
通过前面几章的学习,读者应该对Kubernetes有了充分的认识。Kubernetes作为一种容器编排引擎,最重要的功能就是管理好容器,提供各种服务。在本章中,我们将详细介绍如何在Kubernetes中部署各种容器化应用。
本章涉及的知识点主要有:
Deployment提供了一种更加简单的、更新Replication Controller和Pod的机制,更好地解决了Pod的编排问题。本节将详细介绍如何通过Deployment实现Pod的管理。
Deployment的中文意思为部署、调度,它是在Kubernetes的版本1.2中新增加的一个核心概念。Deployment的实现为用户管理Pod提供了一种更为便捷的方式。用户可以通过在Deployment中描述所期望的集群状态,Deployment会将现在的集群状态在一个可控的速度下逐步更新成所期望的集群状态。与Replication Controller基本一样,Deployment主要职责同样是为了保证Pod的数量和健康。Deployment的绝大部分的功能与Replication Controller完全一样,因此,用户可以将Deployment看作是升级版的Replication Controller。
与Replication Controller相比,除了继承Replication Controller的全部功能之外,Deployment还有以下新的特性:
说到ReplicaSet对象,还是不得不提Replication Controller。在Kubernetes v1.16之前,只有Replication Controller对象,它的主要作用是确保Pod以用户指定的副本数运行,即如果有容器异常退出,Replication Controller会自动创建新的Pod来替代,而异常多出来的容器也会自动回收。可以说,通过Replication Controller,Kubernetes实现了集群的高可用性。
在新版本的Kubernetes中,建议使用ReplicaSet来取代Replication Controller。ReplicaSet跟Replication Controller没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的选择器,而Replication Controller只支持等式选择器。
虽然ReplicaSet也可以独立使用,但是Kubernetes并不建议用户直接操作ReplicaSet对象。而是通过更高层次的对象Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题,比如ReplicaSet不支持滚动更新,但Deployment支持,并且Deployment还支持版本记录、回滚、暂停升级等高级特性。这意味着用户几乎不会有机会去直接管理ReplicaSet。
注意
用户不该手动管理由Deployment创建的ReplicaSet,否则就“篡越”了Deployment的职责。
我们先从一个最简单的例子开始,介绍如何运行Deployment,命令如下:
在上面的命令中,nginx-deployment是要创建的Deployment的名称,--image选项用来指定容器所使用的镜像,其中nginx为镜像名称,1.7.9为版本号。replicas选项用来指定Pod的副本数为3,即当前集群中在任何时候都要保证有3个Nginx的副本在运行。
执行完命令之后,用户可以通过get命令查看刚才运行的Deployment,如下所示:

在上面的输出结果中,DESIRED表示预期的副本数,即我们在命令中通过--replicas参数指定的数量。CURRENT表示当前的副本数。实际上CURRENT是Deployment所创建的ReplicaSet里面的Replica的值,在部署的过程中,这个数值会不断增加,一直增加到DESIRED所指定的值为止。UP-TO-DATE表示当前已经处于最新版本的Pod的副本数,主要用于在滚动升级的过程中,表示当前已经有多少个副本已经成功升级。AVAILABLE表示当前集群中属于当前Deployment的、可用的Pod的副本数量,实际上就是当前Deployment所产生的,在当前集群中存活的Pod的数量。AGE表示当前Deployment的年龄,即从创建到现在的时间差。
接下来我们通过describe deployment命令查看当前Deployment更加详细的信息,如下所示:
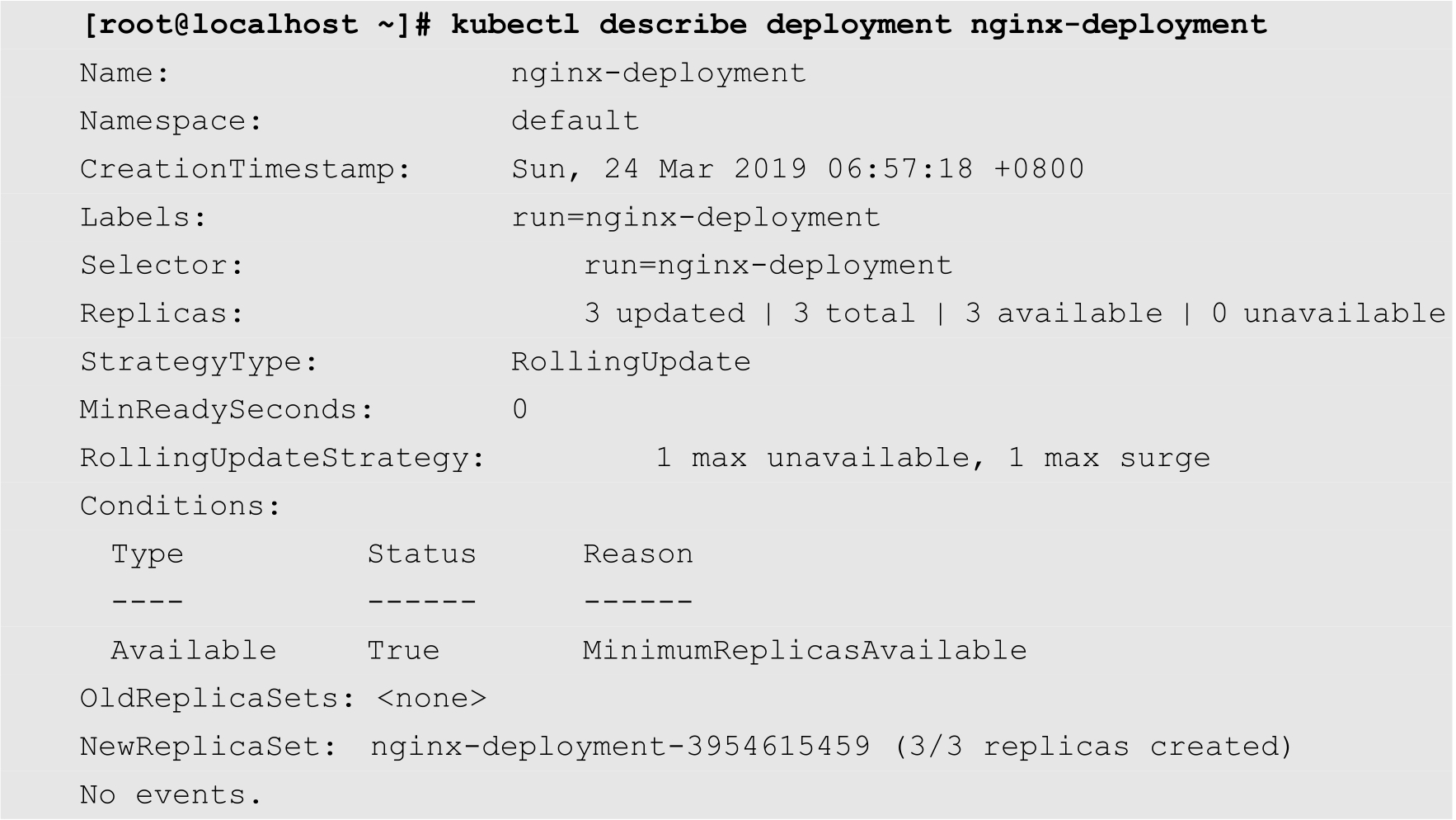
上面的输出信息的含义大部分都非常明确,我们重点关注几点即可。首先Namespace表示当前Deployment所属的命名空间为default,即缺省的命名空间。Replicas表示当前Pod的副本信息。NewReplicaSet表示由Deployment自动创建的ReplicaSet,其名称为nginx-deployment-3954615459,可以发现实际上ReplicaSet的名称使用所属的Deployment的名称作为前缀,这样可以非常容易地分辨这个ReplicaSet是由哪个Deployment创建的。
前面已经介绍过的ReplicaSet是一个非常重要的概念,而且用户几乎不会直接操作ReplicaSet,可以通过Deployment间接地管理它。下面我们通过get replicaset命令来查看ReplicaSet的信息,如下所示:

