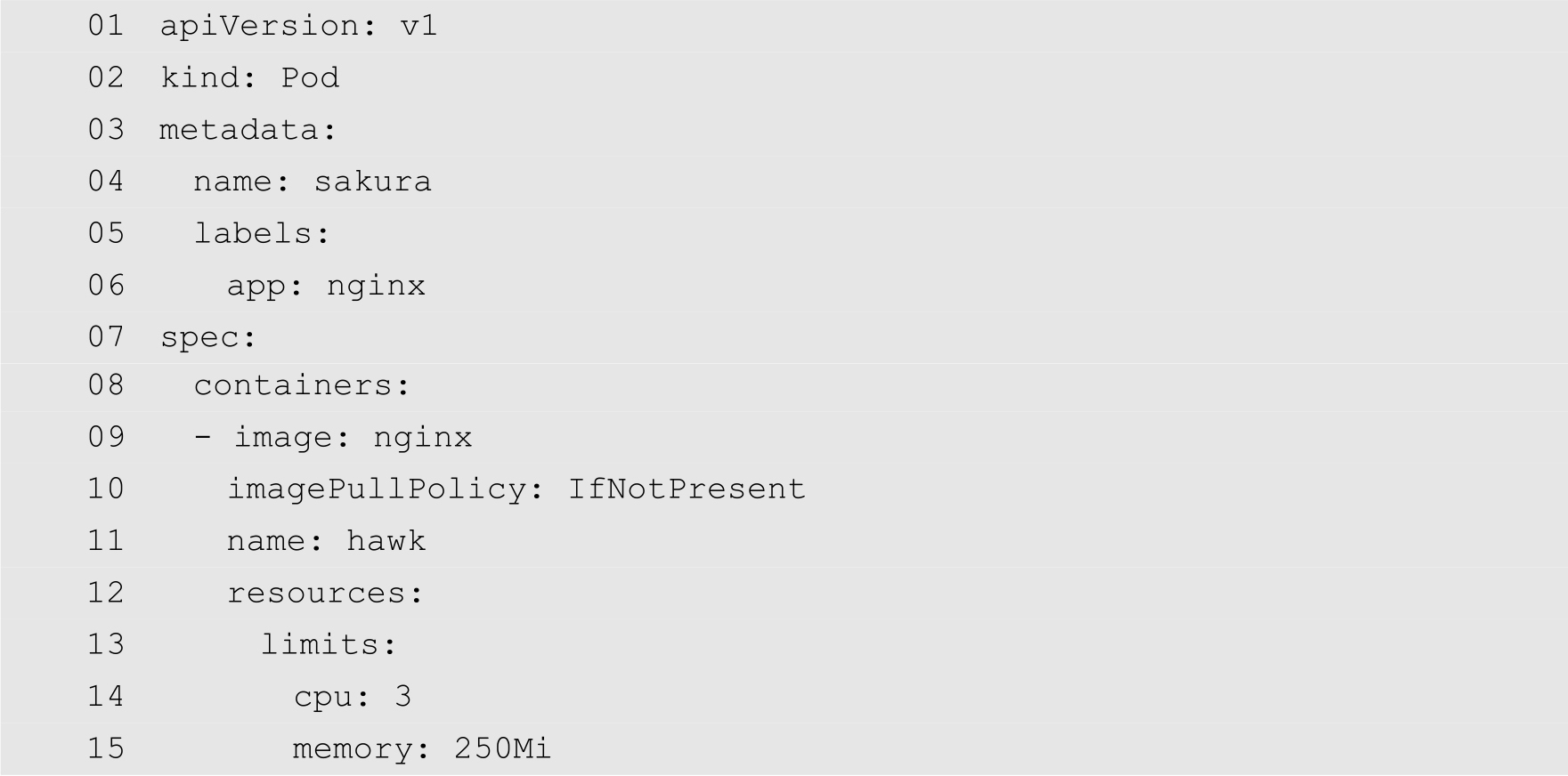
在前面的LimitRange中,指定容器的CPU核数最大为2。为了触发该LimitRange,第14行将新建的容器的CPU核数指定为3。将以上代码保存为invalid-pod.yaml,然后使用以下命令尝试创建该Pod:

很明显,上面的命令执行失败。由于所请求的CPU资源超出了LimitRange的限制,因此Kubernetes禁止用户创建该Pod,这也说明前面创建的名为devel-limits的LimitRange发挥了作用。
前面介绍的方法可以对命名空间中的容器进行资源利用方面的限制。资源配额可以对整个命名空间所能够使用的资源总额度进行限制。这里的资源不仅仅包括CPU、内存等计算资源,还可以包括Kubernetes中的资源对象,例如Pod和服务的数量等。通过资源配额,Kubernetes可以防止某个命名空间下的用户,不加限制地使用超过期望的资源,比如说不对资源进行评估就大量申请高性能的Pod。
下面是一个资源配额的实例,它限制了当前命名空间只能使用少于或者等于20个CPU内核以及不超过1GB的内存,并且最多只能创建10个Pod、20个RC、5个服务:

将以上代码保存为devel-quota.yaml,然后使用以下命令创建:

从上面的输出结果可知,当前命名空间中已经使用了450m的CPU资源,一共可以使用20个CPU内核;内存一共使用了164MB,可以使用1GB;最多可以创建10个Pod,目前已经创建了5个。同样replicationcontrollers和services等也都有限制。
资源配额能够配置的选项还很多,例如GPU、存储、Configmaps、PersistentVolumeClaims等等,更多信息可以参考官方文档。
资源配额要解决的问题和使用方法都相对独立和简单,但是它也有一个限制,那就是它不能根据集群资源动态伸缩。一旦配置之后,资源配额就不会改变,即使集群增加了节点,整体资源增多也没有用。Kubernetes现在没有解决这个问题,但是用户可以通过编写一个Controller的方式来自己实现。
requests和limits的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用,即它决定了Pod的资源服务质量等级。
前面已经介绍过,如果在创建Pod时没有指定limits属性,则该Pod可以使用所在节点上任意多的可用资源。这类Pod能够灵活地使用资源,但这也导致它不稳定且危险。对于这类Pod,用户一定要在它占用过多资源而导致节点资源紧张时将其处理掉。优先处理这类Pod,而不是处理资源使用处于自己请求范围内的Pod。Pod的服务质量控制的含义就是根据Pod的资源请求,把Pod分成不同的重要等级。
Kubernetes把Pod分成了三个服务质量等级:
通常情况下,如果在创建资源时,没有设置requests和limits属性,则资源的服务质量优先级最低,在节点资源紧张的情况下,最容易被优先“杀死”。
前面所介绍的都是理想情况下的Kubernetes工作状况,在理想情况下,Kubernetes集群中的各种资源都是足够用的,并且所有的应用系统都是在使用规定范围内的资源。但是在生产环境中,用户所面临的情况却不会如此简单,而是会经常遇到资源不足的情况。此时,用户需要保证整个集群的可用,并且尽可能减少损失。Kubernetes提供了一种Pod驱逐机制,来满足这种需求。本节将详细介绍Pod驱逐的原理及使用方法。
现实环境中,Pod驱逐机制用于在管理集群的时候常常会遇到资源不足的情况。在这种情况下,用户最大的任务首先就是要保证整个集群处于可用状态,然后就是尽可能减少应用的损失。保证集群可用比较容易理解,首先要保证系统层面的核心进程正常,其次要保证Kubernetes本身组件进程不出问题。至于减少应用的损失,最常用的方法就是尽量“杀死”不重要的应用,让重要的应用不受影响,即Pod驱逐。当然,这涉及Pod的优先级问题。
Pod的驱逐是在kubelet中实现的,因为kubelet能动态地感知到节点上资源使用率的实时变化情况。一旦发现某个不可压缩资源出现要耗尽的情况,就会主动终止节点上的Pod,让节点能够正常运行。被终止的Pod中的所有容器会停止,状态会被设置为Failed。
那么,哪些资源不足会导致kubelet执行Pod驱逐呢?目前主要有三种情况,分别是实际内存不足、节点文件系统的可用空间不足,以及镜像文件系统的可用空间不足。在Kubernetes中,这些称为驱逐信号,分别使用memory.avaliable、nodefs.avaliable、nodefs.inodesFree、imagefs.avaliable以及imagefs.inodesFree表示。
有了数据的来源,另外一个问题是Pod驱逐触发的时机,也就是到什么程度需要触发Pod驱逐。Kubernetes支持两种模式,分别为按照百分比和按照绝对数量。例如,对于一个拥有32G内存的节点,当可用内存少于10%时启动驱逐程序,可以配置memory.available<10%或者memory.available<3.2Gi。前者为百分比表示,后者为绝对数量表示。
