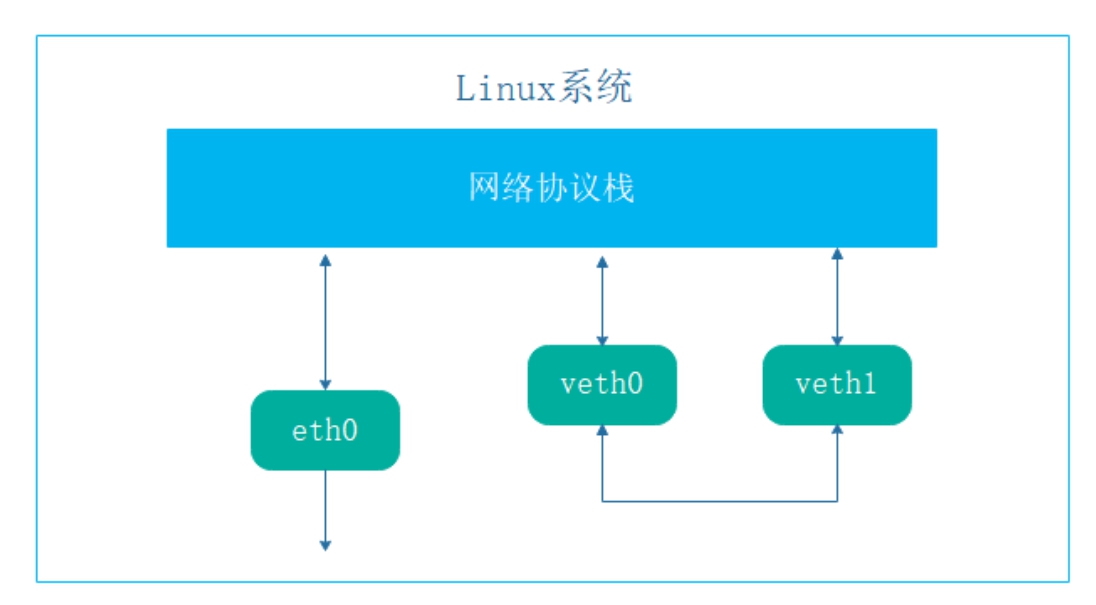
图8-1 veth网络接口
Kubernetes时代的到来,绕不开网络这个话题,网络的基础就是通信。网络之间如何通信、有哪些接口、可选的方案有几种?这些问题将在本章说明。除此之外,读者还需要了解一些Linux中的网络专属词汇,这都是Kubernetes网络管理的基础。
本章涉及的知识点有:
Kubernetes集群的主要功能是提供各种网络服务。前面的第7章和第8章中,读者已经初步接触到了Kubernetes的网络设置,本节将详细介绍Kubernetes的网络基础知识。
在Kubernetes中,IP地址的分配是以Pod为单位进行分配的,即每个Pod都有一个独立的IP地址。而在同一个Pod内部,不管有多少个容器,都共享同一个网络命名空间,即IP地址、网络设备以及各项网络配置都是共享的。因此,Kubernetes的网络模型被称为IP-per-Pod。总的说来,Kubernetes的网络模型符合以下规则:
(1)在集群中,每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中,不管是否运行在同一节点上,都可以通过Pod的IP来访问。
(2)Kubernetes中Pod的IP分配是以Pod为单位进行的,同一个Pod内所有的容器共享一个网络堆栈,该模型称为IP-per-Pod模型。
(3)从端口分配、域名解析、服务发现、负载均衡以及应用配置等角度看,Pod都可以看作是一台独立的虚拟机或者物理机。
(4)所有的容器都可以直接同别的容器通信,而不用通过NAT。
在Kubernetes的网络模型中,有以下几个概念非常重要。
命名空间是Linux系统中用来隔离资源的一种方式。如果把Linux操作系统比作一个大房子,那命名空间指的就是这个房子中的一个个小房间,住在每个房间里的人都自以为独享了整个房子的资源,但其实大家仅仅只是在共享的基础之上互相隔离。共享指的是共享全局的资源,而隔离指的是局部上彼此保持隔离,因而命名空间的本质就是指一种在空间上隔离的概念。当下流行的许多容器虚拟化技术,例如Docker,就是基于Linux命名空间的概念而来的。
网络命名空间用来隔离各种网络资源,例如IP地址、路由、网络接口等。后台进程可以运行在不同命名空间内的相同端口上。每个网络命名空间都有自己的路由表,它通过自己的iptables配置提供NAT和过滤的功能。Linux网络命名空间还提供了在网络命名空间内运行进程的功能。
veth就是虚拟以太网设备,它都是成对出现的,一端连着网络协议栈,一端彼此相互连接着,如图8-1所示。
图8-1 veth网络接口
正因为有这个特性,veth常常充当着一个桥梁,连接着各种虚拟网络设备。其中,最常见的情况就是连接两个命名空间(或者容器)等。
在Linux系统中,管理员可以通过ip命令来查看当前系统中的veth,如下所示:
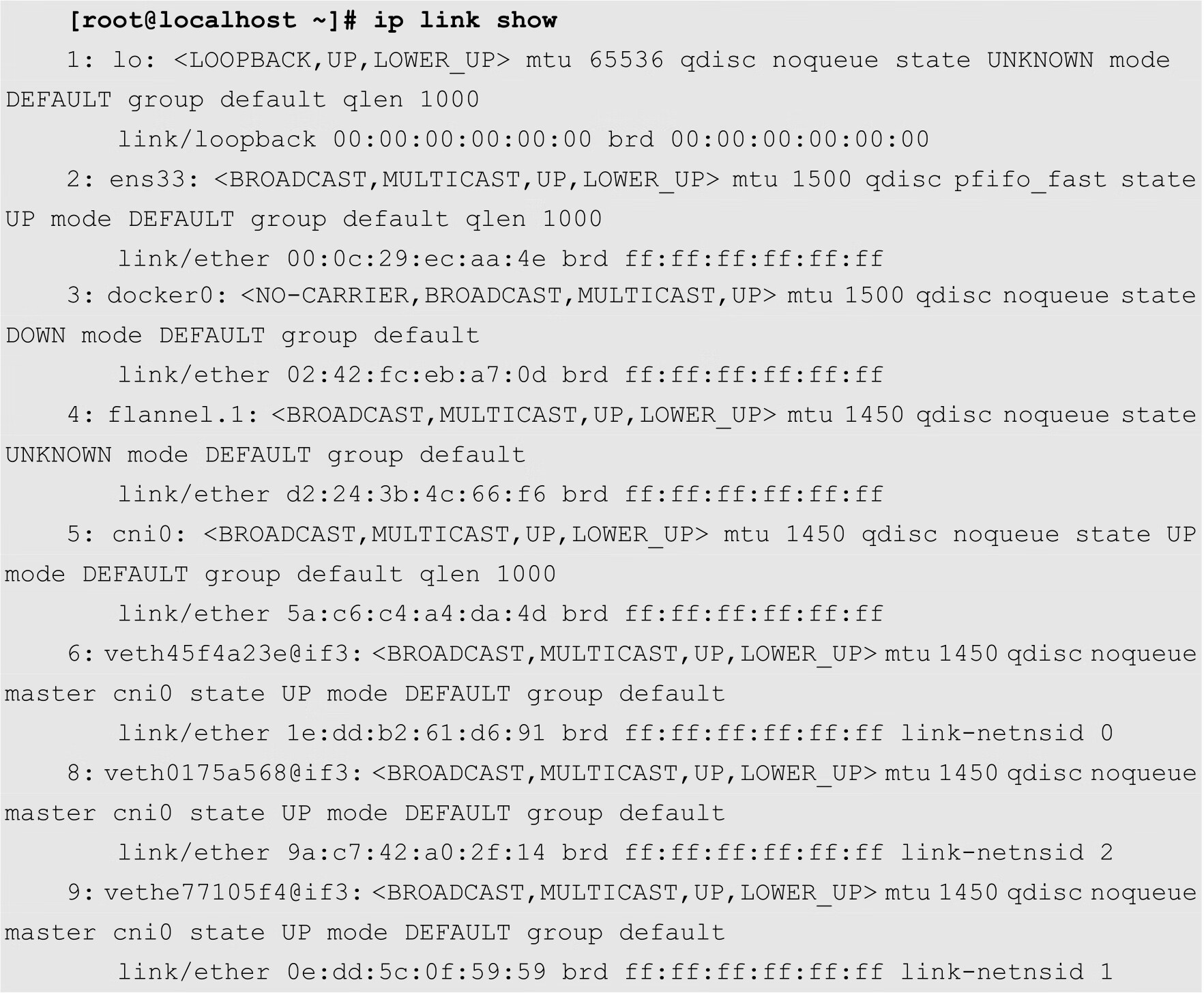
在上面的输出中,编号为6、8和9的网络设备即veth。
netfilter负责在内核中执行各种数据包过滤规则,运行在内核模式中。iptables是在用户模式下运行的进程,负责协助维护一系列数据包过滤规则表,通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
网桥是一个二层网络设备,通过网桥可以将Linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。在CentOS中,用户可以通过ip route命令查看当前相同的路由表,如下所示:

其中,第2条规则的意思是所有docker0接口上收到的、发往172.17.0.0/16网段的数据包都由本机处理。
在实际应用场景中,Kubernetes集群的网络拓扑比较复杂,涉及Pod内部的容器之间、Pod之间、节点之间、Service与Pod之间以及集群与外部网络之间的通信。本节将详细介绍这些通信的实现方式。
图8-2展示了Kubernetes集群中的三种IP地址和三种网络的概念。为了便于理解,可以将节点的IP地址比作TCP/IP网络中的第二层地址,即MAC地址,通过它去寻找物理节点。而这个地址通常对Kubernetes里的Pod来说是透明的,不用知道其他Pod的节点IP地址,通过Pod的IP地址就能访问到。所以Pod IP地址可以看作是网络结构中的三层IP地址。而ClusterIP更像是一个域名,不用知道背后到底有哪些Pod,它们又分布在哪里。

图8-2 Docker与Kubernetes网络比较
用过Docker基本都知道,启动docker engine后,主机的网络设备里会有一个docker0的网关,而容器默认情况下会被分配在一个以docker0为网关的虚拟子网中。
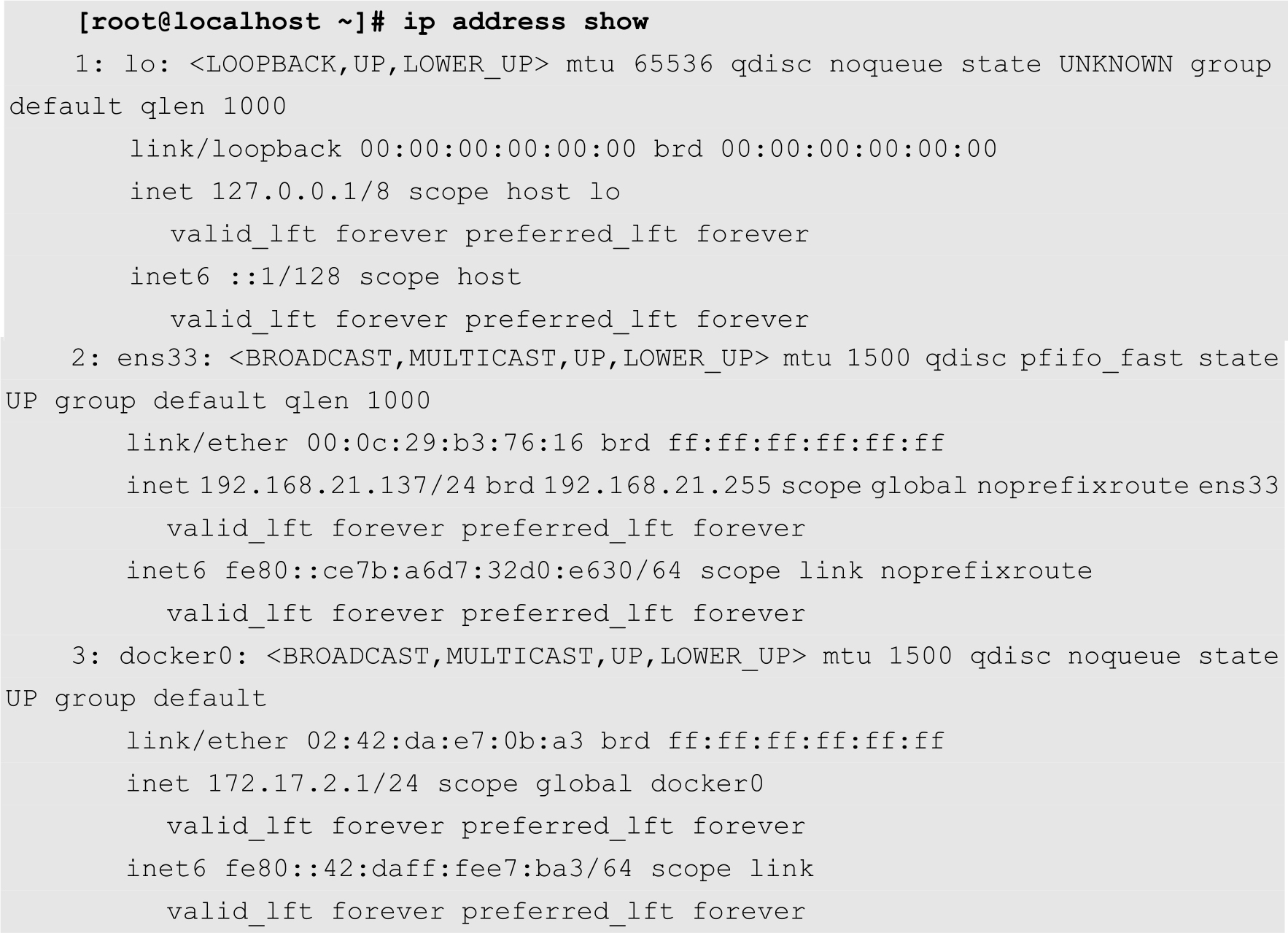
实际上,docker0是一个虚拟网桥,工作在第二层网络。也可以为它配置IP,工作在三层网络。通过docker0,将各个容器连接起来。
Docker默认的网络是为同一台宿主机的Docker容器通信设计的,Kubernetes的Pod需要跨主机与其他Pod通信,所以需要设计一套让不同节点的Pod实现透明通信,即不通过NAT的机制。
docker0的默认IP地址是172.17.2.1,Docker启动的容器也默认被分配在172.17.2.1/24的网段里。跨主机的Pod通信要保证Pod的IP地址不能相同,所以还需要设计一套为Pod统一分配IP地址的机制。
下面的命令显示了同一个Pod里面的不同容器的信息。其中,pause容器的信息如下:

而另外一个普通容器的信息如下:
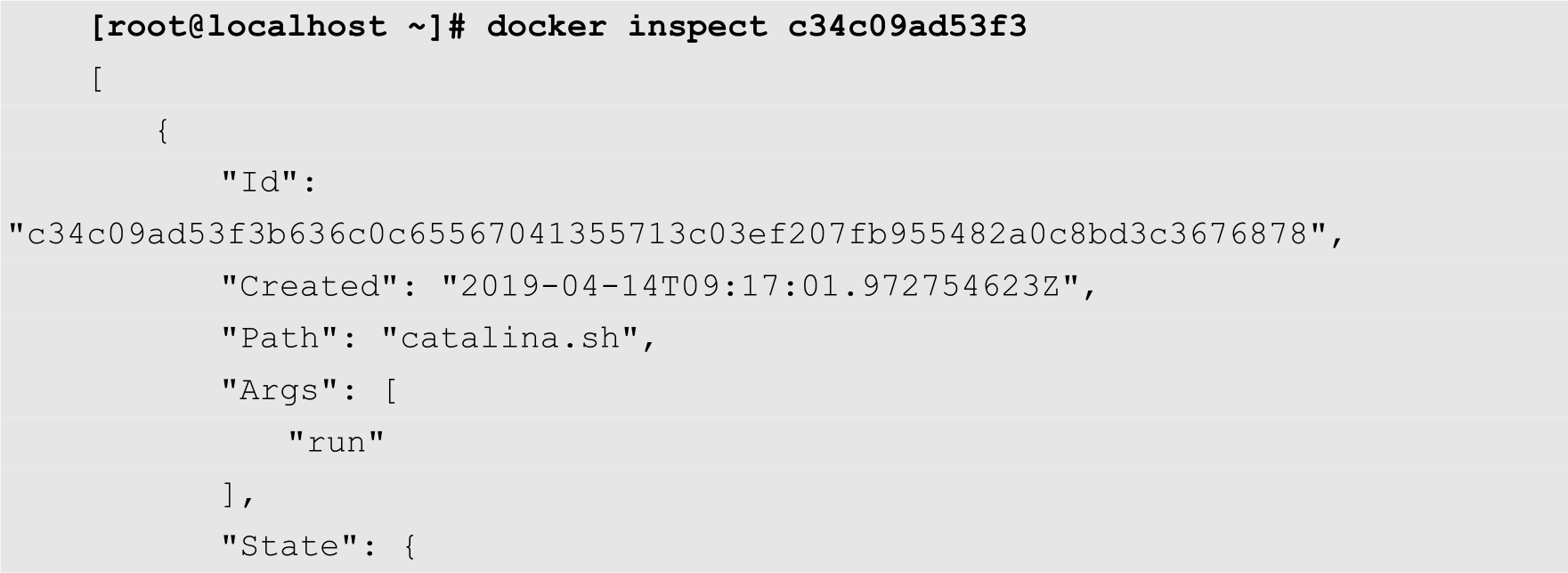


从上面的命令可以看出,在这个Pod中,普通的容器通过NetworkMode字段与pause容器共享了网络。在这种情况下,同一个Pod里面的容器相互之间的访问,只需要通过localhost加端口的形式就可以了。
更进一步地思考一下,pause容器的IP地址又是从哪里获取到的?如果还是以docker0为网关的内网IP,就会出现问题了。
docker0的默认IP地址是172.17.2.1,Docker启动的容器也默认被分配在172.17.2.0/24网段里。跨主机的Pod通信要保证Pod的IP地址不能相同,所以还需要设计一套为Pod统一分配IP的机制。
以上就是Kubernetes在Pod网络这一层需要解决的问题。目前Kubernetes提供了许多网络插件来解决这个问题,比较常见的有Flannel、CNI以及DANM等。
前面已经介绍过,Pod是Kubernetes集群中最小的调度单元。而Pod实际上是容器的集合,在Pod中可以包含一个或者多个容器。Pod包含的容器都运行在一个节点上,这些容器拥有相同的网络空间,容器之间能够相互通信。Pod网络本质上还是容器网络,所以Pod的IP地址就是Pod中第一个容器的IP地址。
Docker云的网络模型为一个扁平化网络,Pod作为一个网络单元同Kubernetes节点的网络处于同一层级。
同一个Pod之间的不同容器因为共享同一个网络命名空间,所以可以直接通过localhost进行通信。
假设在当前集群中存在着一个Pod,其配置文件如下:

从上面的代码可知,该Pod包含3个容器,分别为nginx-container、mysql-container和centos-container。
创建以上Pod之后,执行以下命令进入到centos-container容器中:
[root@localhost ~]# kubectl exec -it two-containers -c centos-container --
/bin/sh
然后执行以下命令来测试是否可以访问到nginx-container:

前面已经介绍过,curl命令是一个功能强大的HTTP客户端工具。在上面的例子中,通过该命令访问nginx-container的80端口。可以发现,上面的输出代码正是Nginx的输出结果。从上面的例子可知,用户可以在同一个Pod的容器中,通过localhost和端口来直接访问另外一个容器。
接下来,我们在同一个容器中访问mysql-container。这次使用telnet命令,如下所示:

从上面的输出结果可知,centos-container同样也可以通过localhost加3306端口直接访问mysql-container中的服务。
通过上面的例子,可以充分说明,同一个Pod中的容器是共享一个IP地址,用户可以通过端口来区分不同的服务。
接下来,再讨论一下Pod之间的通信。Pod之间的网络通信主要有两种情况,一种是同一个节点上的不同Pod之间的通信,另外一种情况是不同节点上的Pod之间的通信。
在同一个节点中,不同的Pod都拥有一个全局IP地址,Pod之间可以直接通过IP地址进行通信。
例如,在当前节点中,一共有4个Pod,如下所示:

这4个Pod的IP地址分别为172.17.0.2~172.17.0.5。下面先进入名为centos-controller -qj0fc的容器,命令如下:
[root@localhost ~]# kubectl exec -it centos-controller-qj0fc -c centos --
/bin/sh
然后通过ping命令测试是否可以访问172.17.0.2的Pod,执行结果如下:

以上命令的输出结果表明,这2个Pod之间是连通的。此时,如果ping其他Pod,也会得到类似的结果。
实际上,在同一个节点中,不同的Pod通过一个名为docker0的网桥连接起来。例如,用户可以通过以下命令将当前节点的网络接口罗列出来:
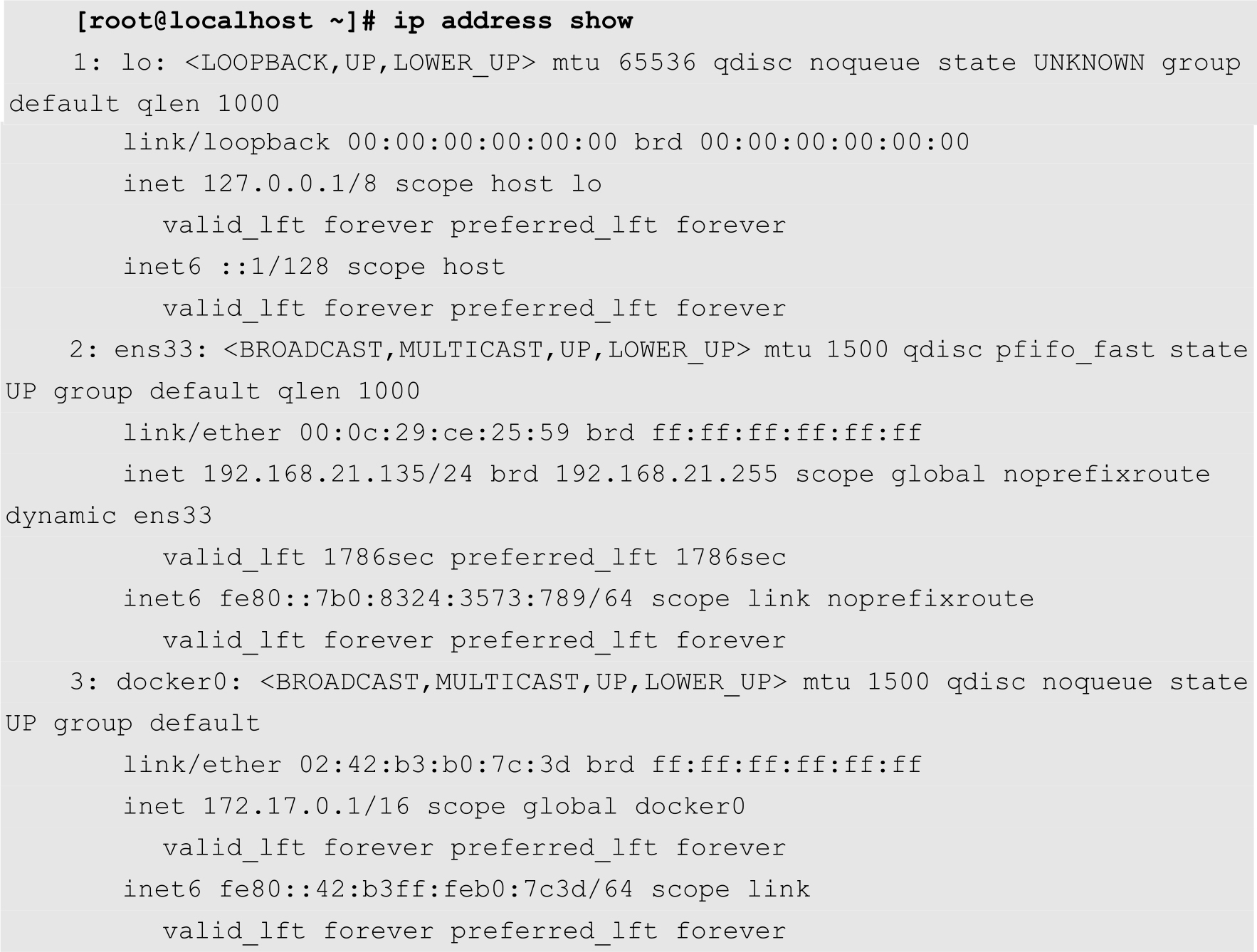
从上面的输出可知,编号为3的docker0的IP地址为172.17.0.1,这个IP地址与Pod的IP地址位于同一个网段中。
brctl命令则可以将网桥的信息显示出来,如下所示:

从上面的输出结果可知,在当前节点中,有4个虚拟网络接口被桥接到了docker0上面。正是通过这种方式,实现了Pod之间的直接通信。
图8-3描述了同一个节点中不同的Pod之间的网络通信。从图中可以看出,Pod1和Pod2都是通过veth虚拟网络接口连接到同一个docker0网桥上,这些虚拟网络接口的IP地址都是从docker0的网段上动态获取的,它们和docker0网桥同属于一个网段,因此,Pod1和Pod2以及docker0可以直接通信。
对于不同的节点的Pod来说,情况就比较复杂了。不同的节点之间,节点的IP地址相当于外网IP地址,它们之间可以直接相互访问。但是节点内部的Pod和docker0网桥的IP地址则是内网IP地址,无法直接跨越节点访问。如果它们之间想要实现通信,就必须通过节点的网络接口进行转发,如图8-4所示。
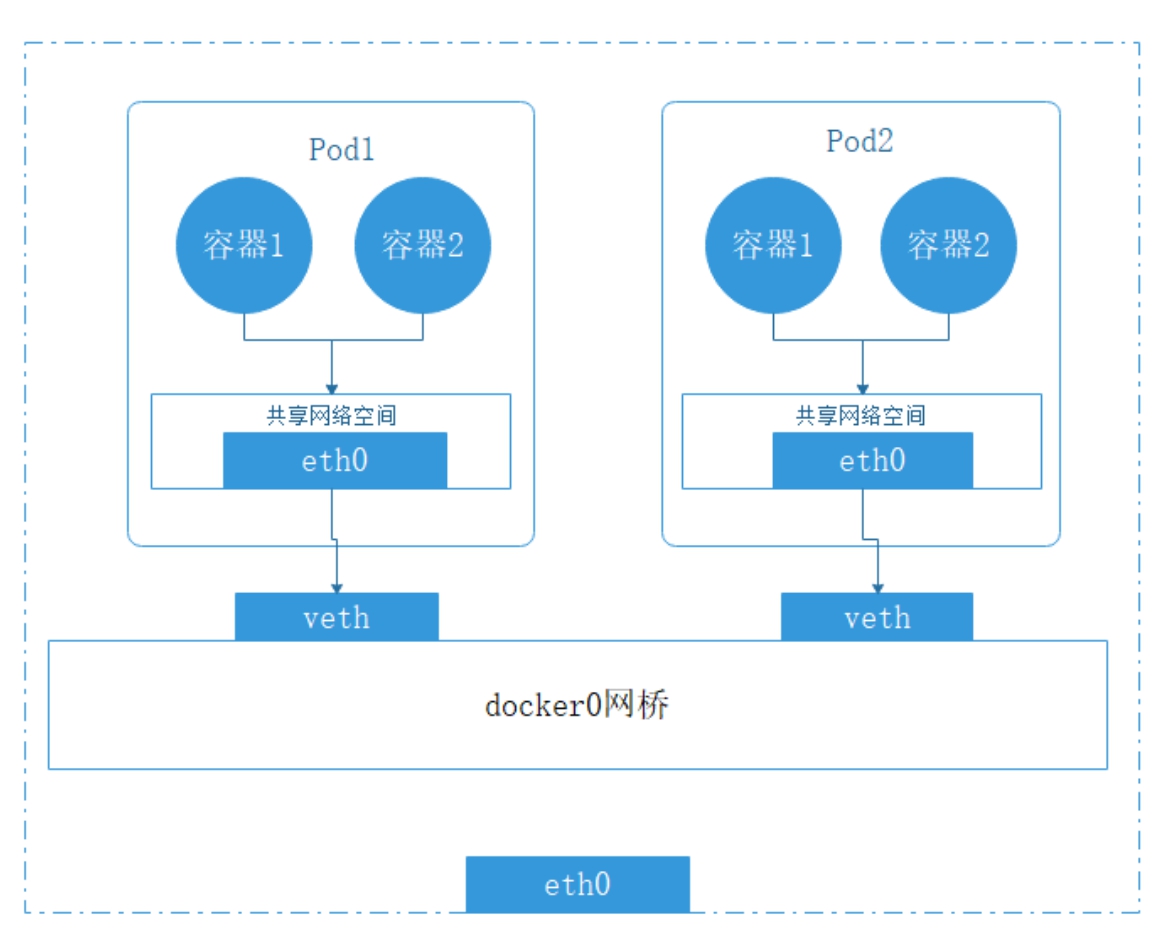
图8-3 节点内部Pod之间的通信
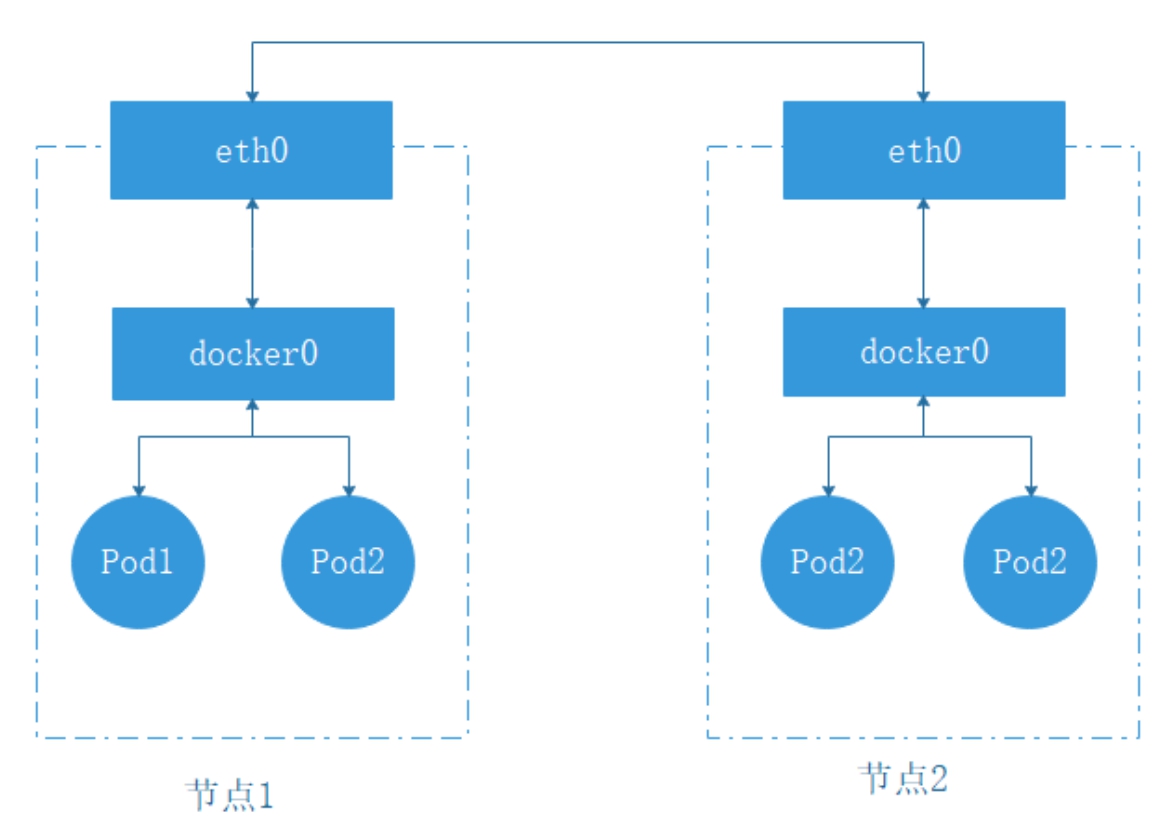
图8-4 不同节点的Pod之间通信
关于Pod和服务之间的关联,实际上在前面的一些章节中已经做了部分介绍。但是,在前面的介绍中,主要内容放在了介绍如何配置和发布服务上面,对于其中的网络原理并没有过多地介绍。在本节中,将从Kubernetes的基本网络管理着手,详细介绍Kubernetes是如何实现从Service到Pod中应用系统的访问的。
首先准备3个节点,其中一个为Master节点,另外2个为Node节点,其拓扑结构如图8-5所示。
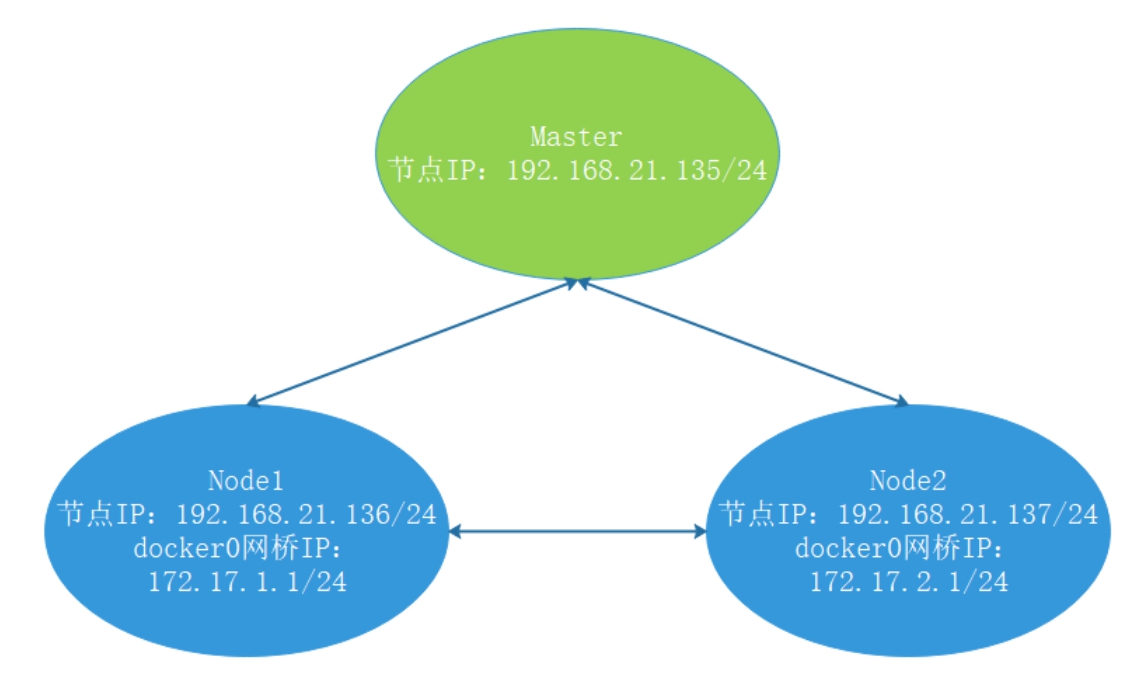
图8-5 拓扑结构
在图8-5中,Master节点的IP地址为192.168.21.135,Node1节点的IP地址为192.168.21.136,其中docker0网桥的IP地址手工设置为172.17.1.1。Node2节点的IP地址设置为192.168.21.137,docker0网桥的IP地址设置为172.17.2.1。通过这样的设置,可以使读者更加深入地理解和掌握Kubernetes的网络原理。
首先,在Node1和Node2这两个节点上修改一下docker0网桥的IP地址。前面已经介绍过,Docker默认为docker0网络分配了一个IP地址172.17.0.1/16。随后所有的当前节点的容器的IP地址都是从docker0所在的172.17.0.0/16网络中自动分配。当然,在Docker中,这个网段仅限于当前节点中访问,是不可以被路由的。所以,尽管在每个节点中,docker0的IP地址以及容器的IP地址都属于172.17.0.0/16网络,但是用户不必考虑冲突的问题。
而在Kubernetes中,所有节点的docker0网桥都是可以被路由的,即不同节点之间可以直接相互访问,而不必通过NAT。为此,我们需要将其修改成不同的网段。
对于Node1节点,docker0网桥的IP地址可以直接使用以下命令进行修改:
[root@localhost ~]# ip addr add 172.17.1.1/24 dev docker0
然后将原来的IP地址删除,命令如下:
[root@localhost ~]# ip addr delete 172.17.0.1/16 dev docker0
使用以下命令查看IP地址是否设置成功:

如果输出信息如上所示,则表示已经成功修改。
但是以上命令仅仅是临时生效,当节点被重新启动之后,所有的配置都将丢失。为了能够将配置长久保存下来,用户可以修改Docker的配置文件/etc/docker/daemon.json。在配置文件中增加以下代码:

其中,bip表示将docker0网桥的IP地址设置为其后面的值。
用户需要在Node2节点上修改/etc/docker/daemon.json配置文件,增加以下代码:

通过以上配置,Node1和Node2中容器就会分别赋予172.17.1.0/24和172.17.2.0/24这两个网络的IP地址,并且默认的网关将被分别设置为docker0的IP地址,即172.17.1.1和172.17.2.1。
修改完成之后,重新启动Docker服务。此时,在Node1节点上通过iptables-save命令查看防火墙规则,会发现在NAT表中多出以下规则:
-A POSTROUTING -s 172.17.1.0/24 ! -o docker0 -j MASQUERADE
以上规则表示源地址为172.17.1.0/24的,但是又不是由docker0网桥发出的,实际上就是容器发出的数据包,需要进行源地址转换,转换为节点的IP地址。
同时,查看Node1节点的路由表,也会出现通向172.17.1.0/24网络的路由规则,如下所示:

以上信息表明,Kubernetes已经准备好了Pod网络的路由。
注意
在Node2节点上面,用户也可以得到类似的信息。
接下来,继续在集群中部署Tomcat应用。在Master节点中创建Tomcat应用的YAML配置文件,如下所示:

将以上代码保存为tomcat-pod.yaml,
[root@localhost ~]# kubectl create -f tomcat-pod.yaml pod "tomcat" created
查看Pod的状态,命令如下:

可以发现,我们刚才创建的Pod已经处于运行状态,位于Node1节点上,分配给它的IP地址为172.17.1.3。
在Node1上查看网络接口,可以发现多出一个veth网络接口,如下所示:
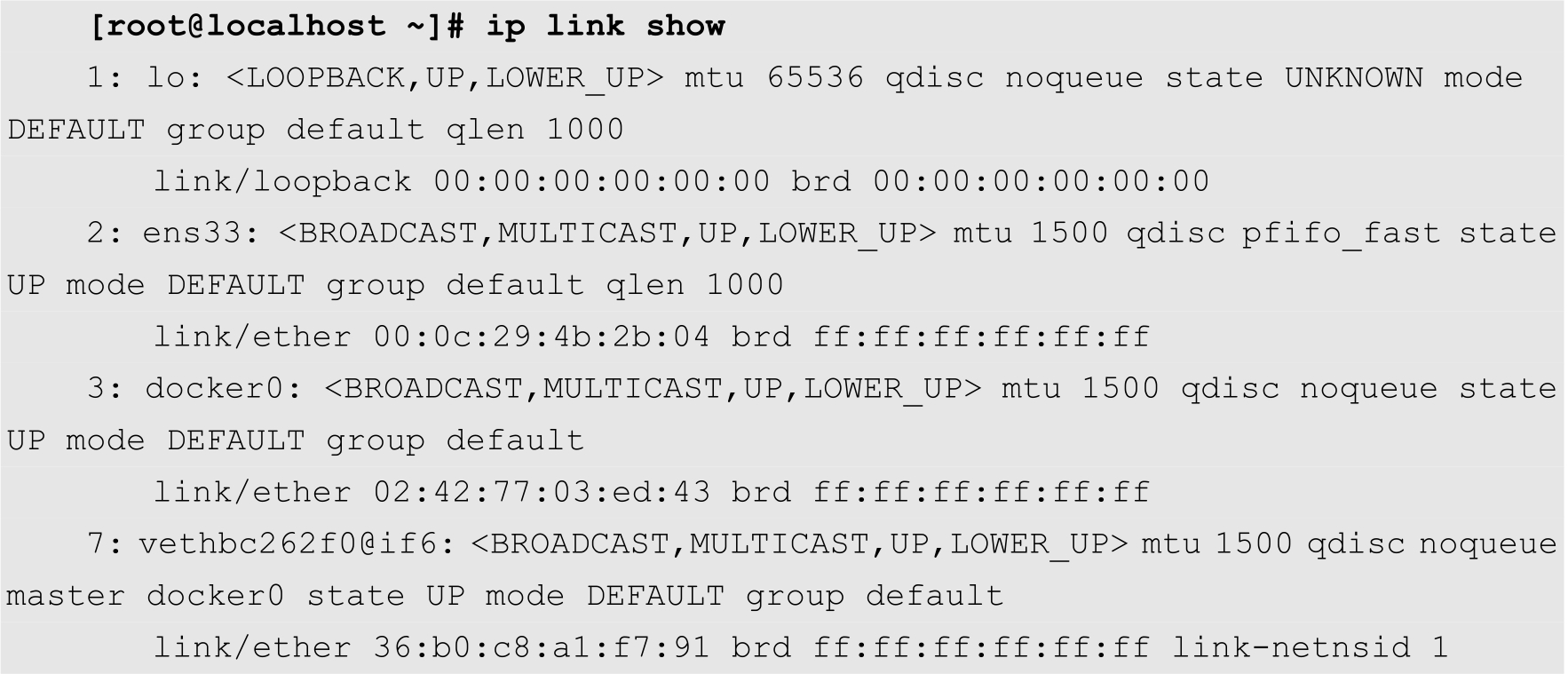
而该网络接口被桥接到了docker0网桥上,如下所示:

在Node1节点上,通过curl命令尝试访问172.17.1.3的Pod的8080端口,结果如下:

以上的输出结果正是Tomcat的默认输出结果,这表明Tomcat已可被正常访问。
但是,如果用户在Master和Node2节点上访问172.17.1.3:8080,则会出现以下问题:
[root@localhost ~]# curl 172.17.1.3:8080 curl: (7) Failed connect to 172.17.1.3:8080; No route to host
以上信息表明,在其他的两个节点上,没有发现到172.17.1.0/24网络的路由。如果通过ping命令分别在2个节点上测试到172.17.1.0/24网络的网关,即Node1上的docker0的IP地址172.17.1.1的连通性,则会输出以下结果:

这也表明无法在其余的2个节点上访问该网关。
在Master节点和Node2节点上分别查看路由表信息。其中Master节点的路由表如下所示:

Node2节点的路由表如下:

从上面的输出结果可知,这2个节点确实没有访问172.17.1.0/24网络的路由规则。
为了能够实现Pod的直接访问,用户需要在这3个节点上面分别添加到172.17.1.0/24和172.17.2.0/24这2个网络的路由规则。其中,在Master节点上,用户需要将这2条规则同时添加上去。
[root@localhost ~]# ip route add 172.17.1.0/24 via 192.168.21.136 [root@localhost ~]# ip route add 172.17.2.0/24 via 192.168.21.137
而在Node1和Node2节点上,由于本身已经分别有了到172.17.1.0/24和172.17.2.0/24的路由规则,只需要添加另外一条即可。
到目前为止,用户理论上应该可以在三个节点上都可以访问刚才部署的Tomcat应用了。但是实际上还不可以。这是因为除了Kubernetes本身的规则之外,默认情况下Linux本身的防火墙规则中,INPUT和FORWARD这2个链的默认规则都是拒绝的,所以用户需要在Node1和Node2上分别执行以下命令,将其默认规则设置为ACCEPT:
iptables -P INPUT ACCEPT iptables -P FORWARD ACCEPT iptables -F iptables -L -n
最后,用户就会发现,在任意一个节点上都可以直接访问到了172.17.1.3:8080这个应用。
下面再接着创建服务,其配置文件如下:

将以上代码保存为tomcat-service.yaml,然后在Master节点上执行以下命令创建该服务:
[root@localhost ~]# kubectl create -f tomcat-service.yaml service "tomcat" created
查看刚才创建的服务的状态,如下所示:

从以上命令的输出可知,Kubernetes已经为名为tomcat的服务分配了一个ClusterIP,其值为10.254.12.13,端口为8080,选择器为name=tomcat。
ClusterIP是一个虚拟的IP地址,并不在集群或者节点中真实存在。这个IP地址是在kube-apiserver的配置文件中定义的,如下所示:
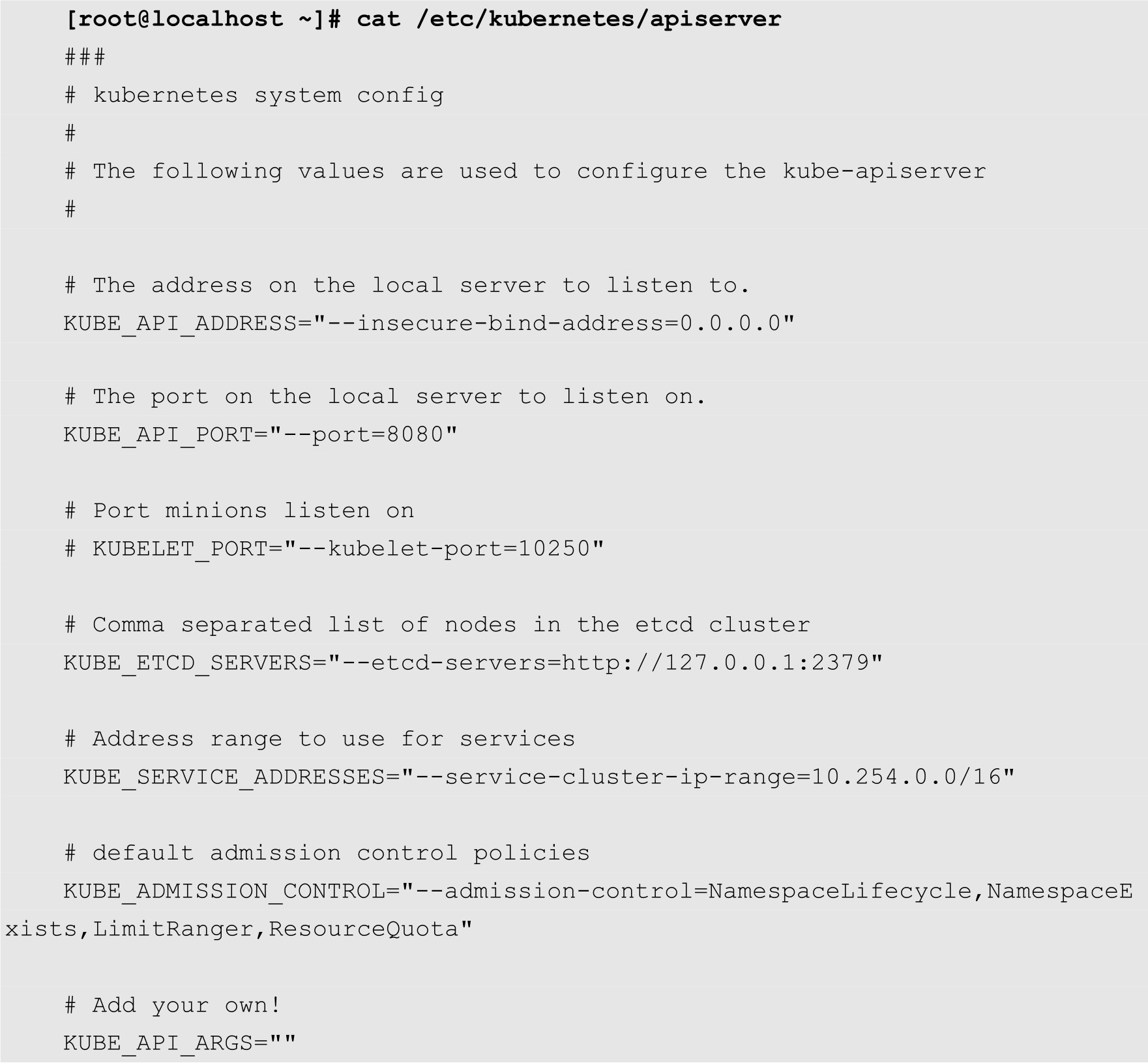
其中--service-cluster-ip-range选项定义了服务所在的网络。
实际上,ClusterIP所在的网络可以随意分配,只要不跟物理网络和docker0的网络冲突即可。ClusterIP应用范围仅仅局限于当前节点,不会在物理网络和docker0所在的网络上路由。ClusterIP的作用仅仅是将访问该服务的流量发送到与其绑定的Endpoints上。
在任何一个节点上使用iptables-save命令查看iptables的规则,会发现多出多条与ClusterIP有关的规则,如下所示:
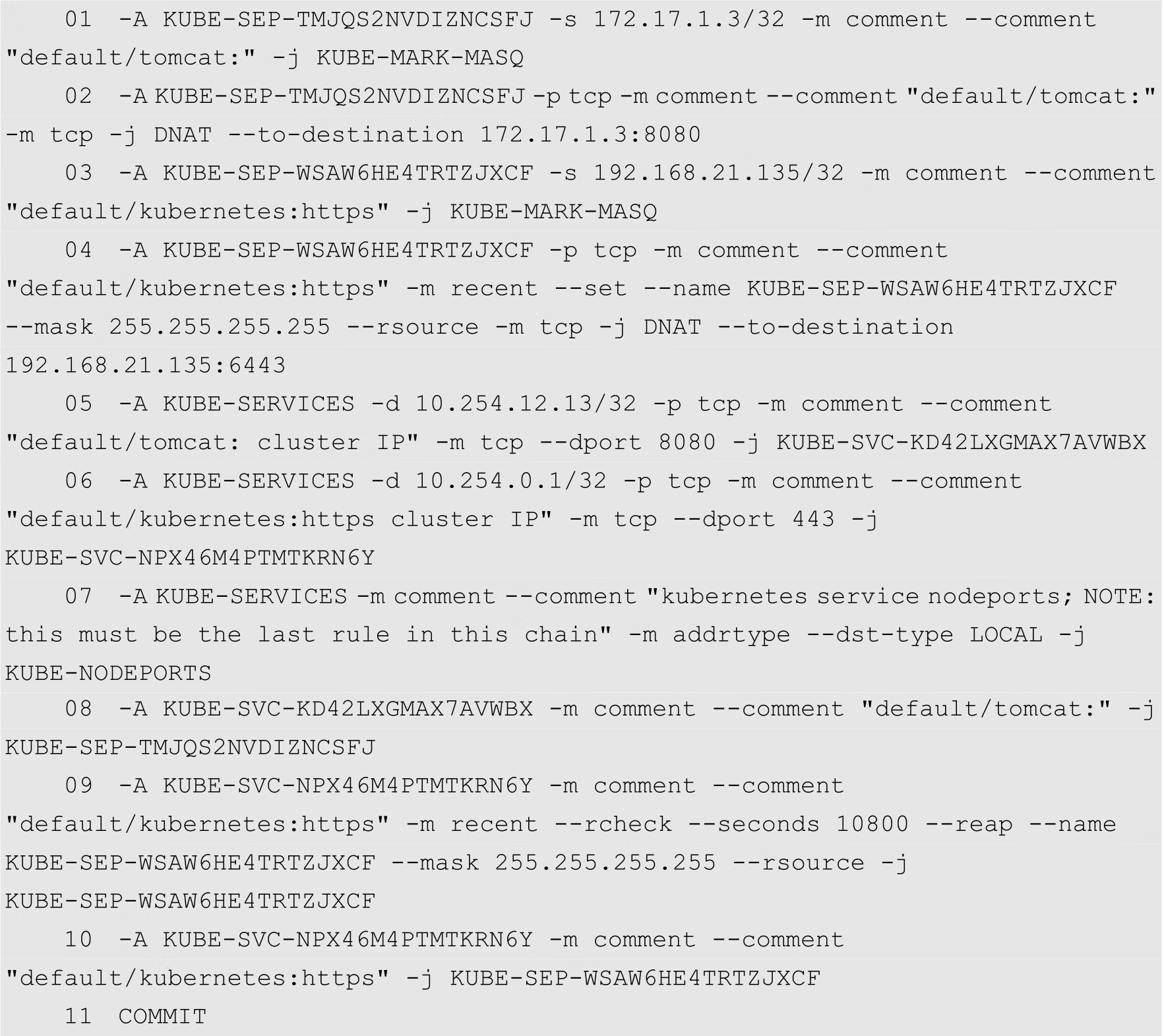
其中,第5条规则表示目标地址为10.254.12.13/32,并且目标端口为8080的数据包将被KUBE-SVC-KD42LXGMAX7AVWBX自定义链中的规则处理。而第8行定义了匹配KUBE-SEP-TMJQS2NVDIZNCSFJ自定义链中规则的数据包,将由TMJQS2NVDIZNCSFJ链中的规则处理。第2行定义了匹配TMJQS2NVDIZNCSFJ规则的数据包,将进行目标地址转换,转换目标为172.17.1.3:8080,这个地址正是前面分配给名为tomcat的Pod的IP地址,以及Tomcat的服务端口。
从上面的分析可知,从服务到Pod之间的访问是调用iptables的规则实现的。
在任意节点上访问前面定义的服务,如下所示:

Flannel是一个专为Kubernetes定制的三层网络解决方案,主要用于解决容器的跨主机通信问题。本节将详细介绍Flannel的基本情况以及安装和使用方法。
Flannel是一个Kubernetes网络插件,专门用于设置Kubernetes集群中的容器的网络地址空间。Flannel利用etcd来存储整个集群的网络配置。例如,用户可以设置整个集群中所有容器的IP地址都取自网络10.1.0.0/16。
在每个节点中,都运行着Flannel的代理服务flanneld。该代理程序会为当前节点从集群的网络地址空间中,获取一个子网,本节点中所有的容器的IP地址都将从该子网中分配。所有的网络配置信息,都将存储在etcd中。
Flannel提供了多种后端机制,例如udp、vxlan等。通过这些机制,实现了跨主机转发容器间的网络流量,完成容器间的跨主机通信。
图8-6描述了在Flannel网络中,容器之间的数据通信。首先,容器中的应用程序将数据包通过自己的网络接口eth0发送出去。然后,数据包会发送到虚拟网络接口veth。而veth与虚拟网桥docker0桥接在一起,可以直接通信。因此,数据包通过docker0发送到虚拟网络接口flannel0。而Flannel在etcd中存储了各个子网的路由规则,所以flanneld在查找路由规则之后,通过节点的网络接口eth0发送到其他的节点。数据包在到达目标节点后,在传输层交给flanneld守候进程处理。数据被解包,发送给flannel0虚拟网络接口。经过路由之后,发送给docker0网桥,再到达虚拟网络接口veth,最后到达目标容器。

