
在Kubernetes集群中,服务的运行离不开将数据持久化地保存起来,这就涉及Kubernetes的存储系统了。存储系统的功能是将各种服务在运行过程中产生的数据长久地保存下来,即使容器被销毁,数据仍然存在。本章将对Kubernetes的存储系统进行详细介绍。
本章涉及的知识点有:
存储卷(Volume)是Kubernetes持久化数据的最基本的功能单元。Kubernetes的数据卷是Docker数据卷的扩展,Kubernetes适配各种存储系统,包括本地存储EmptyDir和HostPath,网络存储NFS、GlusterFS以及PV/PVC等。本节将详细介绍如何实现Kubernetes的存储。
我们通常讲,容器和Pod是短暂的,它们会被频繁地销毁和创建。容器被销毁时,保存在容器内部文件系统中的数据就会被清除。此外,Pod中的多个容器经常需要共享文件,如果没有其他的机制,单纯依靠容器本身是无法实现的。正因为以上的原因,Kubernetes专门提供了存储卷(Volume)来解决这些问题。
存储卷的生命周期独立于容器,Pod中的容器可能被销毁和重建,但存储卷会被保留。本质上,Kubernetes的存储卷是一个目录,这一点与Docker的卷类似。当存储卷被挂载到Pod,Pod中的所有容器都可以访问这个存储卷。Kubernetes的存储卷也支持多种后端类型,目前为止,大约有30余种,主要包括emptyDir、hostPath、GCE Persistent Disk、AWS Elastic BlockStore、NFS以及Ceph等。
存储卷提供了对各种后端存储的抽象,容器在使用存储卷读写数据的时候,不需要关心数据到底是存放在本地节点的文件系统中,还是云硬盘上。对它来说,所有类型的存储卷都只是一个目录。
emptyDir卷是最基础的存储卷类型之一。简单地讲,一个emptyDir类型的存储卷就是宿主节点上面的一个空目录。
emptyDir卷对于容器来说是持久的,也就是说,emptyDir卷不会随着容器的销毁而销毁。但是emptyDir卷对于Pod来说,则不是持久的。当Pod从节点中删除时,其所拥有的emptyDir卷也会被删除,其中的数据也会丢失。也就是说,emptyDir卷与Pod的生命周期是一致的。Pod中的所有容器都可以共享卷,它们可以指定各自的挂载路径。下面通过例子来演示emptyDir卷的使用方法。首先创建一个名为emptydir-demo.yaml的配置文件,内容如下:
在上面的代码中,第2行指定资源类型为Pod,该Pod将会挂载所创建的emptyDir。第4行指定Pod的名称为emptydir-demo。第7~15行定义了一个容器,该容器的名称为c1。第9~11行定义容器内的挂载点,挂载路径为/messages,存储卷的名称为data。第13~15行定义参数,该参数的功能是输出以下字符串:
Hello, world.
以上字符串将会被输出到/messages/hello文件中,并且休眠3秒。
第16~24行定义了另外一个容器,其名称为c2。c2同样也将名称为data的emptyDir卷挂载在/messages路径下。不过,该容器的参数指定通过cat命令将/messages/hello文件的内容输出到标准输出。第25行开始定义emptyDir卷,其名称为data,类型为emptyDir。
通过上面介绍可知,上面的例子在名为emptydir-demo的Pod中定义了2个容器,其中一个容器的功能是输出一个字符串到emptyDir卷上的文件中,另外一个容器的功能是读取该文件。这两个容器同时挂载同一个emptyDir卷,实现了存储的共享。
然后使用以下命令创建emptyDir卷:
[root@localhost ~]# kubectl create -f emptydir-demo.yaml pod "emptydir-demo" created
创建完成之后,查看所创建的Pod的状态,如下所示:

从上面的输出结果可知,刚刚创建的Pod位于192.168.1.122节点上。通常情况下,存储卷在节点上的磁盘路径为:
/var/lib/kubelet/pods/<pod uuid>/volumes
其中pod uuid为Kubernetes分配给Pod本身的UUID。这个UUID可以通过kubectl get pod命令获取,需要输出JSON格式的结果,如下所示:

从上面的输出结果可知,emptydir-demo的UUID为c13c2c25-5269-11e9-a06b-000c2994a2b7。得知UUID之后,我们就可以登录到IP地址为192.168.1.122的节点,查看以下目录:
/var/lib/kubelet/pods/c13c2c25-5269-11e9-a06b-000c2994a2b7/volumes
目录内容如下:

以上输出结果中的kubernetes.io~empty-dir,即为emptyDir类型的存储卷所在的目录。在该目录中,保存着我们上面创建的名为data的emptyDir卷。在data目录中,会发现一个名为hello的文本文件,该文件的内容如下:

上面文件的内容就是名为c1的容器的命令的输出结果。
而对于第2个容器的输出结果,我们可以在容器的日志中获取到,如下所示:
[root@localhost ~]# kubectl logs emptydir-demo c2 Hello, world.
在上面的命令中,emptydir-demo为Pod的名称,c2为Pod中的容器的名称。
接下来,我们再分别在两个容器里面验证一下,看看是否能够访问刚才定义的存储卷。
首先查看名为c1的容器,由于在配置文件中我们指定卷的挂载路径为/messages,因此命令如下:

从上面的输出可以确认,在c1中的/messages目录中确实存在着名为hello的文件,其内容如下:

同样在c2中,也可以得到类似的结果,读者可以自行验证。
如果我们在节点中执行以下命令,在emptyDir卷所在的目录中创建一个新的文件:
[root@localhost ~]# echo "a message" > /var/lib/kubelet/pods/c13c2c25-
5269-11e9-a06b-000c2994a2b7/volumes/kubernetes.io~empty-dir/data/message
那这个文件也可以在容器中访问到,如下所示:

hostPath类型的存储卷的作用是,将节点的文件系统中已经存在的目录直接共享给Pod的容器。在实际生产环境中,大部分应用都不会使用hostPath卷,因为这实际上增加了Pod与节点的耦合,限制了Pod的使用。但是,如果应用系统需要访问Kubernetes或Docker内部数据,例如配置文件和二进制库,则需要使用hostPath卷。
hostPath卷一般和DaemonSet搭配使用,用来操作主机文件,例如加载主机的容器日志目录,达到收集本主机所有日志的目的。下面的代码是一个hostPath的YAML配置文件:

假设在节点的文件系统中存储着一个目录,其路径为:
/root/data
上面的配置文件就是使得名为test-container的容器直接挂在主机的/root/data目录。
NFS即网络文件系统,它最早在FreeBSD中实现。NFS的主要功能是通过局域网让不同的主机之间共享文件或者目录。NFS是典型的客户机/服务器架构,其客户端通常为应用服务器,而服务器通常是连接大容量存储设备的主机。客户机通过挂载的方式,将NFS服务器共享出来的目录挂载到本地系统中。从客户机的角度看,NFS服务器共享出来的目录,就好像是自己本地的磁盘分区或者目录一样,而实际上所有的文件系统都在服务器上面。
注意
NFS中的文件系统属于NFS服务器,而不属于客户机,这一点与iSCSI有着本质区别。
NFS网络文件系统类似Windows系统中的网络共享和网络驱动器映射,也和Linux系统里的Samba服务类似。
在企业集群架构的工作场景中,NFS网络文件系统一般被用来存储共享视频、图片、附件等静态资源文件。一般是把网站用户上传的文件都放在NFS中共享,例如,BBS产品的图片、附件、头像。但是要注意的是,网站BBS程序不要放在NFS中共享,然后让前端所有的节点访问存储服务,这种不规范的用法在中小网站公司中应用频率很高。
Kubernetes的存储卷支持NFS类型的远程存储系统,允许将一块现有的网络硬盘在同一个Pod内的容器间共享。
例如,当前局域网中存在着一个NFS服务器,其IP地址为192.168.12.40,该服务器将一个本地的文件系统/data/dsk1,通过NFS协议共享给Kubernetes集群使用。
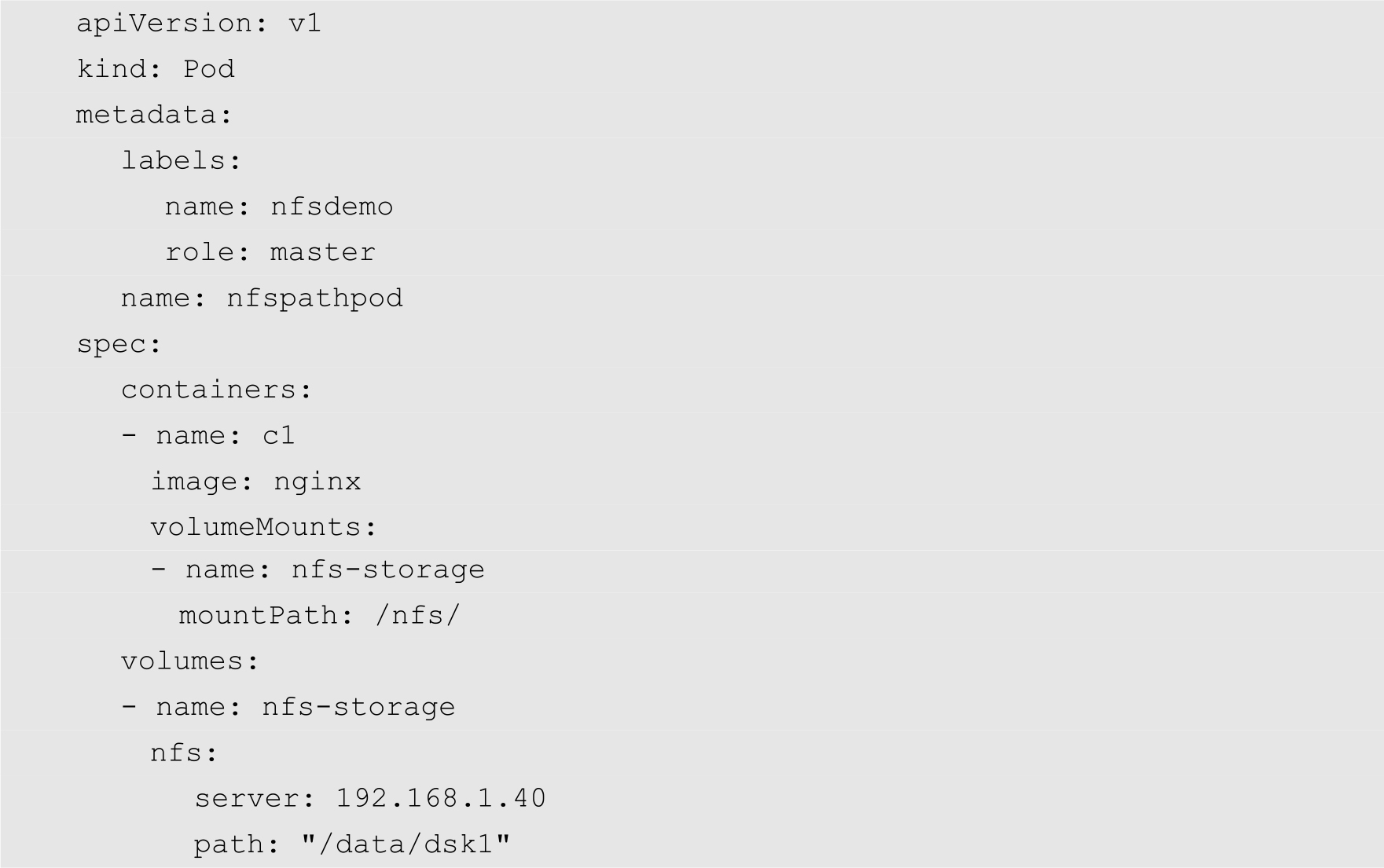
注意
使用NFS时需要在节点上安装NFS文件系统相关组件,否则节点无法挂载NFS文件系统。
在Kubernetes中,Secret卷是用来保存小片敏感数据的存储卷,例如账号、密码或者秘钥等。对于这类数据,管理员必须妥善保管。当然,除了妥善保管之外,还必须能够非常方便地控制如何使用。而Secret卷正是出于这种目的而设计的存储卷,相比于直接将敏感数据配置在Pod的定义或者镜像中,Secret卷提供了更加安全的Base64加密方法,防止数据泄露。用户可以创建自己的Secret卷,Kubernetes系统也会有自己本身的Secret卷。
Pod有两种方式使用Secret卷,首先,Secret卷可以作为存储卷被一个或者多个容器挂载;其次,在拉取镜像文件的时候被kubelet引用。
Secret卷的创建是独立于Pod的,以数据卷的形式挂载到Pod中,Secret卷的数据将以文件的形式保存,文件中保存的是一个或者多个“键-值对”(Key-Value Pair),容器通过读取文件可以获取需要的数据。下面详细介绍如何使用Secret卷存储账号和密码数据。
创建Secret卷的命令如下:
kubectl create secret name [--type=string] [--from-file=[key=]source]
[--from-literal=key1=value1]
用户可以通过3种方式为以上命令提供参数,分别是配置文件、目录或者字符串。当通过配置文件指定参数时,配置文件的基础文件名,即去掉路径和扩展名,将被作为“键-值对”的键,文件的内容将作为键值对的值。例如,如果配置文件的文件名为username.txt,内容为admin,则对应Secret卷中的“键-值对”为:
username=admin
如果用户通过目录创建Secret卷,则指定目录中的每个常规文件的基础文件名都将作为“键-值对”的键,其内容作该键对应的值。
如果直接在命令行中指定“键-值对”,则其语法如下:
--from-literal=key1=supersecret --from-literal=key2=topsecret
其中key1和key2为“键-值对”的键,supersecret和topsecret分别为对应的值。
例如,用户在访问数据库的时候,需要使用用户名和密码,这些账户信息都要存储到Secret卷中,其操作步骤如下。
(1)准备两个文本文件,其文件名分别为username.txt和password.txt,命令如下:
[root@localhost ~]# echo -n 'admin' > username.txt [root@localhost ~]# echo -n 'd5eeff42' > password.txt
上面的命令中,-n选项表示不输出最后的换行。大于号为重定向运算符,表示将echo命令的输出结果重定向到文件中。
(2)使用kubectl create命令创建Secret卷,如下所示:
[root@localhost ~]# kubectl create secret generic db-secret --from-file=./username.txt --from-file=./password.txt
通过上面的命令可知,用户可以使用多个--from-file命令来通过“键-值对”配置文件。
(3)查看Secret卷,命令如下:

从上面的输出结果可知,所创建的Secret卷的名称为db-secret,类型为Opaque,即不透明的,包含2个“键-值对”。
(4)查看Secret卷的详细信息,命令如下:

除了使用配置文件之外,以上操作可以通过命令行参数更加便捷地完成,相应的命令如下:
[root@localhost ~]# kubectl create secret generic db-secret
--from-literal=username='admin' --from-literal=password='d5eeff42'
当然了,作为一种Kubernetes资源,Secret卷也可以通过YAML配置文件来创建。例如,上面的Secret卷的YAML配置文件内容如下:

将上面的YAML配置文件保存为db-secret.yaml,然后使用以下命令创建Secret卷:
[root@localhost ~]# kubectl create -f db-secret.yaml
接下来我们创建一个Pod,用来挂载前面创建的Secret卷,并且使用里面存储的账号信息。该Pod的YAML配置文件的名为test-secret.yaml,其内容如下:
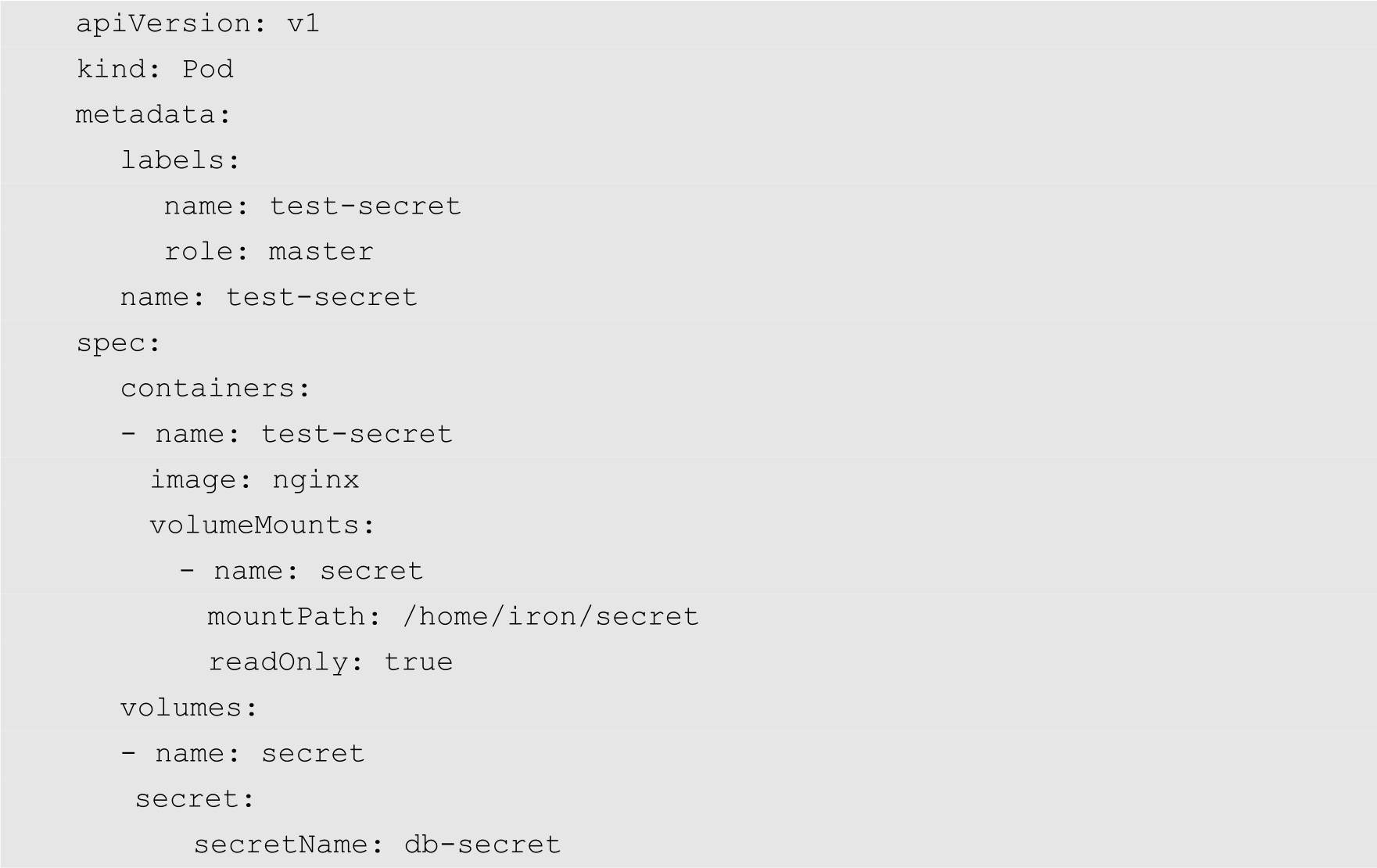
在上面的配置文件中,将前面定义的db-secret挂载到容器中。然后使用以下命令创建Pod:
[root@localhost ~]# kubectl create -f test-secret.yaml
我们再验证一下能否从容器中访问到db-secret中存储的数据。执行以下命令,查看db-secret数据卷中的文件列表,如下所示:

从上面的输出结果可知,前面存储在db-secret中的两个文件已经被列出来了。接下来通过cat命令查看文件的内容:

iSCSI卷允许将现有的iSCSI磁盘挂载到用户的Pod中,与emptyDir不同的是,删除Pod时emptyDir会被删除,但iSCSI卷只是被卸载,内容则会被保留。
下面的代码为一个挂载iSCSI卷的Pod的YAML配置:
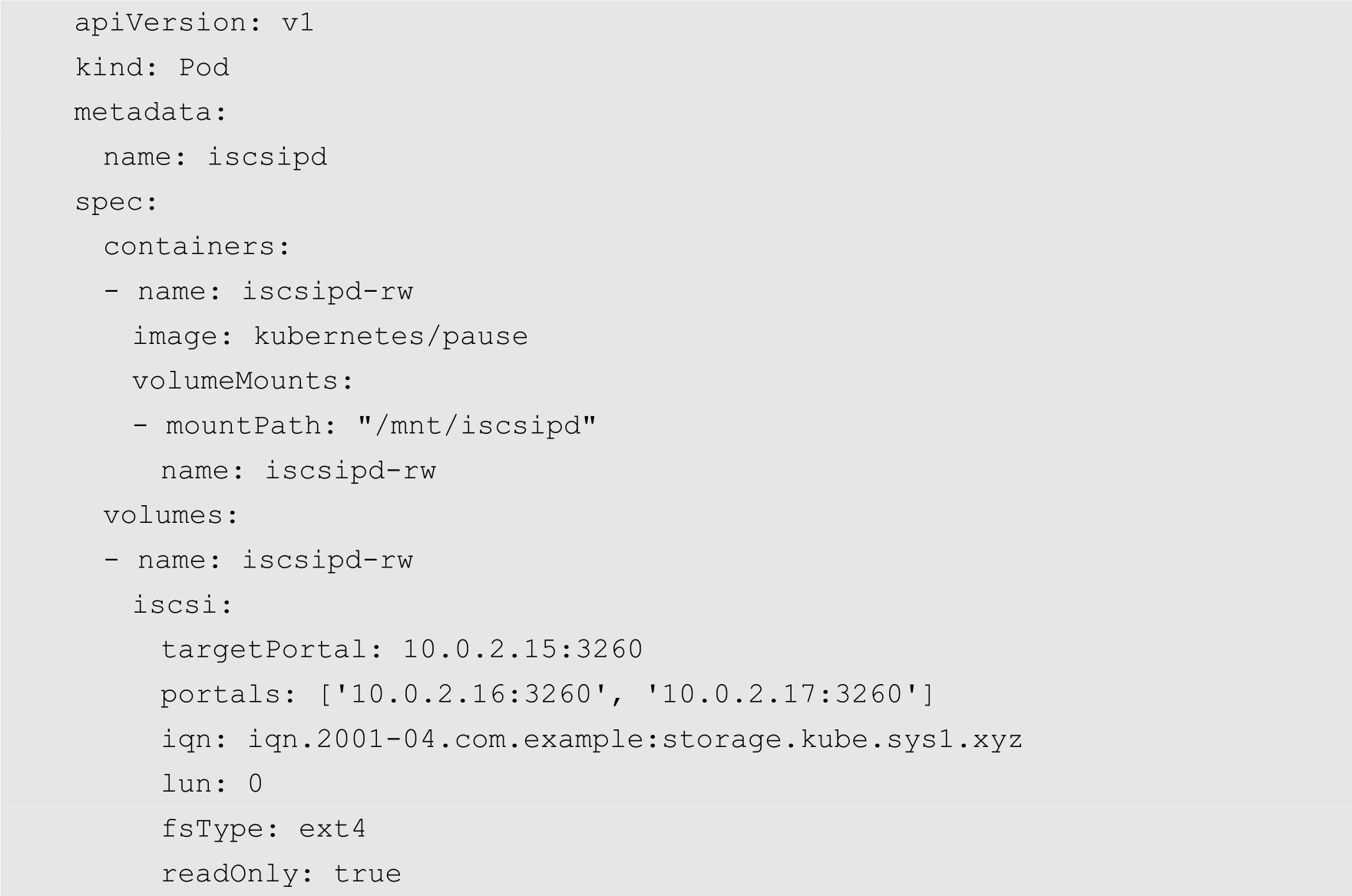
关于更加详细的iSCSI存储卷的使用方法,请参考相关的技术手册,这里不再具体介绍。
上一节介绍的存储卷已经为Kubernetes的数据持久化提供了很好的解决方案。但是存储卷在可管理性方面有着比较大的缺陷。于是Kubernetes又提出了持久化存储卷来解决这个问题。本节将详细介绍持久化存储卷的使用方法。
通过6.1节的学习,我们已经掌握了许多存储卷的使用方法。从前面的介绍可以得知,用户在使用存储卷的时候,必须首先掌握关于存储卷的各种细节。例如,在使用NFS存储卷的时候,用户需要知道NFS服务器的相关信息,例如IP地址、共享路径以及账号信息等。但是,在实际开发和运维过程中,Pod通常由开发人员来管理,而存储卷通常由维护人员来管理。这会导致开发人员和维护人员的工作边界不清晰,由此产生许多管理上的问题。如果系统规模较小或者对于开发环境,这样的情况还可以接受。但当集群规模变大,特别是对于生成环境,考虑到效率和安全性,这就成了必须解决的问题。
持久化存储卷(PersistentVolume)正是为了解决这个管理上的问题而提出的。持久化存储卷和节点一样,都是Kubernetes集群中的一种资源,也同样存在着独立的生命周期。但是,持久化存储卷和存储卷不同之处在于:持久化存储卷屏蔽了底层存储的实现细节,方便普通的用户使用,同时能方便管理员管理。
Kubernetes的持久化存储卷支持非常多的存储类型,例如gcePersistentDisk、AWSElasticBlockStore、AzureFile、AzureDisk、FC存储、NFS网络文件系统、iSCSI以及GlusterFS等。每种存储类型都有各自的特点,在使用时需要根据它们各自的参数进行设置。
持久化存储卷请求(PersistentVolumeClaim)描述了普通用户对持久化存储卷的需求,由普通用户创建和维护。当普通用户需要为Pod分配存储资源时,就创建一个持久化存储卷请求,指明了自己所需要的存储资源的容量和访问方式等信息,Kubernetes就会自动在集群中查找并提供符合要求的持久化存储卷,提供给Pod使用。
从上面的描述可以得知,在使用持久化存储卷的时候,普通用户只关心自己有多少存储资源以及如何使用存储资源,并不需要关心这些存储资源从何而来,具体的实现方式是什么;而对于管理员来说,只需要根据用户提供的声明的需求,来创建并分配持久化存储卷就可以了。
持久化存储卷及其请求都是Kubernetes的资源,有着自己独立的生命周期。在整个生命周期中,持久化存储卷及其请求相互作用,如图6-1所示。
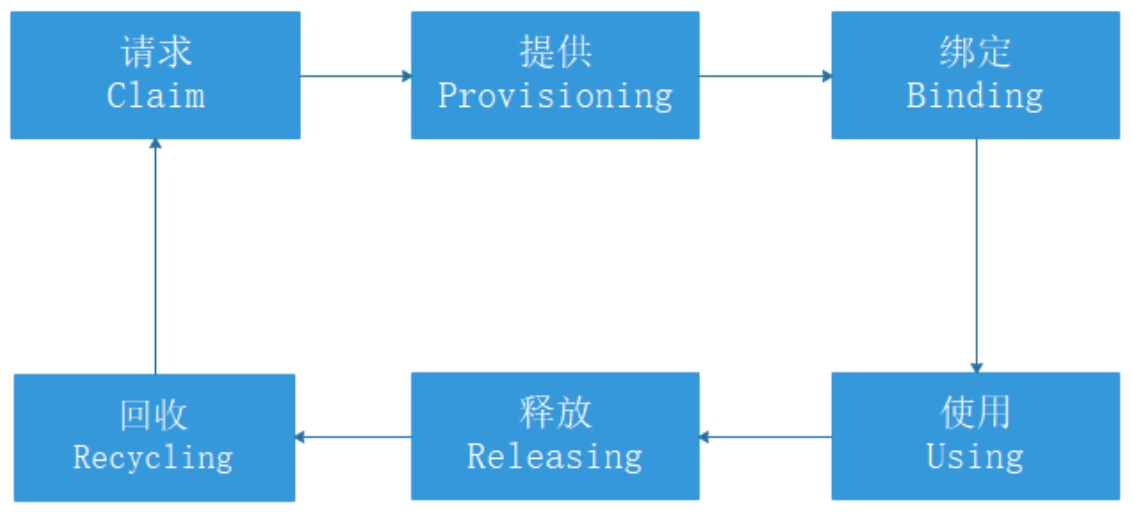
图6-1 持久化存储卷生命周期
管理员可以通过两种方式提供持久化存储卷,分别为静态和动态:
普通用户根据自己的业务需求,在集群中创建存储资源请求,在请求中描述自己对于存储容器以及访问模式。
当用户在集群中发起一个新的存储请求时,Kubernetes的控制器会试图根据请求中的存储大小以及访问模式等条件,查找最合适的存储卷并建立绑定关系。这里“最合适的”意思是存储卷一定满足请求的最低要求,但是也可能比请求的要多。例如,用户请求10GB存储资源,但当前集群中最小的持久化存储卷是15GB,那么这个存储卷也会被分配给用户。
注意
一个持久化存储卷只能绑定给一个用户请求。
Pod把持久化存储卷当作是一个普通的存储卷来使用,与前面介绍的各种存储卷的使用方法并没有明显的区别。关于持久化存储卷的详细使用方法,将在随后介绍。
当用户使用完持久化存储卷后,就可以把发起的请求删除,绑定在该请求上面的持久化存储卷会变成released状态,并准备被回收。
Kubernetes会根据回收策略回收处于released状态的持久化存储卷,目前有3种回收策略:
图6-2描述了容器、持久化存储卷请求以及持久化存储卷之间的关系。从图中可以得知,存储卷的静态绑定可以分为3个部分,其中容器应用调用存储卷请求,存储卷的请求描述了容器对于存储资源的需求,存储卷则是存储资源的提供者。