注意
默认情况下,kubelet的驱逐规则是memory.available<100Mi,对于生产环境来说,这个配置是不可接受的,所以一定要根据实际情况进行修改。
通过前面的介绍可以得知,尽管Pod驱逐保证了重要应用的正常运行,但是对于被标记为不重要的应用来说,这是一种具有毁灭性的行为,因此,在使用的时候必须谨慎。有时候内存使用率增高只是暂时性的,有可能20s就能恢复,这时候启动Pod驱逐程序意义不大,而且可能会导致应用的不稳定,用户需要考虑到这种情况应该如何处理。有的时候内存使用率过高,比如高于95%,那么我们不应该再多作评估和考虑,而是赶紧启动Pod驱逐程序,因为这种情况再花费时间去判断,可能会导致内存继续增长,系统完全崩溃。
为了解决这个问题,Kubernetes引入了软驱逐和硬驱逐的概念。
软驱逐可以在资源紧缺,但没有发展到非常严重的时候触发,例如内存使用率为85%。软驱逐在触发以后不会立即驱逐Pod,而是继续观察一段时间,如果资源使用率高于阈值的情况持续一定时间,才开始驱逐。并且驱逐Pod的时候,也不会立即“杀死”Pod,而是预留一定的时间让Pod完成清理工作,自己停止。如果超过指定的时间,Pod还没有自动终止,才会主动“杀死”Pod。
和软驱逐相关的启动参数是:
前面两个参数必须同时配置,软驱逐才能正常工作。后一个参数会和Pod本身配置的等待时间比较,选择较小的一个生效。
硬驱逐则比较简单,当kubelet发现节点达到配置的硬驱逐阈值后,立即开始驱逐程序,并且不会等待Pod完成清理工作,也就是说立即强制“杀死”Pod。因此,硬驱逐仅仅用在非常紧急的情况下。其对应的配置参数只有一个--evictio-hard。
设置这两种驱逐机制是为了平衡节点稳定性和对Pod的影响,软驱逐照顾到了Pod的优雅退出,减少驱逐对Pod的影响;而硬驱逐则照顾到节点的稳定性,防止资源的快速消耗导致节点不可用。
软驱逐和硬驱逐可以单独配置,不过还是推荐两者都进行配置,一起使用。
前面已经介绍过,Pod驱逐的重要原则是尽量减少对应用程序的影响。如果是存储资源不足,kubelet会根据情况清理状态为Dead的Pod和它的所有容器,以及清理所有没有使用的镜像。如果上述清理并没有让节点恢复正常,那么kubelet就开始清理Pod。
通常情况下,系统组件的Pod要比普通的Pod更重要,另外运行数据库的Pod自然要比运行一个无状态应用的Pod更重要。kubelet会根据Pod的requests和limits、优先级、以及Pod实际的资源使用情况来判断Pod的驱逐优先级。
简单来说,kubelet会根据以下标准对Pod进行排序:Pod是否使用了超过请求的紧张资源、Pod的优先级,以及使用的紧缺资源和请求的紧张资源之间的比例。
Kubernetes的Pod驱逐波动有两种情况,下面分别进行介绍。
首先第一种情况是在驱逐条件发出之后,如果kubelet驱逐一部分Pod,让资源使用率低于阈值就停止,那么很可能过一段时间资源使用率又会达到阈值,从而再次发出驱逐,如此循环往复。对于这个问题,用户可以使用--eviction-minimum-reclaim选项来解决,这个参数配置每次驱逐至少要清理出来多少资源才会停止。通过这个选项,可以在驱逐时为节点的各种资源预留一定的增长空间,避免频繁地触发Pod驱逐。
另外一种波动情况就是Pod被驱逐之后并不会从此消失不见,常见的情况是Kubernetes会自动生成一个新的Pod来取代,并经过调度选择一个节点继续运行。如果不做额外地处理,Kubernetes将新的Pod调度到原来节点的可能性比较大。如果被驱逐的Pod再次调度到原来的节点,很可能会再次触发驱逐程序,然后Pod再次被调度到当前节点,循环往复。对于这种情况,Kubernetes的解决方法是发生Pod驱逐之后,kubelet立即更新节点的状态,调度器感知到这一情况,暂时不往该节点调度Pod即可。用户可以使用--eviction-pressure-transition-period参数来指定kubelet多久才上报节点的状态,因为默认的上报状态周期比较短,频繁更改节点状态会导致驱逐波动。