图8-6 Flannel跨节点通信
在CentOS中安装Flannel很简单,直接使用yum命令即可,如下所示:
[root@localhost ~]# yum -y install flannel
当然,用户也可以使用其他的安装方式,例如通过编译源代码或者下载二进制文件。对于初学者来说,通过操作系统的软件包管理工具来安装Flannel是非常容易掌握的。因为所有的节点都需要用到Flannel,所以用户需要在每个节点上执行以上命令。
然后在Master节点上执行以下命令,在etcd中配置Flannel的网络信息:

在上面的命令中,Network用来指定Flannel所使用的网络ID,后面分配给节点的子网都从该网络中分配。SubnetLen用来指定分配给节点的虚拟网桥docker0的IP地址的子网掩码的长度。SubnetMin用来指定最小子网的ID。SudbnetMax用来指定最大子网的ID。在上面的命令中,我们指定最小子网为10.0.1.0/24,最大子网为10.0.20.0/24,由于每个节点分配一个子网,因此可以支持20个节点。Backend用于指定数据包以什么方式转发,默认为udp模式,host-gw模式性能最好,但不能跨宿主机网络。
然后修改Flannel的配置文件/etc/sysconfig/flanneld,增加etcd的访问地址,内容如下:
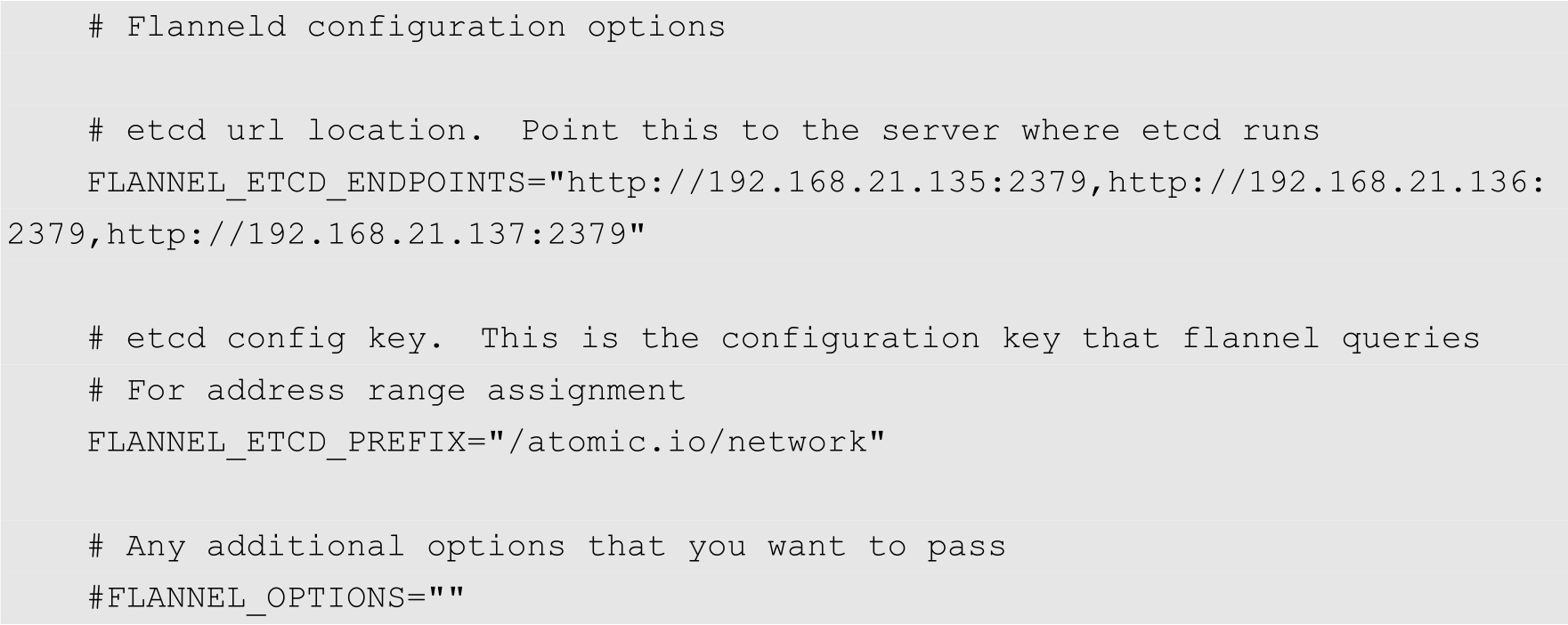
设置完成,在每个节点上启动Flannel,命令如下:
[root@localhost ~]# systemctl start flanneld
注意
用户需要在启动Flannel前启动Docker。
然后,用户可以在任意节点上执行以下命令,查看保存在etcd中的子网信息,如下所示:

从上面的输出结果可知,目前已经为3个节点分配了子网,分别是10.0.1.0/24、10.0.7.0/24和10.0.12.0/24。
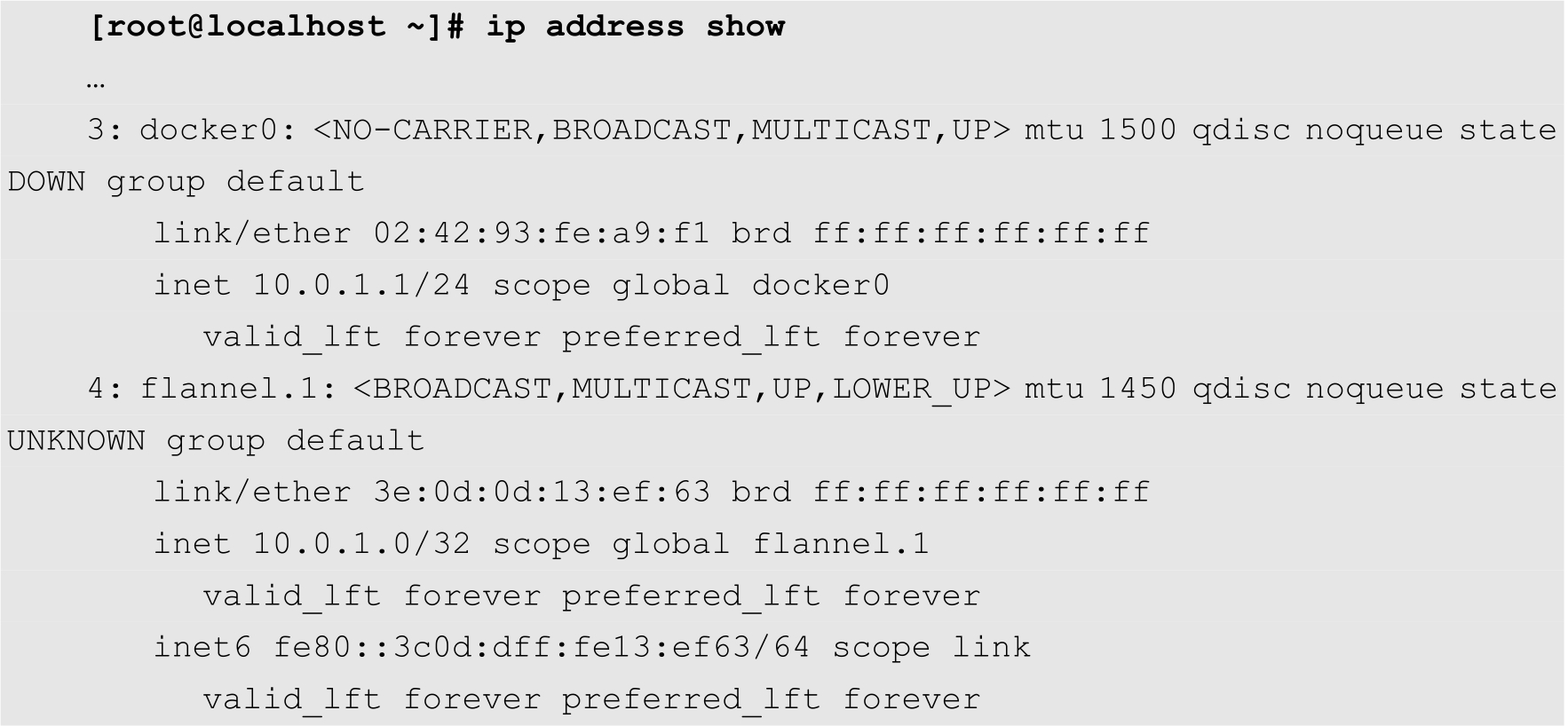
在每个节点上查看网络接口,可以看到多出一个以flannel开头的虚拟网络接口,该网络接口的IP地址都分别位于etcd中对应节点的子网中。例如,下面是其中一个节点的网络接口情况:

到此为止,Flannel已经安装成功了。接下来需要在各个节点上面配置Docker,修改其启动参数,使其能够从Flannel分配给当前节点的子网中获取IP地址。
在Flannel启动之后,会生成一个环境变量文件,包含了当前主机要使Flannel通信的相关参数,如下所示:

用户可以使用以下命令将其转换为Docker的启动参数:
[root@localhost ~]# /usr/libexec/flannel/mk-docker-opts.sh
默认情况下,生成的Docker启动参数位于/run目录中,其名称为docker_opts.env,代码如下:

修改Docker的服务单元文件/lib/systemd/system/docker.service,增加启动参数,如下所示:
#EnvironmentFile=-/etc/sysconfig/docker-network EnvironmentFile=-/run/docker_opts.env
然后重启Docker,命令如下:
[root@localhost ~]# systemctl daemon-reload [root@localhost ~]# systemctl restart docker
再次查看docker0虚拟网桥的IP地址,就会发现其IP地址已经属于flannel分配给当前节点的子网,如下所示:
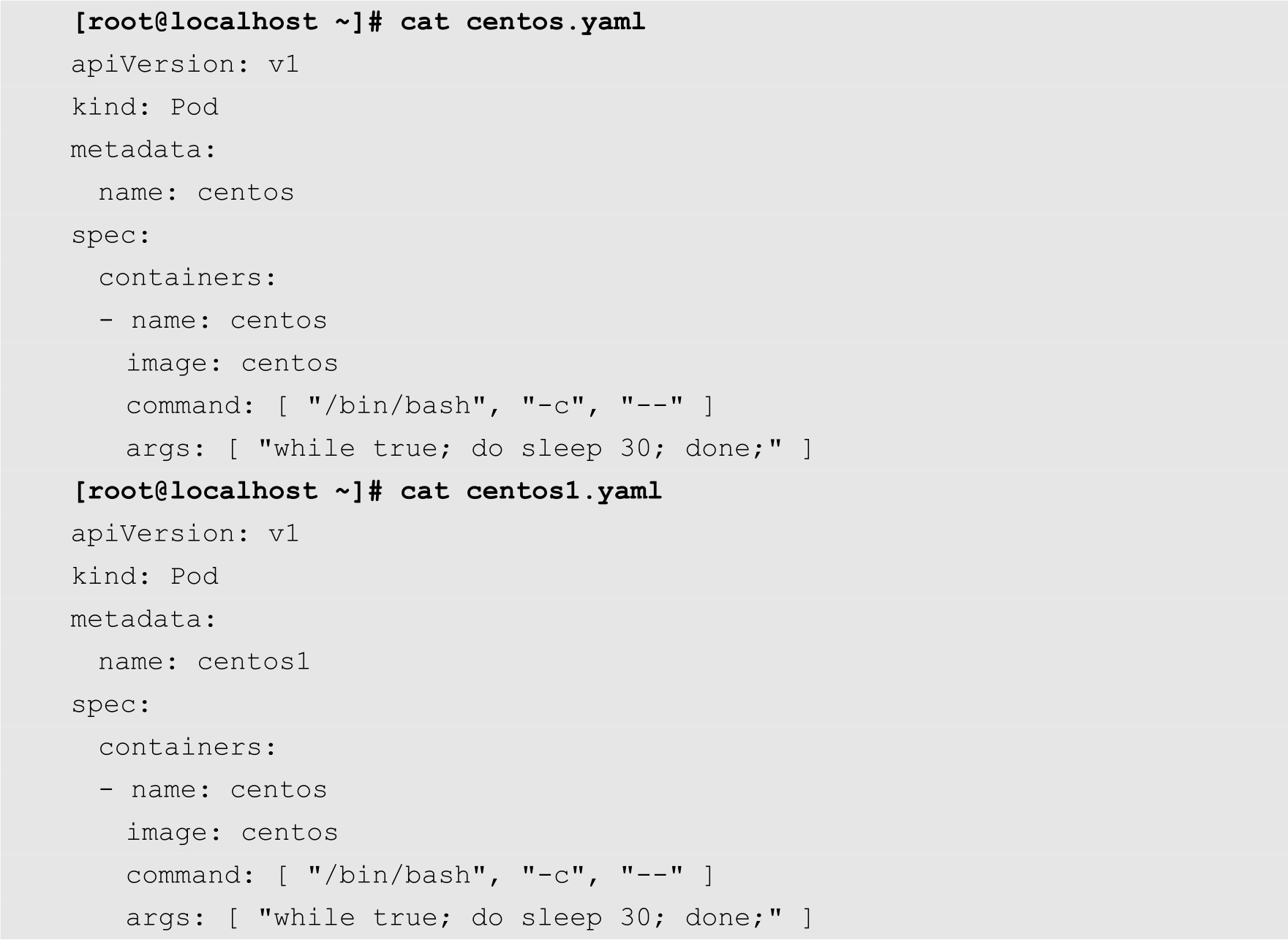
最后,我们通过创建两个Pod来验证其网络的连通性。这两个Pod的YAML配置文件如下:
然后分别使用以下命令创建Pod:
[root@localhost ~]# kubectl create -f centos.yaml [root@localhost ~]# kubectl create -f centos1.yaml
查看所创建的Pod状态信息:

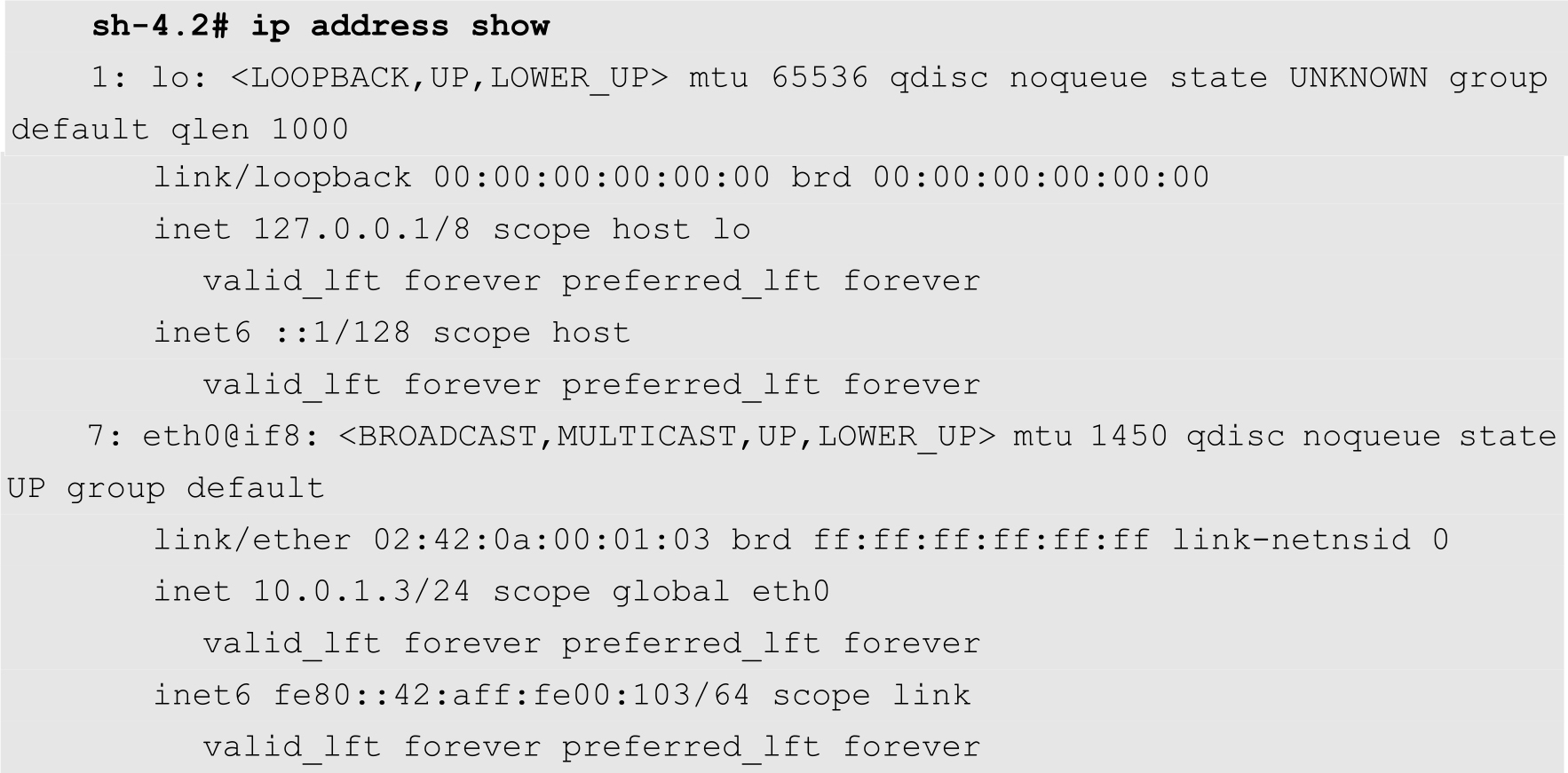
从上面的输出结果可知,这2个Pod分别在192.168.21.135和192.168.21.136这两个节点上,其IP地址分别为10.0.1.3和10.0.12.2。
先进入名为centos1的Pod:
[root@localhost ~]# kubectl exec -it centos1 -- /bin/sh
查看其IP地址,如下所示:
通过ping命令测试与另外一个Pod的连通性,如下所示:

从上面的输出结果可知,尽管这2个Pod分别位于不同的节点,但是它们之间可以直接访问。