图6-2 容器应用、存储卷请求以及存储卷之间的关系
下面分别按照这3个部分介绍持久存储卷的静态绑定。
(1)创建应用,YAML配置的代码如下:

其中,第25~26行定义了持久化存储请求的名称为my-pvc。
使用以下命令创建应用:
[root@localhost ~]# kubectl apply -f nginx-deployment.yaml
命令中nginx-deployment.yaml为上面的YAML配置文件的文件名。
(2)定义持久化存储请求,YAML配置文件的内容如下:
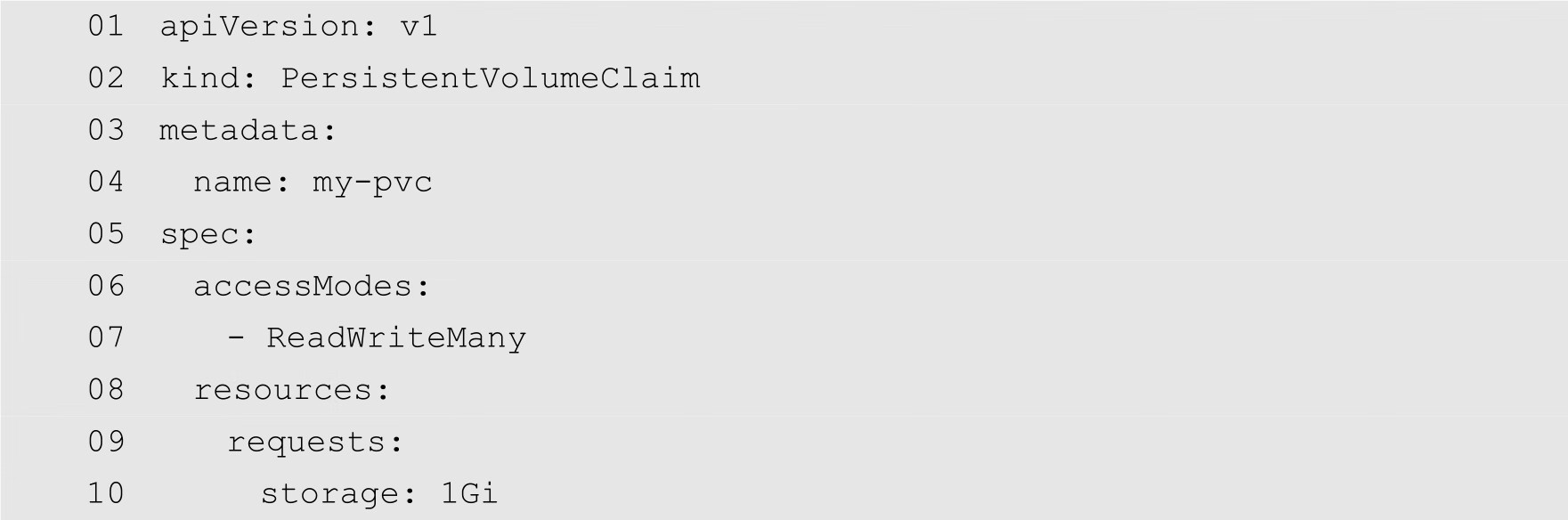
其中,第2行指定资源的类型为PersistentVolumeClaim。第4行定义持久化存储卷的卷名为my-pvc。第7行指定存储卷的访问模式为ReadWriteMany。第10行指定卷的内容为1GB。
使用以下命令创建资源请求,其中my-pvc.yaml为上面YAML文件的文件名:
[root@localhost ~]# kubectl apply -f my-pvc.yaml
(3)定义持久化存储卷,YAML的配置文件如下:
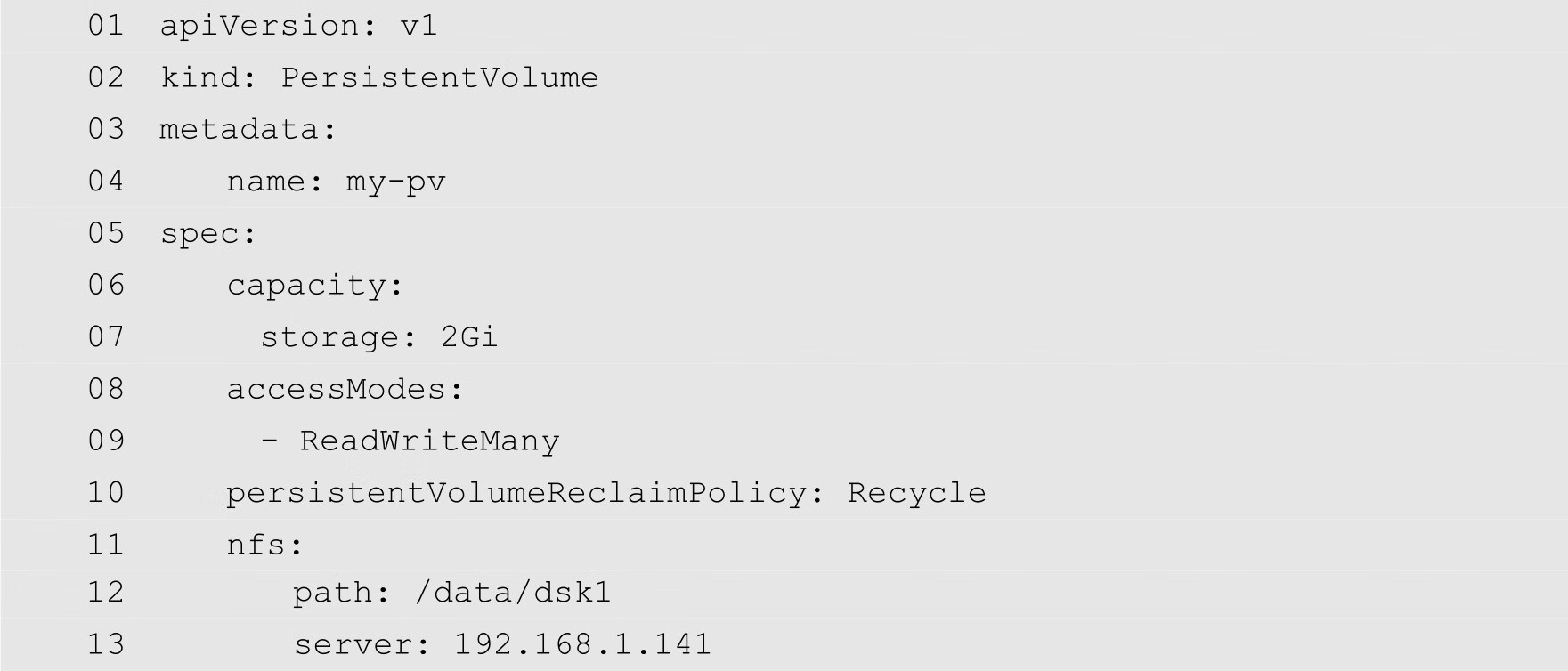
第8行定义了存储卷的访问模式为ReadWriteMany,这个访问模式必须与前面的my-pvc.yaml对存储卷需求的定义完全相同,否则,会出现无法匹配成功的错误。第10行定义了卷的回收策略。
创建持久化存储卷的命令如下:
[root@localhost ~]# kubectl apply -f pv.yaml
创建完成之后,通过以下命令查看持久化存储卷的状态,如下所示:

在上面的输出中,CAPACITY为存储卷的容量,这个卷的容量为2GB。ACCESSMODES为卷的访问模式,RWX表示可读、可写和可执行。RECLAIMPOLICY为回收策略。STATUS为卷的状态,其中Bound表示该卷已经与请求绑定。CLAIM为存储请求的名称,default/my-pvc中的default为命名空间,my-pvc正是我们前面定义的请求的名称。
查看持久化存储请求的状态,如下所示:

STATUS为请求的状态,Bound表示该请求已经与存储卷绑定,VOLUME为存储卷的卷名,my-pv正是我们上面定义的持久化存储卷。CAPACITY为存储容量,其值为2GB。可以发现,在前面的定义中,我们指定了所需要的容量为1GB,但是当前集群中并没有完全符合该请求的存储卷,除了一个容量为2GB的my-pv,所以Kubernetes就把my-pv提供给了my-pvc,这也说明了Kubernetes在将存储请求和存储卷绑定时,采用的是最低匹配原则。ACCESSMODES为访问模式,这个访问模式与前面定义的存储卷的访问模式一致。
最后再查看一下Pod的详细信息,如下所示:
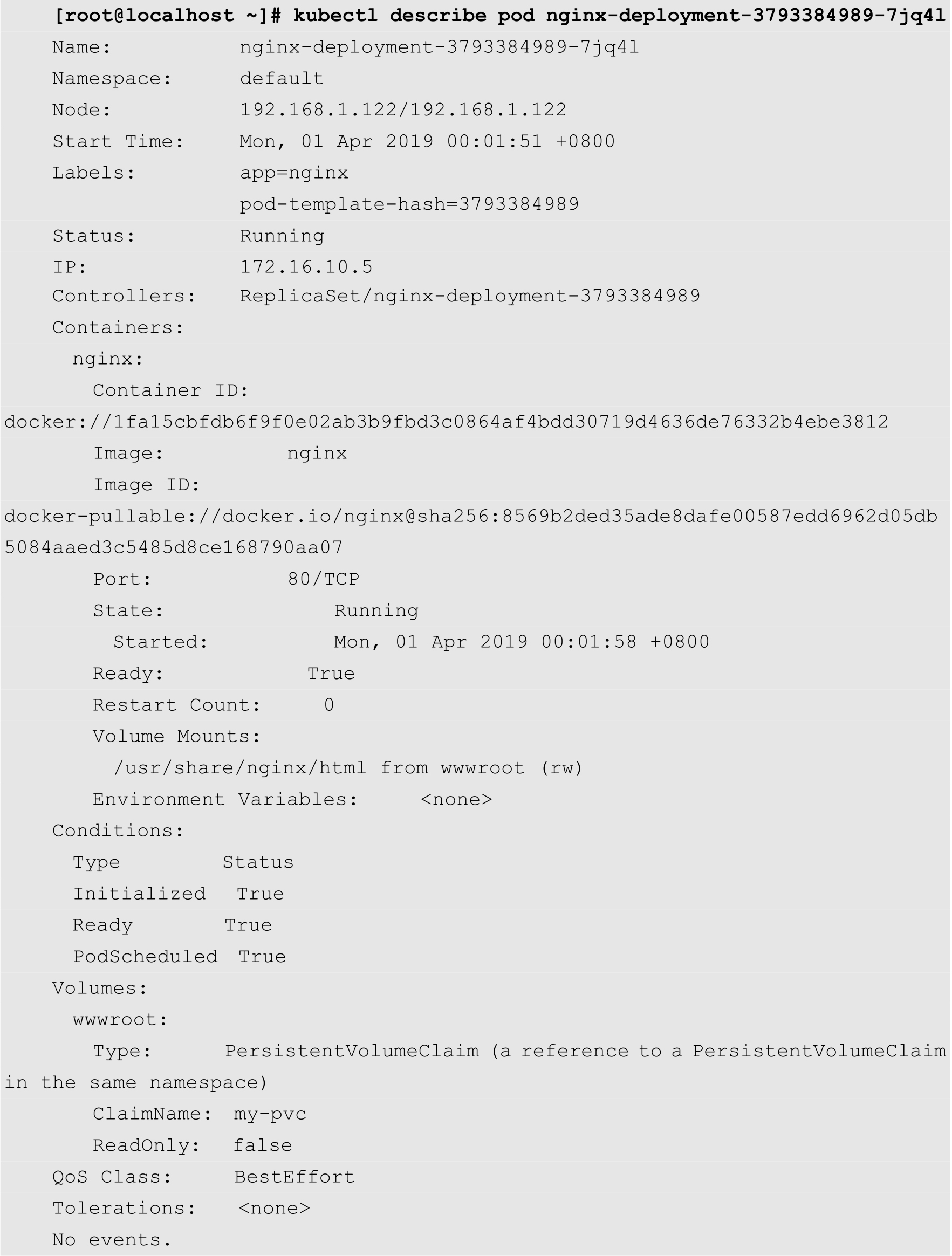
从上面的输出结果可知,该Pod的卷的类型为PersistentVolumeClaim,其卷名为my-pvc。
与静态持久存储卷绑定相比,动态持久存储卷绑定不需要预先创建存储卷,而是通过持久存储卷控制器动态调度,根据用户的存储资源请求,寻找StorageClass定义的、符合要求的底层存储来分配资源。
动态卷供给是Kubernetes独有的功能,这一功能允许按需创建存储卷。在此之前,集群管理员需要事先在集群外由存储提供者或者云提供商创建存储卷,成功之后再创建持久存储卷对象,才能够在Kubernetes中使用。动态卷供给能让集群管理员不必进行预先创建存储卷,而是随着用户需求进行创建。
Kubernetes的持久存储卷绑定采用插件的形式提供。Kubernetes官方内置了非常多的存储供应商的驱动程序(Provisioner),用户可以根据自己的需要来自由选择。
当然,除了内置的驱动程序之外,用户还可以选择另外的后端存储驱动程序。例如NFS或者iSCSI等。下面以NFS作为后端存储卷为例,来介绍动态绑定的方法。
在本例中,我们假定当前网络中已经存在着一个NFS服务器,该服务器的IP地址为192.168.1.141,共享出来的目录为/data/dsk1。
(1)创建Deployment。通过git命令克隆Kubernetes提供的外部存储卷驱动程序代码,如下所示:
[root@localhost ~]# git clone
https://github.com/kubernetes-incubator/external-storage
克隆完成之后,进入external-storage目录下的nfs-client目录,命令如下:
[root@localhost ~]# cd external-storage/ [root@localhost external-storage]# cd nfs-client
然后修改deploy目录中的deployment.yaml配置文件,代码如下:

在上面的代码中,用户需要修改的地方主要是NFS服务器的IP地址和共享目录的路径,在本例中为第25、27、31和32行。其余的保留默认值即可。修改完成之后,使用以下命令创建Deployment:
[root@localhost ~]# kubectl apply -f deploy/deployment.yaml
(2)创建StorageClass。修改StorageClass配置文件,即deploy目录中的class.yaml,其代码如下:

然后使用以下命令创建StorageClass:
[root@localhost ~]# kubectl apply -f deploy/class.yaml
使用以下命令查看刚刚创建的StorageClass的状态,如下所示:

(3)授权。用户需要执行以下命令进行授权:

(4)创建持久化存储卷请求。Kubernetes已经为用户提供了一个创建测试持久化存储卷请求的配置文件,其文件名为deploy/test-claim.yaml,代码如下:
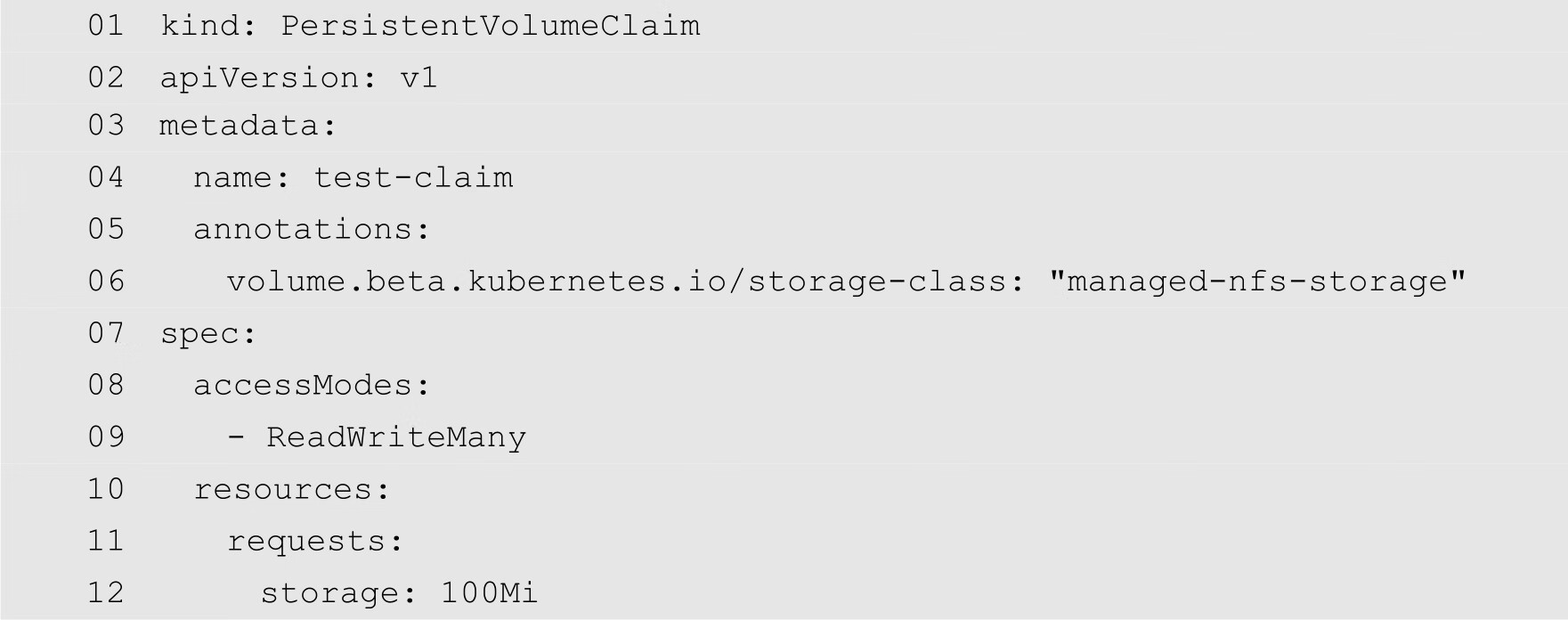
上面代码的第1行指定要创建的资源类型为PersistentVolumeClaim。第6行通过volume.beta.kubernetes.io/storage-class注解,定义对应的StorageClass为managed-nfs-storage。第12行指定请求的存储空间为100MB。
创建请求的命令如下:
[root@localhost ~]# kubectl apply -f deploy/test-claim.yaml
创建完成后,使用以下命令查看其状态:

可以发现,存储卷请求的状态已经变成Bound,其存储容量为100Mi,其StorageClass为managed-nfs-storage。
查看存储卷是否被自动创建,命令如下:

从上面的输出结果可知,Kubernetes根据用户请求,自动创建了一个持久化存储卷。
(5)创建测试Pod。修改deploy目录中的test-pod.yaml文件,代码如下:
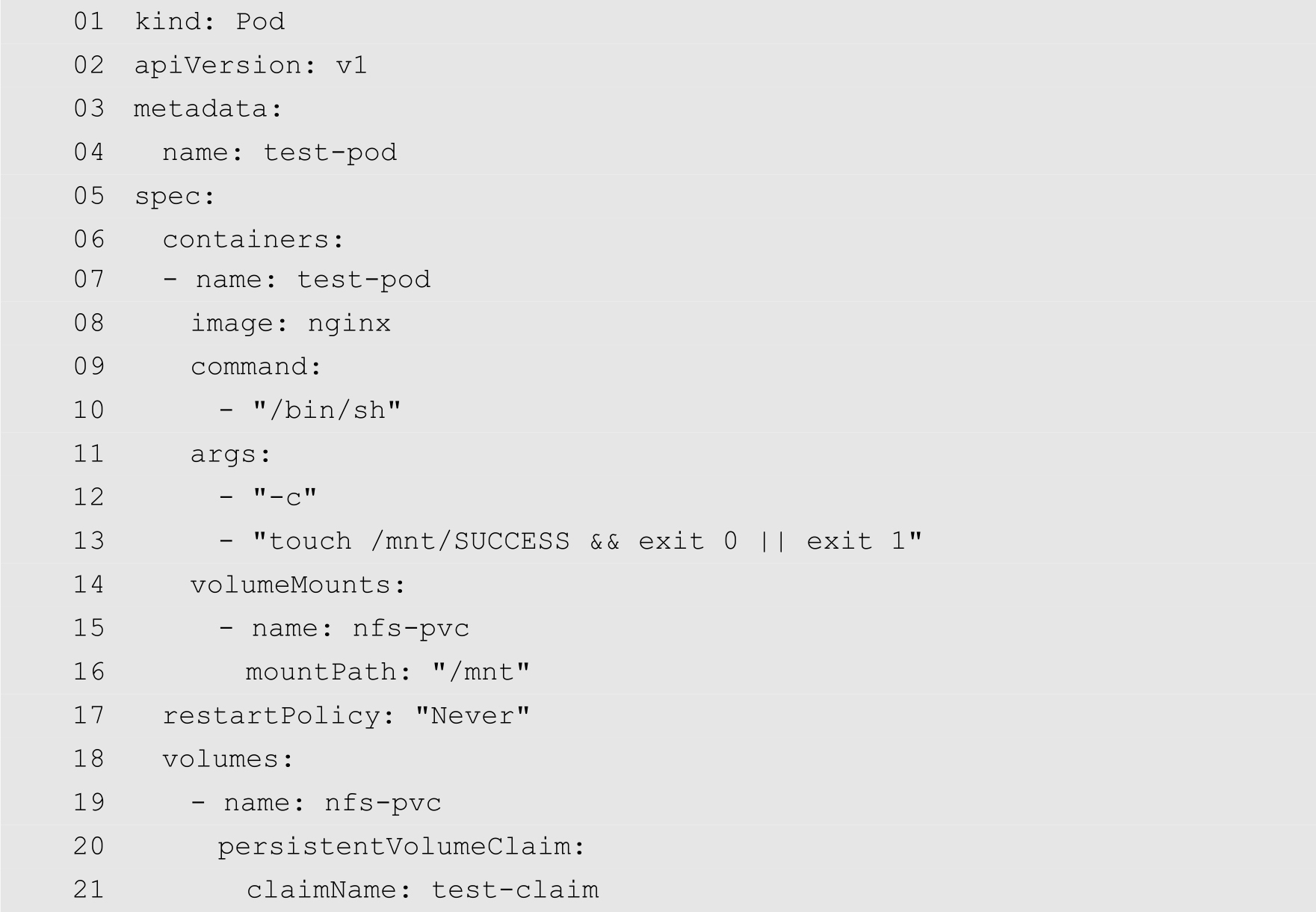
在上面的代码中,第13行在容器创建完成之后,通过touch命令在/mnt目录中创建一个名为SUCCESS的文件。第14~16行定义存储卷的挂载,将名为nfs-pvc的存储卷挂载到/mnt上面。第18~21行定义存储卷,其中存储卷请求引用前面定义的test-claim。
创建Pod的命令如下:
[root@localhost ~]# kubectl apply -f deploy/test-pod.yaml
查看Pod状态,如下所示:

从上面的输出可知,test-pod已经处于完成状态。然后进入NFS服务器中的共享目录,查看是否SUCCESS文件:

从上面的输出结果可知,SUCCESS文件已经被成功创建,这意味着Pod已经可以正常使用存储卷来存储数据了。同时,在整个过程中,我们并没有人工创建存储卷,只是创建了一个存储卷请求,Kubernetes会自动根据请求创建持久化存储卷。
用户可以通过删除持久化存储卷请求来达到回收存储资源的目的。存储资源请求被删除之后,持久化存储卷将变成released状态。由于还保留着之前的数据,这些数据需要根据不同的策略来处理,否则这些存储资源无法被其他存储资源请求使用。
对于持久化存储卷来说,用户可以指定3种回收策略。下面分别介绍这些回收策略的使用方法。
在该种回收策略下,Kubernetes允许用户手工回收存储资源,即当存储卷请求被删除后,存储卷将仍然存在,只是状态将会转换为已释放状态。对于其他的存储卷请求来说,处于已释放状态的是不可用的,因为以前的数据仍然保留在数据卷中。
我们以前面的静态绑定的持久化存储卷为例,来说明在保留策略情况下,删除Pod以及存储资源请求时数据状态的变化。
首先执行以下命令,在容器内部查看存储卷里面的数据,如下所示:

可以发现,在上面的存储卷中,一共有2个文件。
执行以下命令删除Pod:
[root@localhost ~]# kubectl delete -f nginx-deployment.yaml deployment "nginx-deployment" deleted
查看存储卷请求是否依然存在,如下所示:

可以得知,尽管Pod被删除,但是存储卷请求依然存在。
继续删除存储卷请求,命令如下:
[root@localhost ~]# kubectl delete -f my-pvc.yaml persistentvolumeclaim "my-pvc" deleted
查看存储卷的状态,如下所示:

可以发现存储卷依然存在,只是STATUS的值由Bound转变为Released。
登录到NFS服务器,查看存储卷保存在服务器上面的数据是否被删除,如下所示:

从上面的输出结果可知,在存储卷请求被删除的情况下,存储卷的状态转换为释放状态,但是Pod存储NFS服务器上的文件依然存在。
继续删除持久化存储卷,命令如下:
[root@localhost ~]# kubectl delete -f pv.yaml persistentvolume "my-pv" deleted
删除完成之后,再次在NFS服务器上面查询Pod存储的文件是否依然存在:

可以发现,尽管持久化存储卷也被删除,但是存储在外部存储上面的文件,并没有随着存储卷的删除而被删除。这意味着在保留策略下,用户数据并不会随着相关资源的删除而被删除,其生命周期是独立的。
在数据确实不再需要的情况下,为了释放存储空间,用户需要手工在NFS服务器上面将文件删除。
在上面操作中,当Pod被删除后,存储卷请求是可以重用的,即如果在集群中,重新创建一个Pod,可以直接将刚才的存储卷请求挂载。但是,当存储卷请求被删除,持久化存储卷的状态转换为释放状态时,即使当前集群中存在着符合条件的请求,该存储卷也不会被绑定。在存储卷被删除的时候,如果用户想要继续访问NFS服务器上的文件,可以重新创建存储卷,然后重新绑定请求。
如果持久化存储采用了循环回收策略,则在删除该卷时,存储在卷中的数据将被删除,使得存储卷可以与新的请求绑定。该策略将会在后面的版本中删除,建议使用动态绑定的方式来代替该策略。
对于支持删除回收策略的存储卷插件,从集群中删除持久化存储卷的时候,也会从相关的外部设施中删除存储资产。
对于动态绑定来说,只支持删除策略。也就是说,如果采用动态绑定,在删除存储卷的时候,存储在外部存储,如NFS上面的所有数据都将被删除。