在生产环境中,管理员必须保证Kubernetes集群运行的稳定性,避免由于Kubernetes集群故障而导致业务方面的巨大损失。Kubernetes集群的高可用性有多种实现方法,其中使用kubeadmin工具部署是最简洁的一种方式。本节将详细介绍如何使用kubeadmin工具实现Kubernetes集群的高可用性。
在Kubernetes集群中主要有两种节点,分别为Master节点和工作节点(Node)。其中Master节点为管理节点,管理整个Kubernetes集群,接收外部命令,维护集群状态。如果Master节点出现故障,则整个集群会失去控制。在Master节点上面,运行的主要服务有apiserver、etcd、scheduler以及controller-manager。工作节点(Node节点),主要执行计算任务,运行的主要服务有kubelet和kube-proxy。当工作节点出现故障,Kubernetes会将Pod调度到其他的工作节点上,并不会影响整个集群的运行,甚至对应用系统的影响也非常小。因此,Kubernetes集群的高可用主要是指Master节点的高可用。
在Master节点中,apiserver的功能是作为API服务器,所有外部与Kubernetes集群的交互都需要经过它。apiserver可以同时存在多个,并且通过负载均衡器实现高可用性。etcd本身是一个高可用的分布式“键-值”存储系统,可以实现集群。scheduler的功能是将Pod调度到具体的工作节点上,而controller-manager的功能是执行控制器逻辑,通过apiserver监控集群状态,做出相应的处理。scheduler和controller-manager这两个服务在一个Kubernetes集群中只会有一个处于激活状态。如果存在着多个Master节点,则它们会依据相应的算法选举产生处于激活状态的节点。
etcd的部署方式主要有两种,其中一种为堆叠式的etcd集群,在这种方式中,etcd分布式数据存储集群堆叠在Master节点中。另外一种为外部式,此时,etcd独立于Master节点。图10-1所示显示了堆叠式的etcd集群方案。
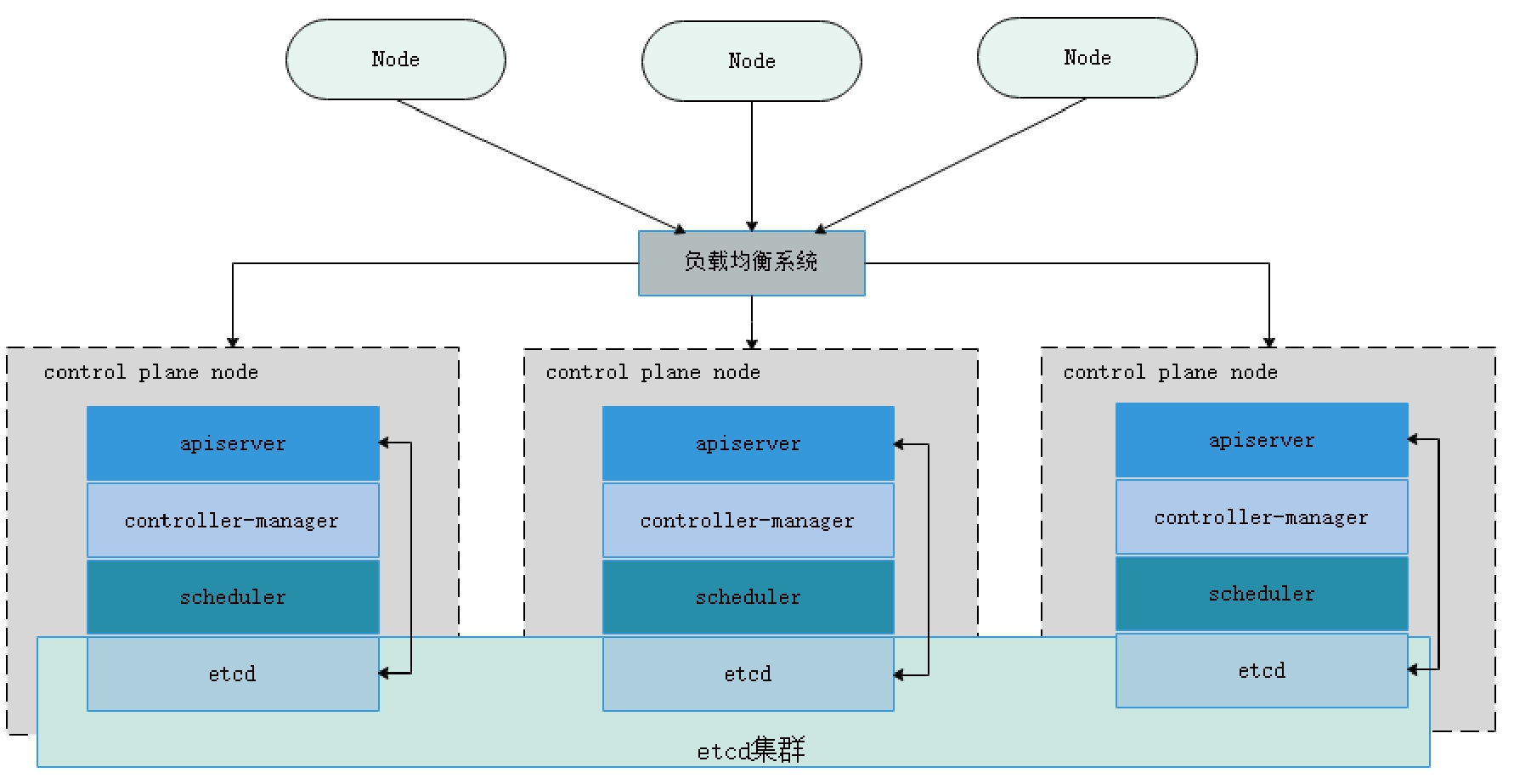
图10-1 堆叠式etcd集群
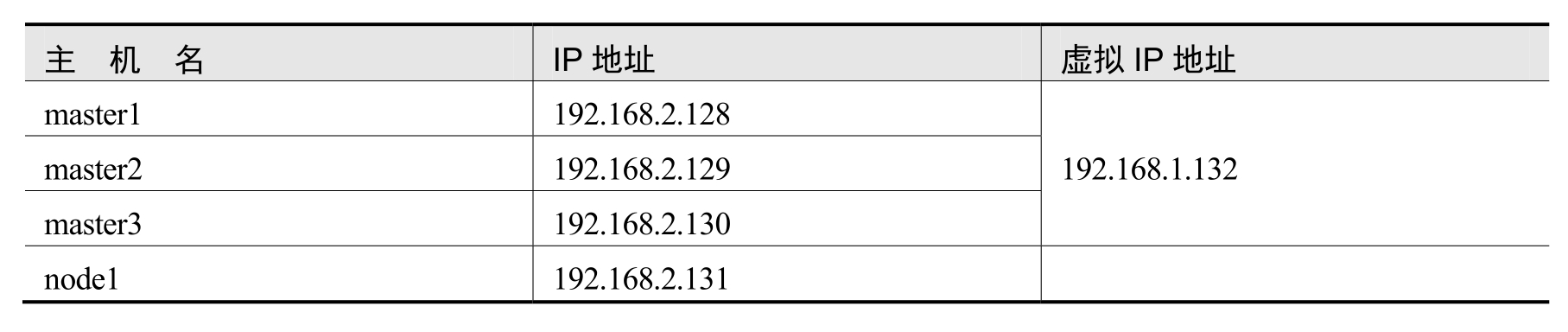
在生产环境中,无论是Master节点,还是工作节点(Node节点),通常都是物理服务器。在本例中,为了便于演示,使用VirtualBox虚拟机软件创建了4个虚拟机。这4个虚拟机的内存都是2GB,虚拟CPU为2个,网络连接方式为桥接网卡,安装的操作系统都是CentOS 8。表10-1列出了这4台虚拟机IP地址的分配情况。
表10-1 虚拟机IP地址分配
为了能够顺利部署Kubernetes,用户还需要做一些配置工作,下面分步进行介绍,以下步骤需要在所有的虚拟机上面完成操作。
(1)配置CentOS软件源。为了提高安装速度,用户需要将CentOS默认的软件源,修改为阿里镜像的软件源。
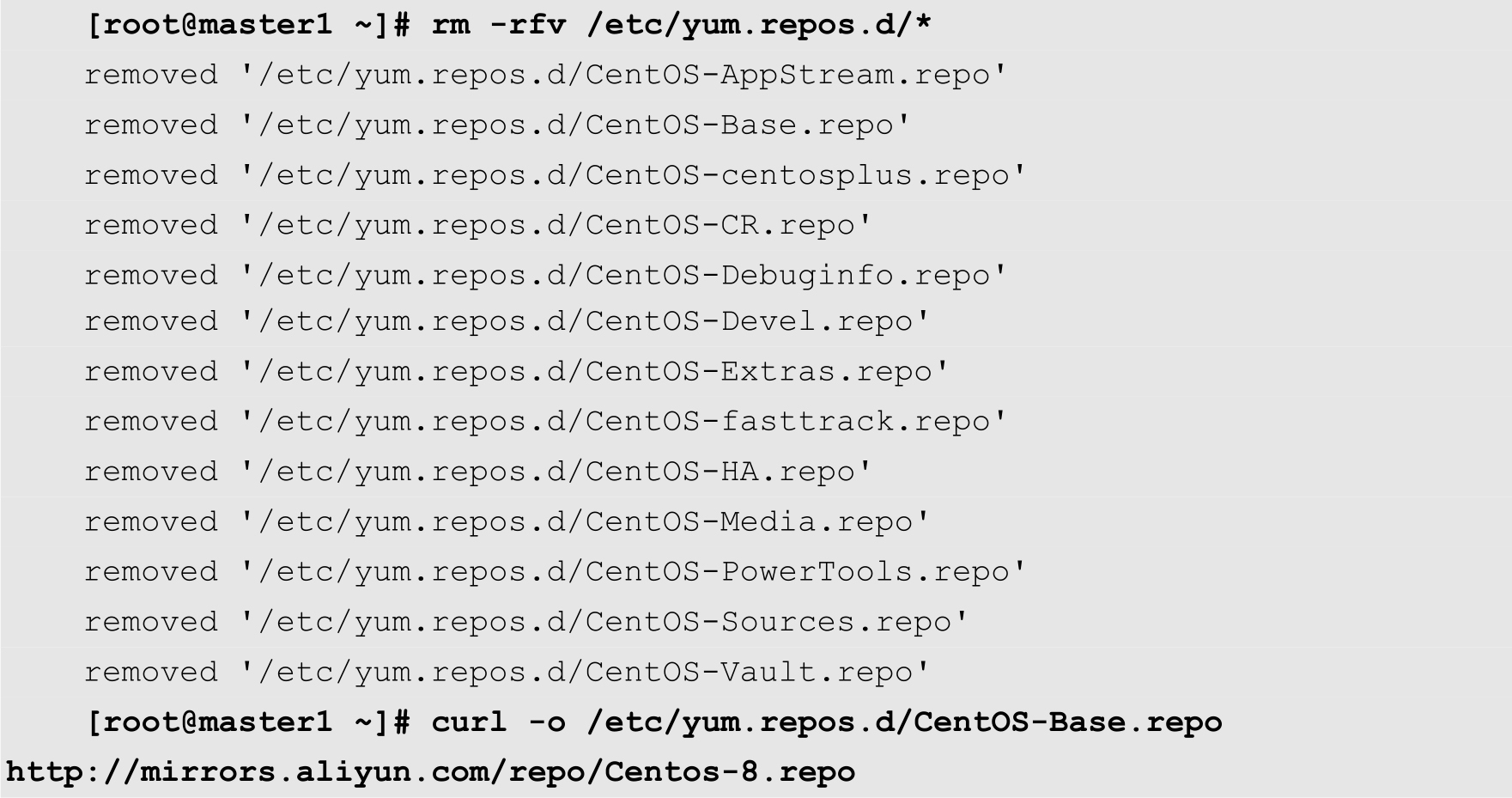
curl命令的功能是将远程的软件源配置文件下载到本地的指定目录。
(2)配置主机名。为了能够正确解析主机名,用户需要在/etc/hosts文件中进行相应的配置,增加以下代码:

(3)关闭交换分区,并且在/etc/fstab文件中删除交换分区的配置。
首先执行以下命令关闭交换分区:
[root@master1 ~]# swapoff -a
然后打开/etc/fstab文件,找到以下代码,将该行的前面添加注释符号:

(4)配置内核参数,将桥接的IPv4流量传递到iptables的链,命令如下:

然后执行以下命令使得上面的配置生效:
(5)禁用SELinux。
首先执行以下命令禁用SELinux:
[root@master1 ~]# setenforce 0
然后修改/etc/selinux/config文件,将其中的SELINUX选项的值设置为disabled,代码如下:
SELINUX=disabled
(6)关闭防火墙,命令如下:
[root@master1 ~]# systemctl stop firewalld [root@master1 ~]# systemctl disable firewalld
(7)安装所需要的软件包,命令如下:
[root@master1 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
接下来,再详细介绍master1节点的安装步骤。用户需要在master1、master2和master3这3个Master节点上面执行以下步骤。
(1)添加Docker CE阿里镜像软件源,命令如下:

(2)安装Docker CE,命令如下:
[root@master1 ~]# yum -y install docker-ce
如果在安装的时候出现以下错误,请升级containerd.io为1.44.1以上。
Problem: package docker-ce-3:20.10.0-3.el7.x86_64 requires containerd.io >= 1.4.1, but none of the providers can be installed
成功安装Docker CE之后,启用并启动该服务,命令如下:

(3)安装kubectl、kubelet、kubeadm。
为了加快安装速度,需要添加阿里的Kubernetes镜像软件源,命令如下:
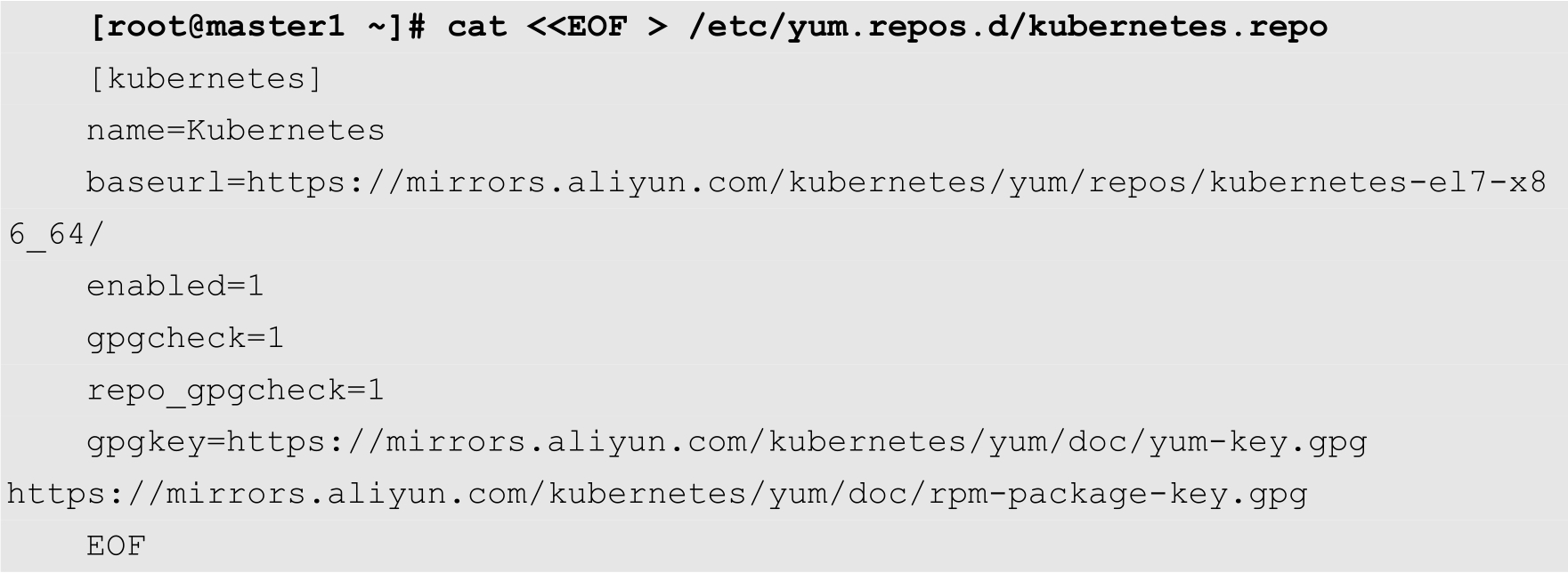
然后安装Kubernetes相关组件,命令如下:
[root@master1 ~]# yum install kubectl kubelet kubeadm -y
启用kubelet,命令如下:

haproxy是一个高性能的负载均衡系统。在本例中,通过haproxy实现3个apiserver的负载均衡。以下操作分别在master1、master2和master3上进行。
(1)安装haproxy,命令如下:
[root@master1 ~]# yum -y install haproxy
(2)修改配置文件。修改haproxy的配置文件/etc/haproxy/haproxy.cfg,代码如下:



第26行指定了haproxy统计平台的账号和密码都是admin。第30行开始指定haproxy的前端配置选项,包括监听的端口、工作模式以及默认的后端服务器。第36行开始配置haproxy的后端选项,其中从42行开始分别指定前面配置的3个Master节点。
(3)启动并启用haproxy,命令如下:
[root@master1 haproxy]# systemctl start haproxy [root@master1 haproxy]# systemctl enable haproxy
keepalived是一个非常流行的服务器高可用解决方案。在本例中,通过keepalived实现apiserver的故障转移。
keepalived的安装方法如下:
[root@master1 haproxy]# yum -y install keepalived
修改keepalived的主配置文件/etc/keepalived/keepalived.conf,代码如下:

第7行配置了一个名称为check_apiserver.sh的脚本文件,该文件的功能是定期检查apiserver的进程是否存在。第16行指定服务的网络接口为enp0s3,用户需要根据自己的实际情况进行修改。第23行配置了一个虚拟IP地址,该虚拟IP地址将作为3个apiserver对外服务的IP地址。
接下来编写/etc/keepalived/check_apiserver.sh脚本文件,代码如下:

其中的192.168.1.7即为keepalived的虚拟IP地址。授予所有用户执行check_apiserver.sh的权限,命令如下:
[root@master2 ~]# chmod +x /etc/keepalived/check_apiserver.sh
然后启动并启用keepalived,命令如下:
[root@master2 ~]# systemctl enable keepalived [root@master2 ~]# systemctl start keepalived
当haproxy配置完成之后,用户就可以通过浏览器访问统计报告页面,网址如下:
http://192.168.1.7:1080/haproxy-status
其中192.168.1.7为keepalived的虚拟IP地址,服务端口1080即haproxy.cfg配置文件中配置的监听端口。用户名和密码都是admin,这个是在haproxy.cfg配置文件中的第26行指定的,用户可以根据自己的实际情况进行修改。
haproxy的统计报告如图10-2所示。
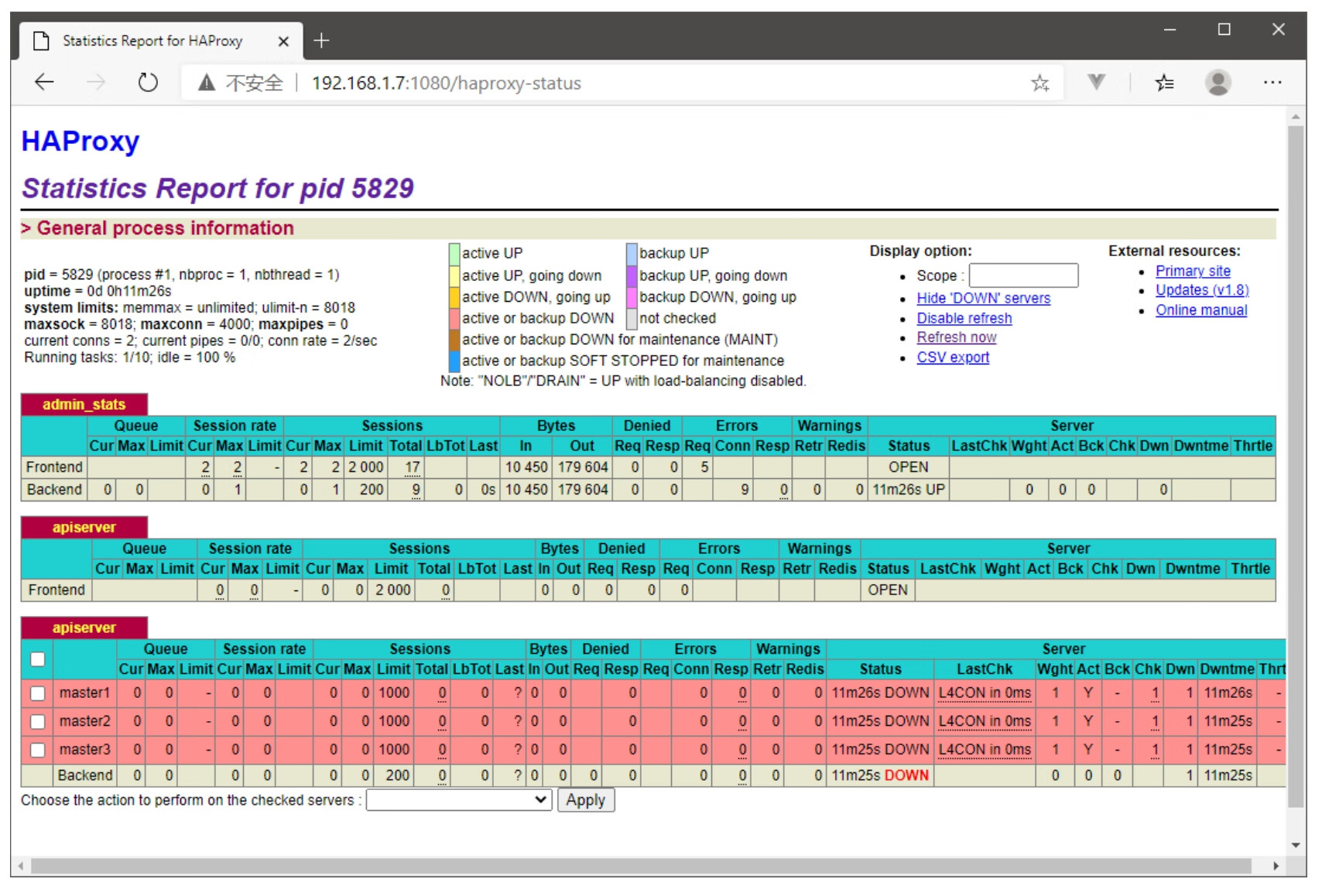
图10-2 haproxy统计报告
从图10-2可以看出,目前3个Master节点都是红色的,其状态为DOWN,这是因为我们目前还没有初始化Master节点。等初始化完成之后,这3个Master节点会变成绿色。
接下来进行Master节点的初始化操作,需要特别注意,只需要初始化一个Master节点就可以了,其余的Master节点是通过kubeadm join命令加入的。
master1的初始化命令如下:
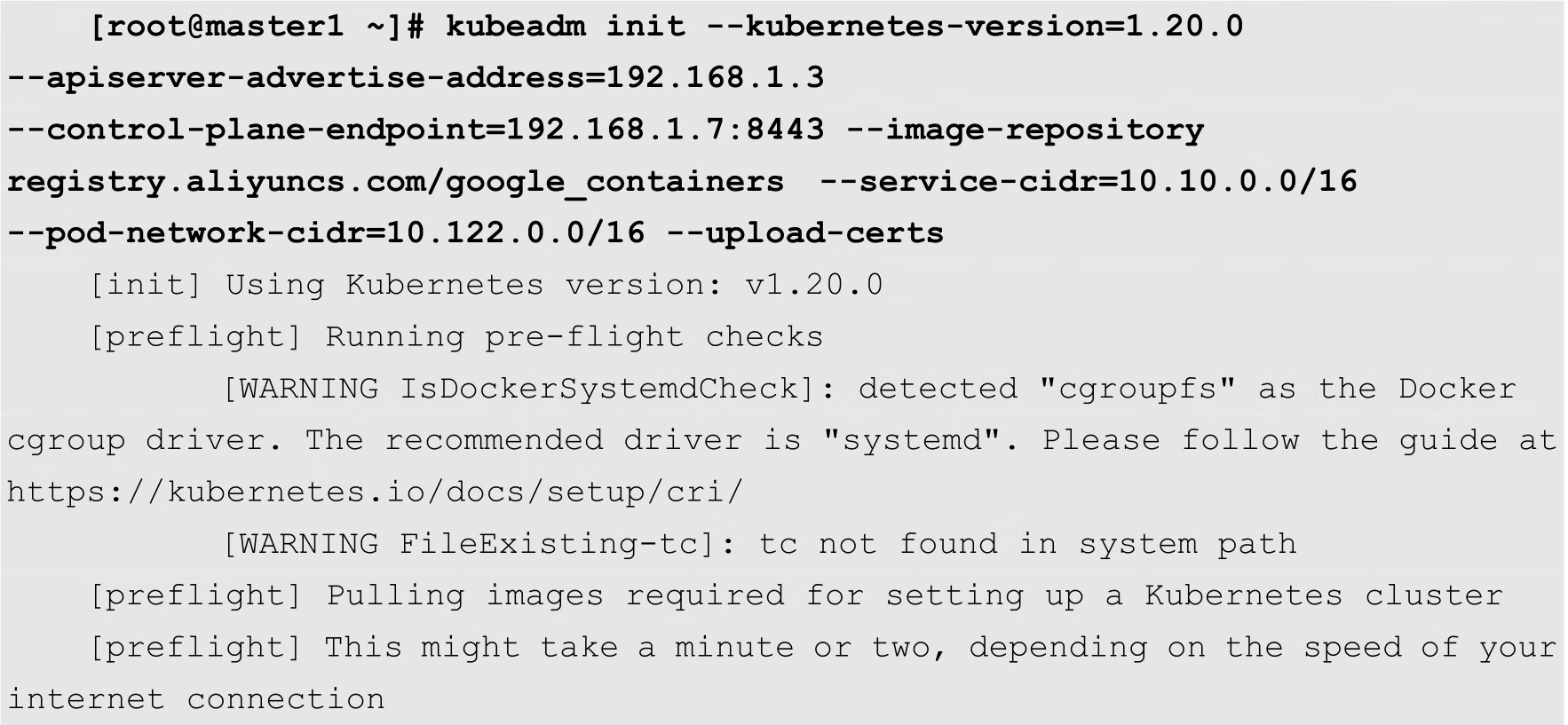


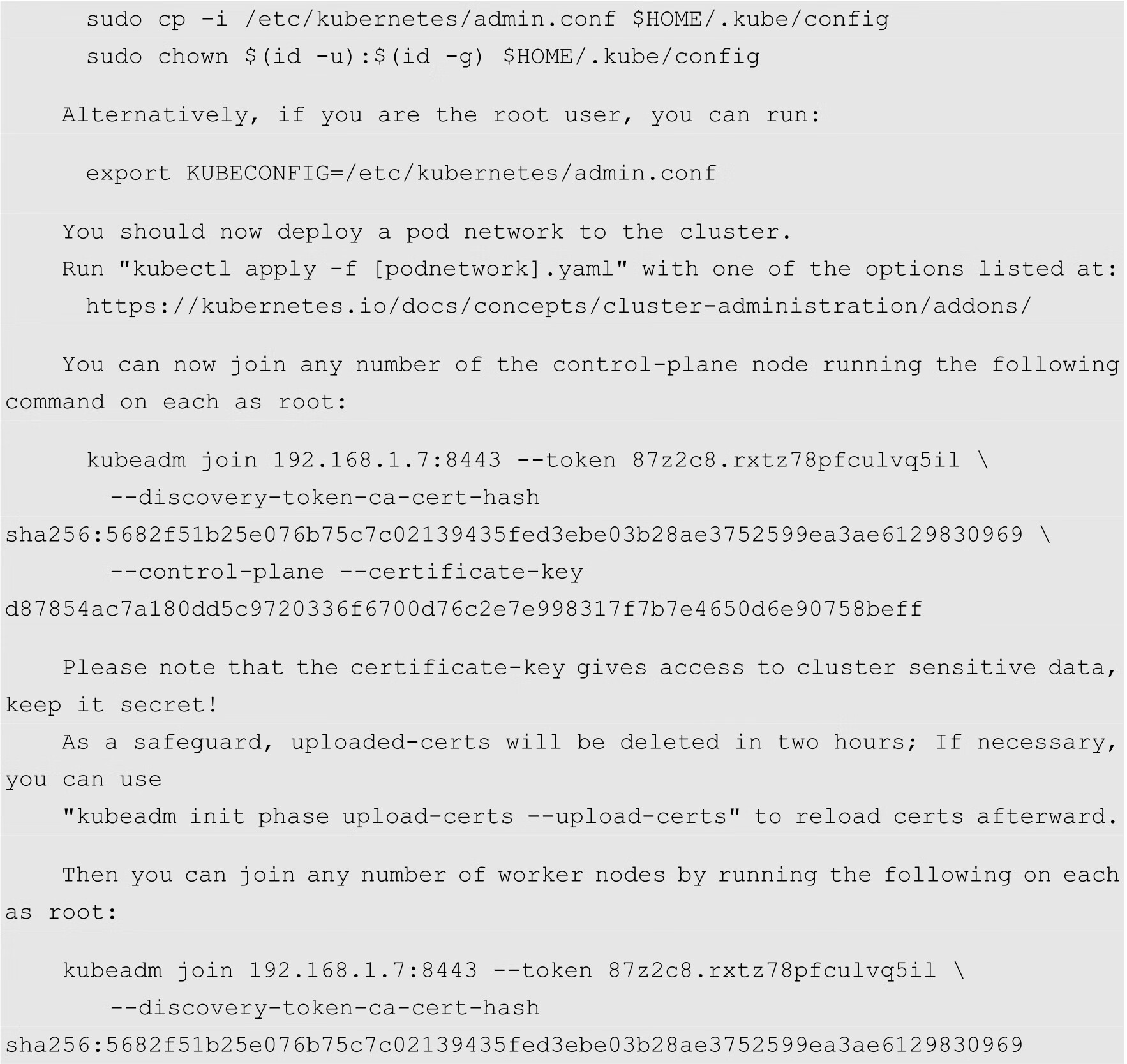
其中--apiserver-advertise-address选项用来指定本机的IP地址,--control-plane-endpoint选项用来指定Master节点控制层的服务地址和端口,实际上就是keepalived中配置的虚拟IP,端口8443为haproxy.cfg配置文件中配置的前端服务的端口。
初始化成功之后,用户需要留意后面的提示信息,例如用户环境变量的配置以及加入集群的命令。需要注意的是后面有2条kubeadm join命令,其中一条为其他Master节点加入到控制层的命令,另外一条为工作节点加入到集群的命令。
初始化完成之后,查看当前集群中的Pod,命令如下:

从上面的输出结果可知,除了coredns之外,其余的Pod都已经处于运行状态。这是由于还没有安装网络组件,等网络组件安装完成之后,coredns就正常了。
Kubernetes的网络组件非常多,其中比较常用的有Flannel和Calico。而Calico是目前稳定性较好,性能也非常高的一种网络组件。因此,在本例中使用Calico来进行讲解。以下操作只要在master1这个Master节点上进行就可以了,不需要在每个Master节点上执行。安装Calico的命令如下:
[root@master1 ~]# kubectl apply -f https://docs.projectcalico.org/ manifests/calico.yaml
安装完成之后,再查看Pod状态,如下所示:

可以发现,目前所有的组件都已经处于运行状态。
到目前为止,Kubernetes集群中已经有了一个Master节点,其余的Master节点还没有加入到控制层。下面将master2和master3这2个Master节点也加入到Master节点的控制层中。以下操作分别在master2和master3上面执行,其中master2节点的命令如下:

master3节点的命令如下:

等待命令执行完成之后,再次查看集群中的Pod状态,如下所示:

可以发现,apiserver、controller-manager、etcd以及scheduler等重要组件都已经有3个节点在运行。
此时,在haproxy的统计报告界面,可以发现3个Master节点都已经变成绿色了,如图10-3所示。
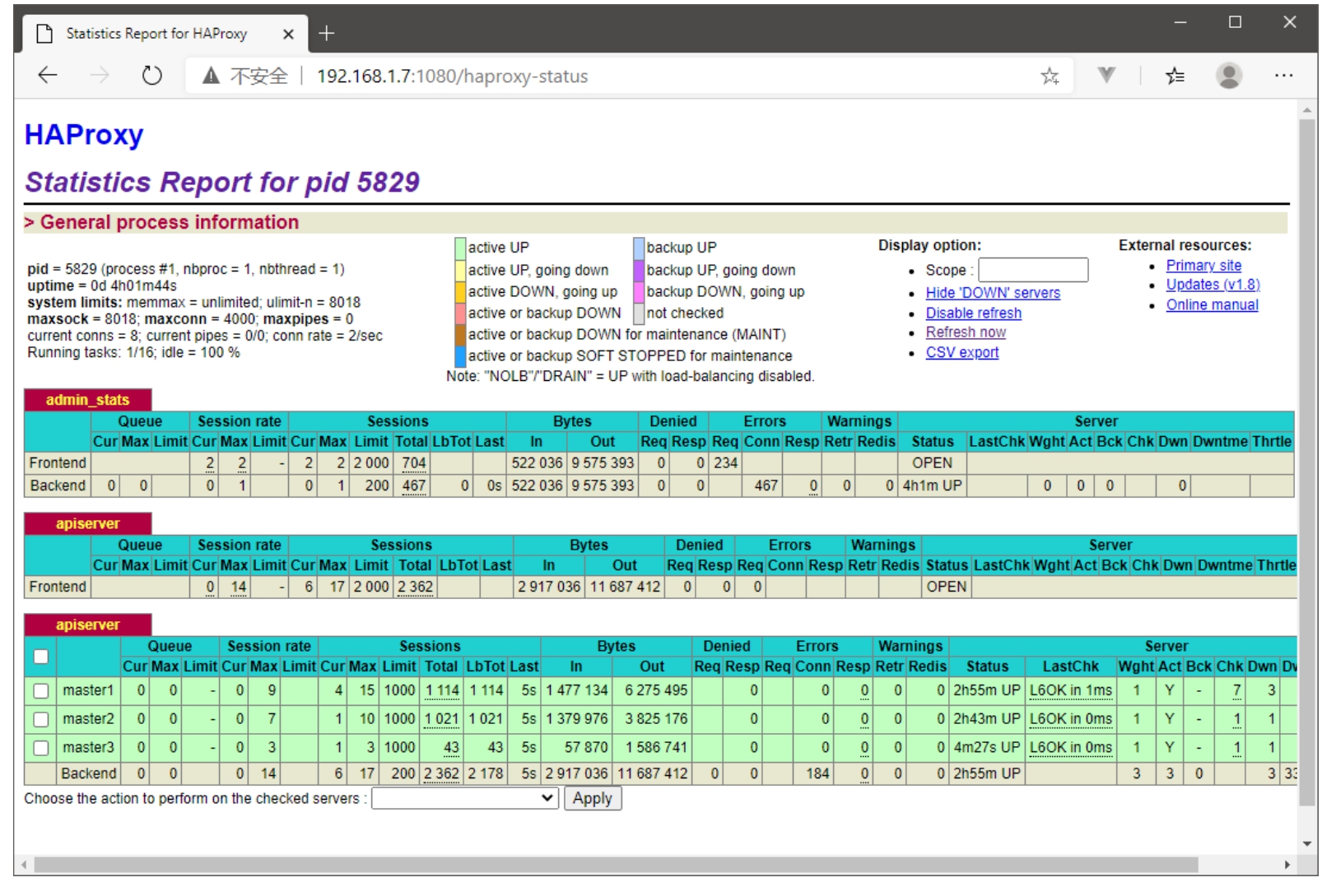
图10-3 通过haproxy统计页面查看Master节点状态
工作节点的加入比较简单,在所有的安装环境中将kubectl、kubelet和kubeadm等组件都安装完成之后,使用在初始化master0时系统给出的命令即可。在本例中,加入命令为:

当以上命令执行完成之后,在任何一个Master节点上面都可以使用以下命令查看当前集群中的工作节点列表:

从上面的输出结果可知,node1已经处于Ready(就绪)状态了。