在上面的输出信息中,ReplicaSet的名为nginx-deployment-3954615459,READY表示当前已经就绪的副本数。
为了了解更多的关于nginx-deployment-3954615459的信息,可以使用describe replicaset命令,如下所示:
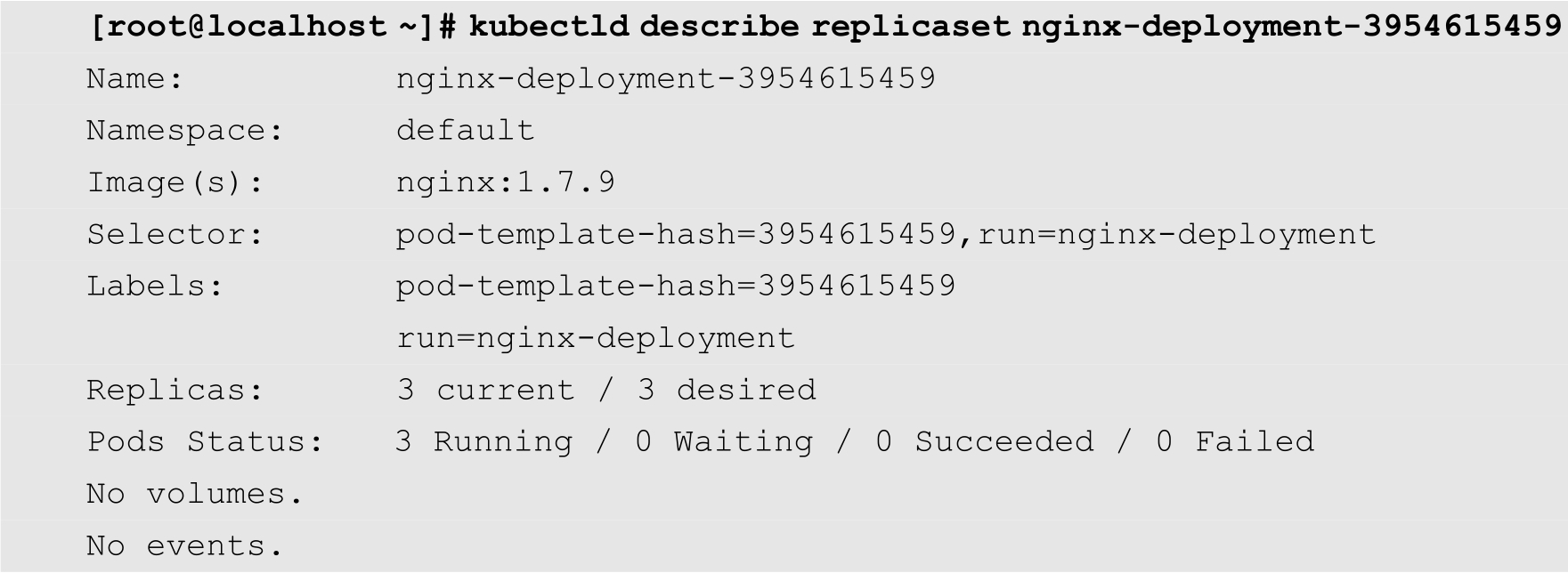
Image表示容器所使用的镜像为nginx:1.7.9,Replicas表示副本数,Pods Status表示当前Deployment所创建的Pod的状态,可以看到有3个副本处于运行(Running)状态,没有处于等待(Waiting)、结束(Succeeded)或者失败(Failed)的Pod。
接下来,我们继续探讨Deployment所创建的Pod。执行get pod命令,获取当前集群中的Pod信息,如下所示:

从上面的输出结果可知,3个Pod副本都处于运行状态。另外,Kubernetes还为每个Pod自动分配了IP地址。其中1个副本运行在名称为192.168.1.122的节点上面,2个副本运行在名称为127.0.0.1的节点上。为了便于维护,Pod的命名规则也是以Deployment的名称以及ReplicaSet的名称作为前缀的。由此可以推断出,在同一个节点上面,可以同时运行一个Pod的多个副本。
前面已经介绍过,Kubernetes中的各种服务最终是由Pod里面的容器提供的。因此,了解Pod及其容器是我们的最终目标。所以,下面通过kubectl describe pod命令查看其中某个Pod副本的详细信息,如下所示:



该命令的输出信息非常多,我们只要关注其中重要的部分即可。Node表示当前Pod所处的节点。IP是Kubernetes为当前Pod副本分配的IP地址,用户可以通过该IP地址与Pod通信。Controllers表示当前Pod由哪个Deployment和ReplicaSet创建,在本例中,Deployment的名称为nginx-deployment,ReplicaSet的名称为nginx-deployment-3954615459。Containers表示当前Pod中的容器的列表,本例中只有一个用户容器,其容器ID为docker://df381a4ea070522 af06d897d0c49a253def23ac7264a8b5bc3b50fbe67e86b6a。Events为当前Pod副本的日志信息,便于用户调试。
最后,我们的关注点落在了容器上。由于nginx-deployment-3954615459-4zp22当前运行在名为192.168.1.122的节点上,因此我们登录到192.168.1.122。然后使用前面介绍的容器管理命令docker ps,查看当前节点的容器列表,如下所示:
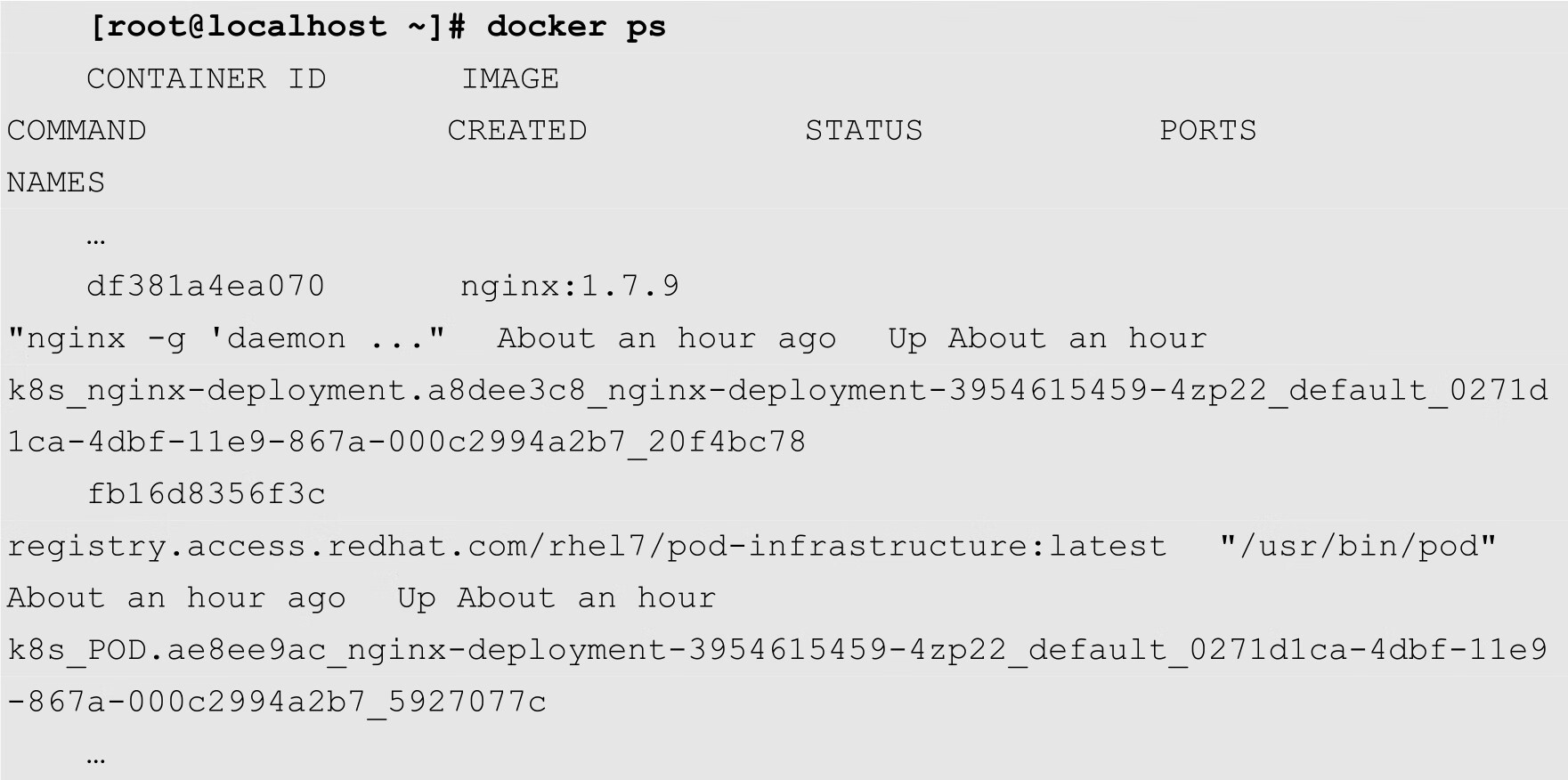
可以看到,在192.168.1.122节点上面有2个容器,这2个容器都是由nginx-deployment创建的。还记得我们前面介绍的Pod的结构吗?在每个Pod中,都存在着一个名为Pause的根容器,这个根容器是Kubernetes系统的一部分。在上面的容器列表中,ID为df381a4ea070的是用户容器,而ID为fb16d8356f3c即为当前Pod的根容器。
用户可以通过docker inspect命令查看容器的详细信息,如下所示:

由于这部分内容在前面已经详细介绍过,这里不再重复赘述。
至此,我们已经成功地运行了一个Deployment。总结前面的内容,我们可以发现创建Deployment的大致流程。首先,用户通过kubectl run deployment命令创建一个Deployment。接下来,Deployment会自动根据用户指定的选项,主要是image以及replicas等创建ReplicaSet。最后,由ReplicaSet创建Pod副本和容器。所以,整个流程如图4-1所示。
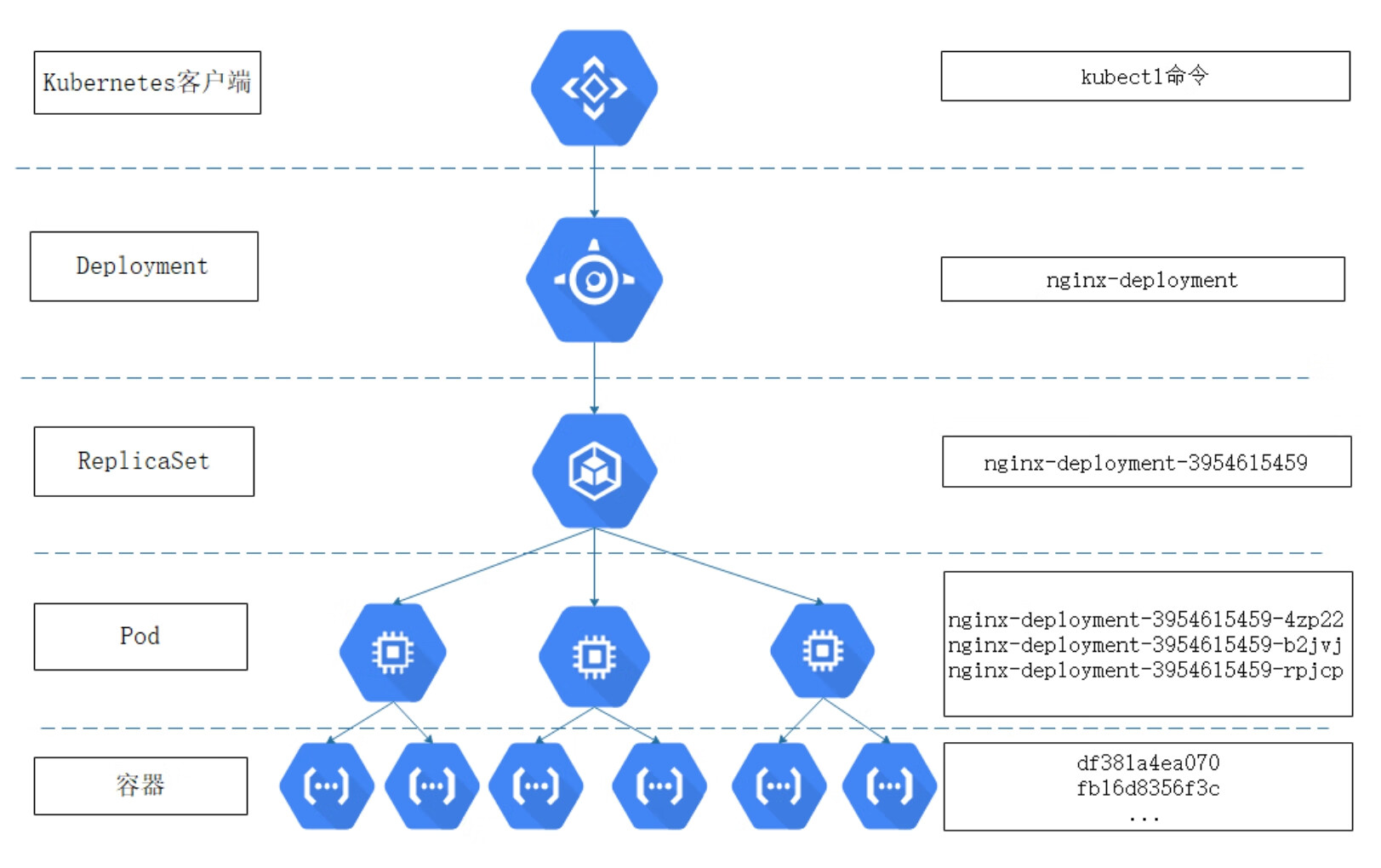
图4-1 Deployment创建过程
读者可能会问,我们刚才创建的应用能够提供服务吗?下面我们通过简单的方法来进行验证。刚才我们部署的是一套Nginx应用。Nginx是用来提供各种网络服务的,例如HTTP网页服务、反向代理或者网络加速等。这里,我们可以通过curl命令来简单测试一下Nginx是否运行正常。默认情况下Nginx的服务端口为80,提供HTTP访问。我们在任意节点上面执行以下命令:
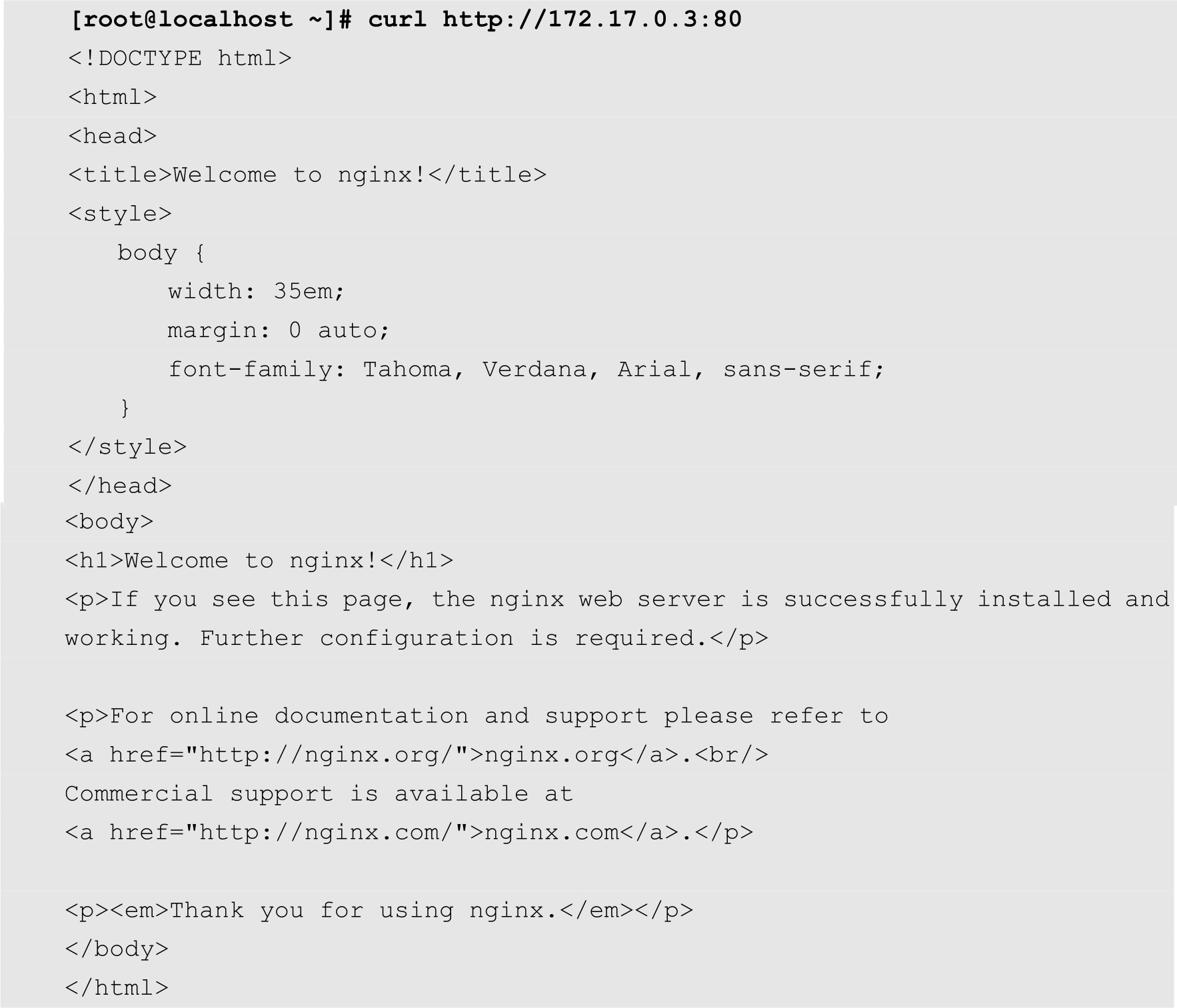
curl命令是一个功能强大的文件传输工具,它支持文件的上传和下载。172.17.0.3为节点192.168.1.122上Pod的IP地址。可以发现,Nginx已经可以返回默认的欢迎页面的内容。这表示我们的部署是成功的。
在前面的例子中,我们直接通过kubectl命令创建了一个Nginx的Deployment。可以发现,在使用kubectl命令创建资源时,需要提供较多的选项来限制资源的各种属性。实际上,Kubernetes支持两种方式来定义资源属性,其中一种就是直接在命令行中通过对应的选项来指定,例如,前面的--image=nginx:1.7.3和--relicas=3分别用来指定镜像文件和副本数。还有一种方式就是通过配置文件。Kubernetes支持多种类型的配置文件,常见的有YAML和JSON。
YAML是一个可读性高,用来表达数据和信息序列的编程语言。YAML参考了其他多种语言,包括XML、C语言、Python、Perl以及电子邮件格式RFC2822。YAML强调这种语言以数据为中心,而不是以标记语言为重点。
YAML文件的后缀可以使用.yml,也可以使用.yaml,官方推荐使用.yaml。Kubernetes里所有的资源或者配置文件都可以用YAML或JSON定义。YAML是JSON的超集,任何有效的JSON文件也都是一个有效的YAML文件。
YAML文件具有以下语法规范:
YAML有两种比较重要的数据结构,分别为Map和List,用户只要掌握好这两种数据结构就可以了。
首先介绍一下Map。跟其他的程序设计语言一样,Map类型的数据结构通常就是一个“键-值对”(Key-Value Pair)。用户可以非常方便地通过键去引用和修改其对应的值。例如,下面的代码为一个YAML的部分内容:
apiVersion: v1 kind: Pod
在上面的代码中,apiVersion为键,v1为其对应的值,表示Kubernetes的API的版本。kind同样为键,Pod为值,表示资源类型为Pod。当然,用户可以将其转换为具有相同含义的JSON格式,如下所示:

当然,Map中的值可以是复杂类型。例如,可以是另外一个Map类型的数据结构,如下所示:

在上面的代码中,键metadata的值为一个拥有2个键的Map。上面的代码可以转换为以下JSON代码:

除了Map之外,在表示资源属性时还需要用到一些并列的数据结构,这种情况下,需要使用YAML的List。例如,下面的代码就是一个典型的List结构:

正如你看到的那样,List中的列表项的定义以破折号开头,并且与父元素之间存在缩进关系。在JSON格式中,它将表示如下:

当然,Map的键值可以是List结构,List的列表项也可以是Map结构,如下所示:
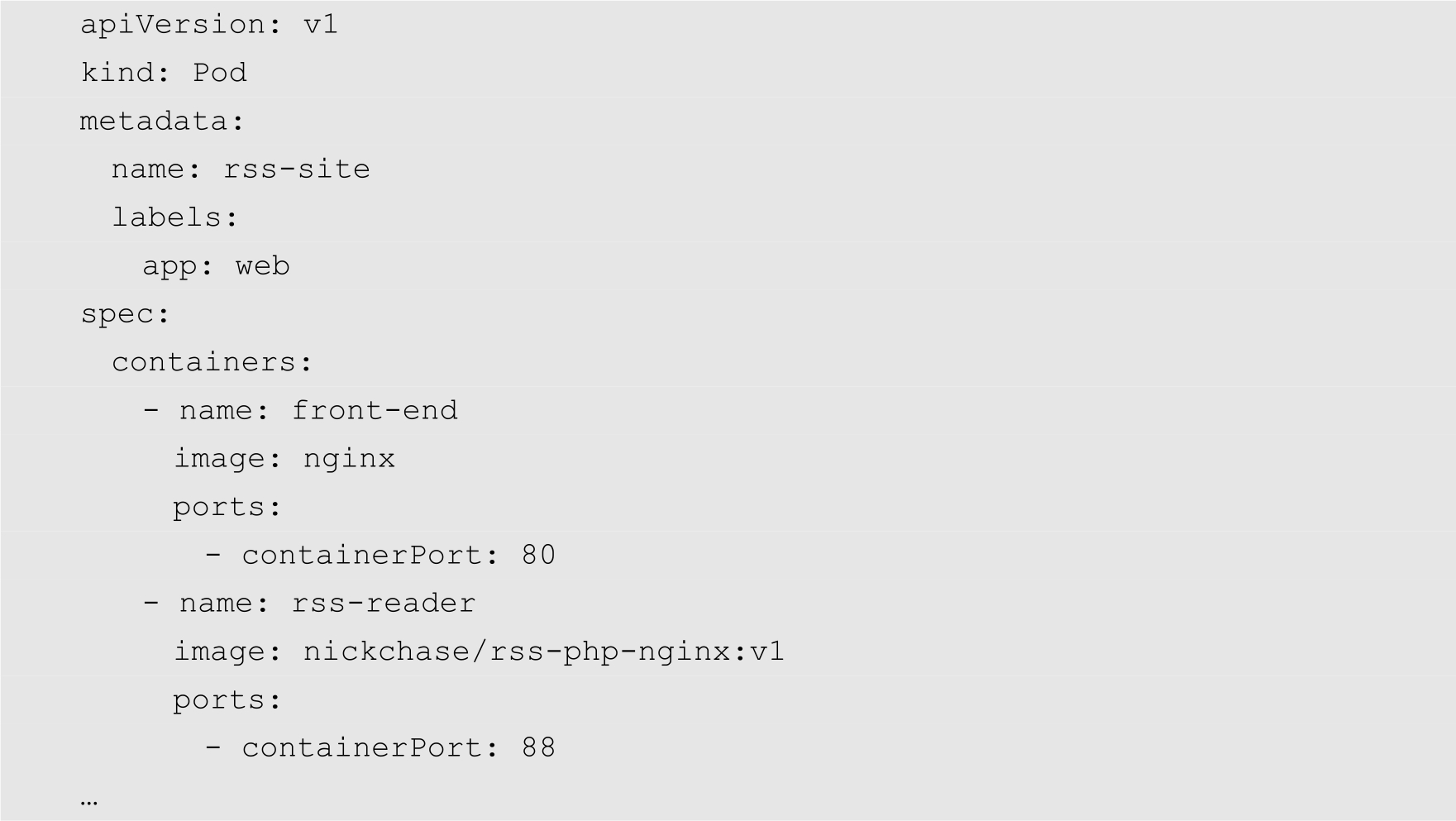
以上YAML的代码转换为JSON后的结构如下:

在了解了YAML的基本语法之后,下面介绍一下Deployment中YAML的常见格式,如下所示:
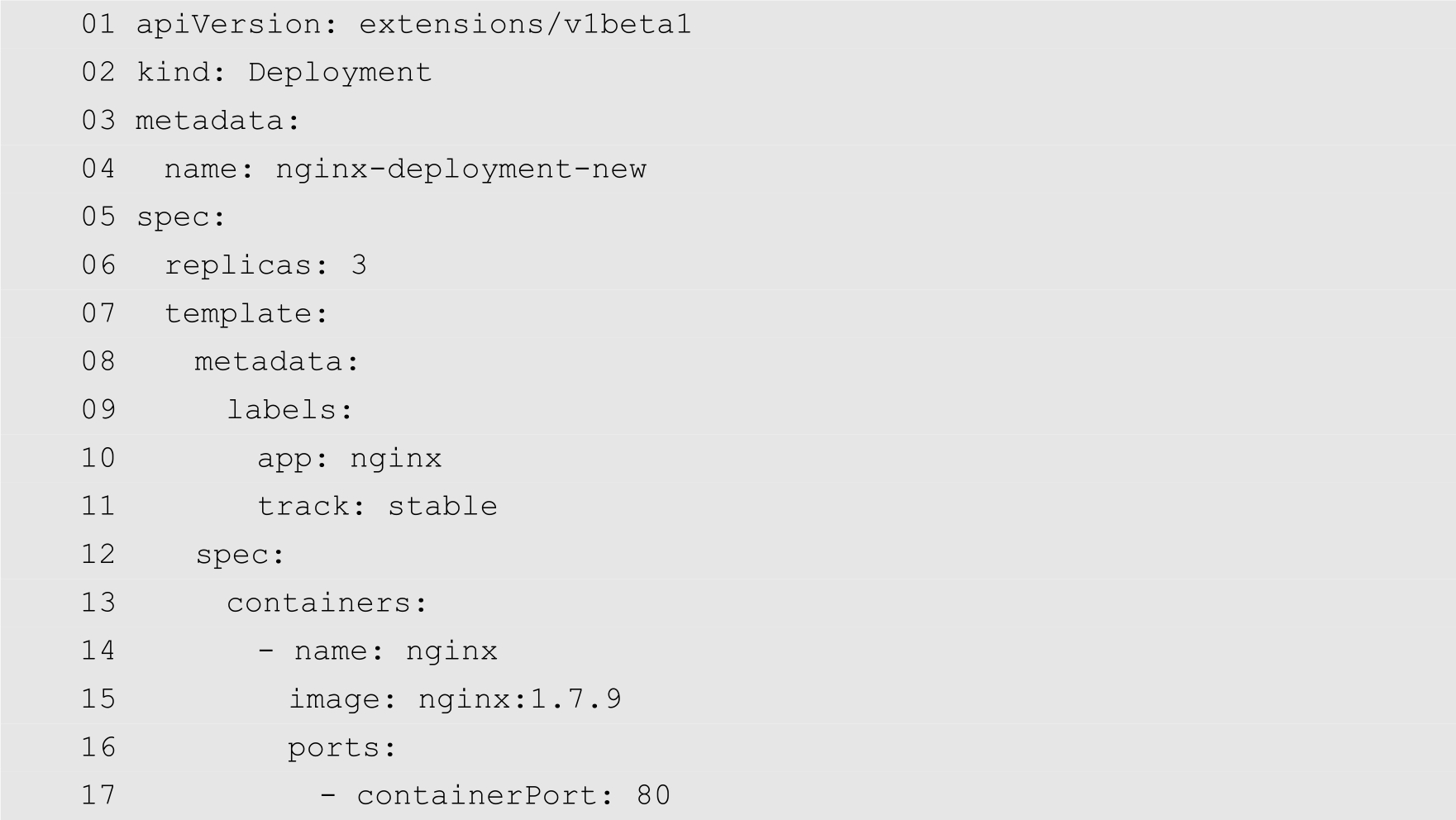
第1行的apiVersion表示当前配置文件格式的版本号。第2行kind指定当前的资源类型为Deployment。第3行metadata用来定义Deployment本身的属性,其中name表示Deployment的名称。第5行的spec用来定义Deployment的规格。用户需要正确区分metadata和spec,前者表示Deployment本身固有的属性,后者表示Deployment内容的各项属性。第6行的replicas表示Pod的副本数。从第7行开始定义Pod的模板的各项属性,其中第10行定义Pod的标签;第12行开始定义Pod中的容器的各项属性,其中name为容器名,image为容器镜像文件,这2个属性是必需的。
将以上代码保存为nginx-deployment.yaml,然后通过以下命令创建Deployment:
[root@localhost ~]# kubectl apply -f nginx-deployment.yaml deployment "nginx-deployment-new" created
执行完成之后,用户就可以查看nginx-deployment-new所创建的各种资源,如下所示:
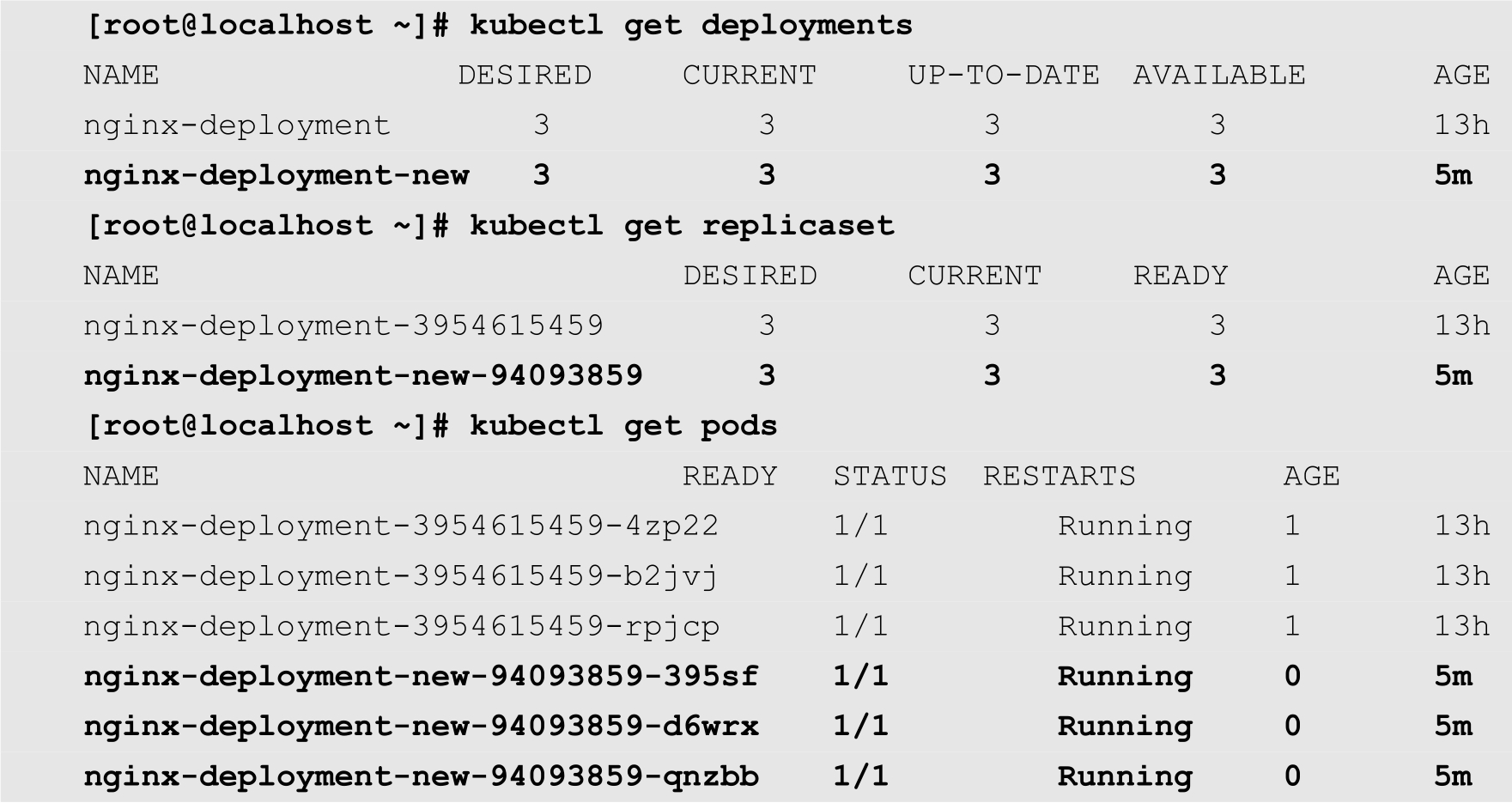
可以发现,使用命令行参数和配置文件都可以帮助用户创建各种资源。命令行参数使用起来非常便捷,用户不需要花费时间去编辑YAML文件。而使用YAML配置文件也有着明显的优势:
(1)配置文件非常详细地描述了我们想要创建的资源以及最终要达到的状态。
(2)配置文件提供了创建资源的模板,可以重复利用。
(3)由于配置文件可以长久地存储在磁盘上面,因此用户可以像管理代码一样管理部署。
(4)配置文件非常适合于正式的、跨环境的以及大规模的部署。
因此,用户应该尽可能地使用配置文件来创建各类资源。
扩容和缩容是指在线增加或者减少Pod的副本数量。在前面的例子中,我们指定了3个Nginx副本,如下所示:
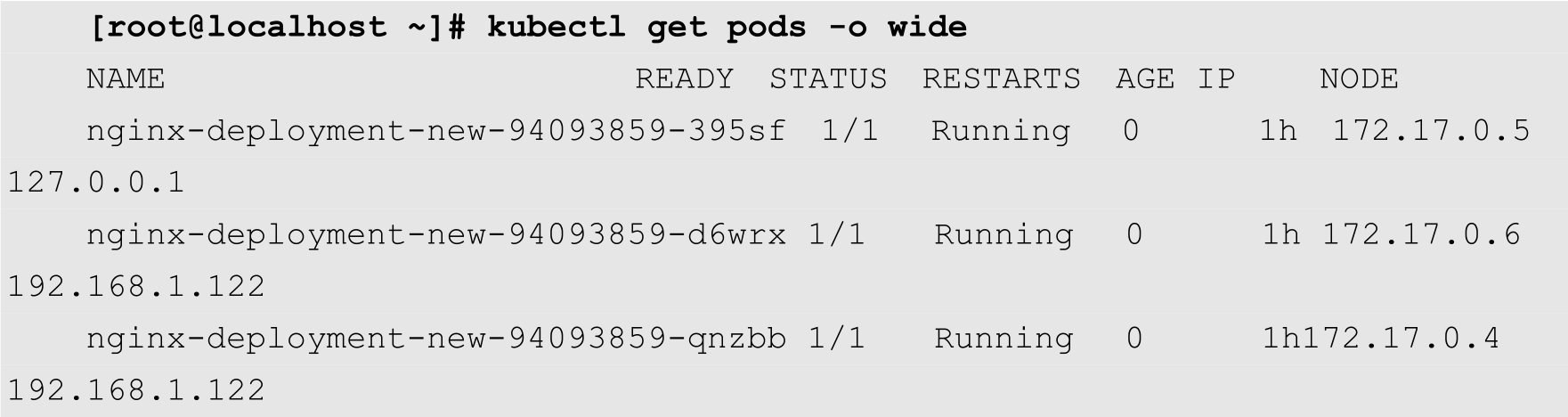
这3个副本中,有1个副本运行在节点127.0.0.1上,2个副本运行在192.168.1.122上。下面我们修改nginx-deployment.yaml配置文件,增加一个副本:
然后执行以下命令更新Deployment:

从上面的命令可知,当前Deployment的预期副本数已经变成4,当前可用的副本数也为4。为了验证详细的Pod副本数量,用户可以使用kubectl describe pods命令,如下所示:

从上面的输出结果可知,当前的Deployment有4个副本,其中127.0.0.1和192.168.1.122上各有2个。这意味着Kubernetes根据修改后的配置文件,新增了一个副本,并且将其调度在127.0.0.1节点上运行。
Deployment的扩容也可以通过命令行快速完成,这需要使用kubectl scale命令,在该命令中指定需要扩展到的副本数,如下所示:

上面的命令将副本数扩大到5,执行完成后查看Pod信息,如下所示:
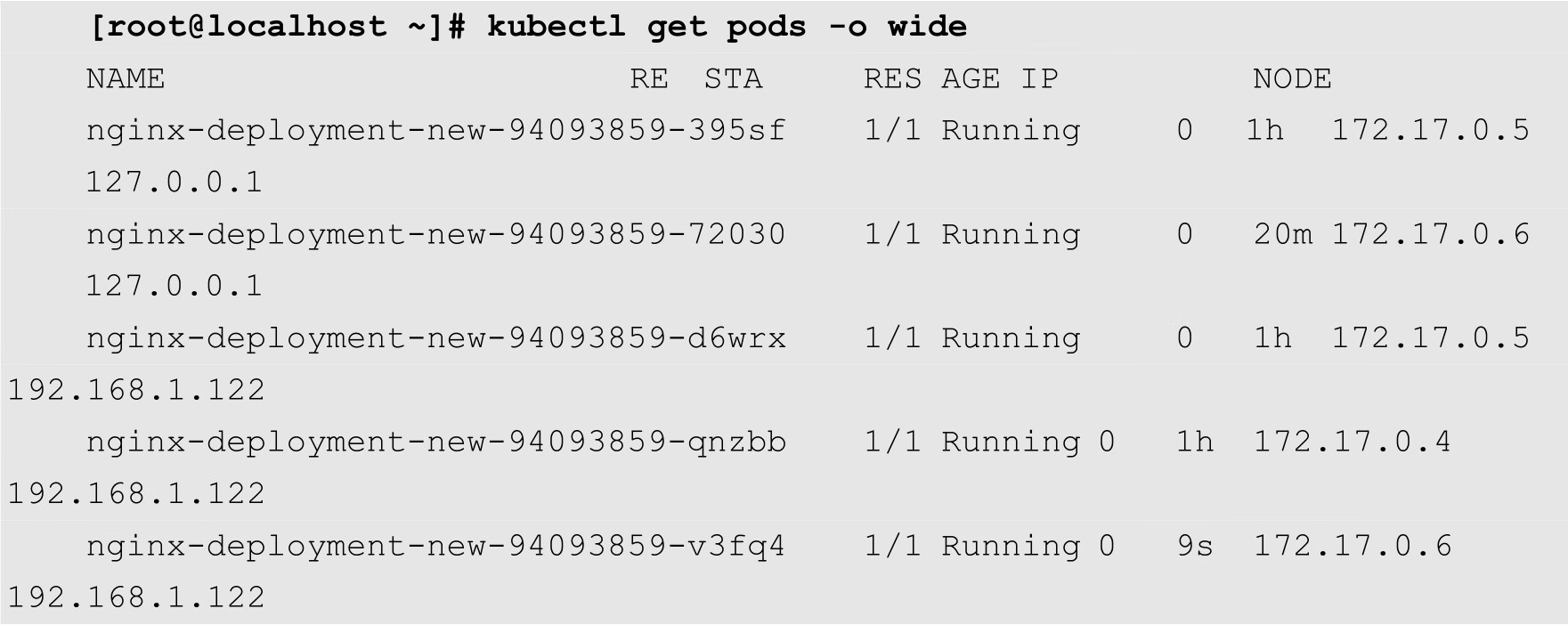
从上面的输出结果可知,Pod副本数已经变成了5个。
Deployment的缩容的操作与扩容相反。为了减少副本数量,用户需要修改nginx-deployment.yaml配置文件,将其中的replicas修改为3,然后执行kubectl apply命令,即可完成缩容操作,如下所示:
[root@localhost ~]# kubectl apply -f nginx-deployment2.yaml deployment "nginx-deployment-new" configured
执行完成之后,通过kubectl get pods命令查看执行结果,如下所示:

可以看到有2个副本已经被删除,只保留了3个副本。
同样的操作也可以使用命令行完成,如下所示:

读者可以自行验证,此处不再赘述。
注意
用户可以将Pod副本数缩容为0,但是,在这种情况下Deployment本身不会被删除,只是可用副本数将会变成0。
Kubernetes支持故障转移,保证集群中的各项服务的可用性。在Kubernetes中,Node节点可动态增加到Kubernetes集群中,前提是这个节点已经正确安装、配置、启动了kubelet和kube-proxy等关键进程。默认情况下,kubelet会向Master节点注册自己,这也是Kubernetes推荐的Node节点管理方式。一旦Node节点被纳入集群管理的范围,kubelet会定时向Master节点汇报自身的情况,以及之前有哪些Pod在运行等,这样Master节点可以获知每个Node节点的资源使用情况,并实现高效均衡的资源调度策略。如果Node节点没有按时上报信息,则会被Master判断节点为失联,Node节点状态会被标记为Not Ready,随后Master节点会触发工作负载转移流程。
下面的内容模拟一次Node节点故障。首先确认nginx-deployment-new所创建的Pod有4个副本,其中2个副本运行在127.0.0.1节点上,2个副本运行在192.168.1.122上,如下所示:

然后将名为192.168.1.122的节点关闭,过一会儿,Master节点会将192.168.1.122标记为NotReady,如下所示:

再等待一会,Master节点会将原来运行在192.168.1.122上的2个副本标记为Unknown状态,然后在127.0.0.1节点上新创建2个副本,如下所示:
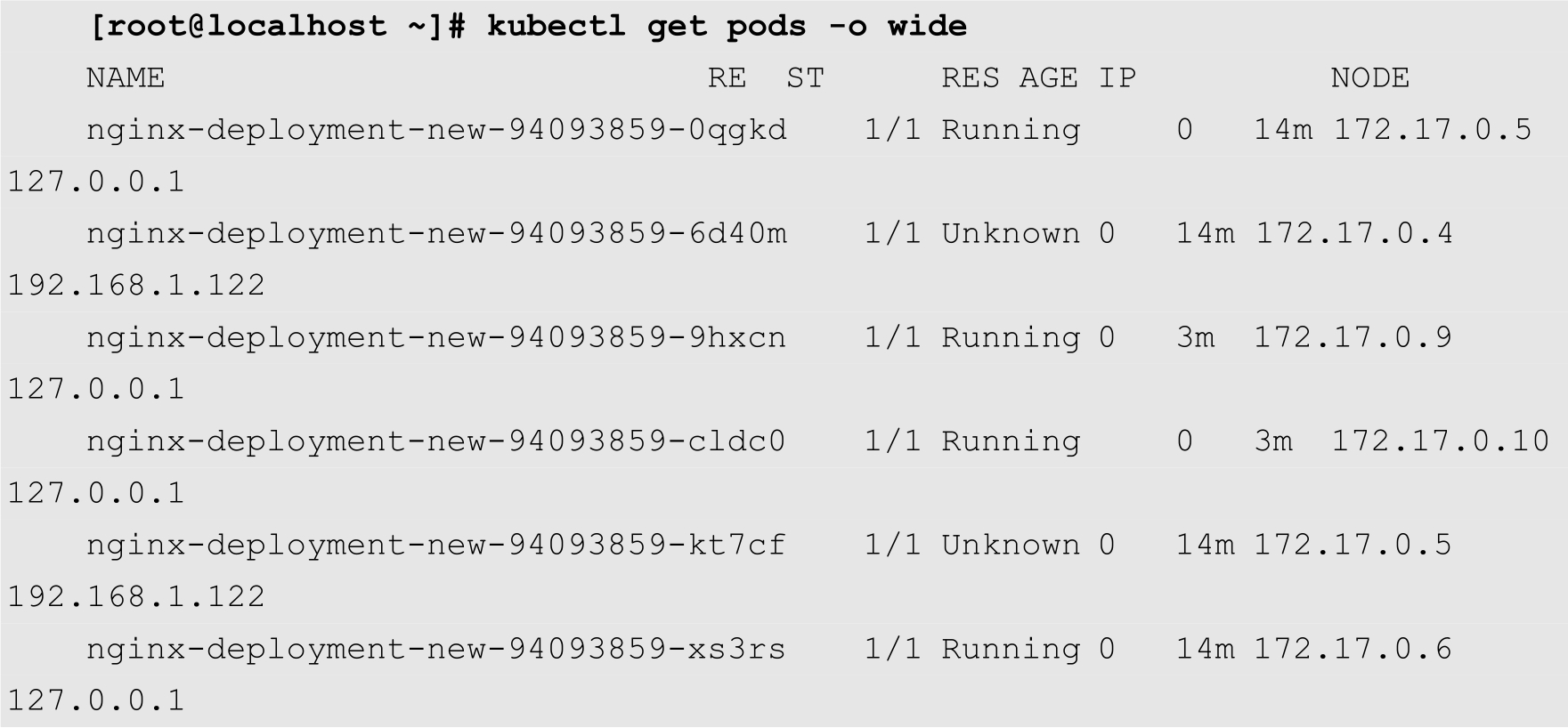
即使192.168.1.122节点重新恢复正常,Master节点也不会把Pod重新调度会该节点。
如果单个Pod副本出现故障,Kubernetes会自动创建一个新的副本,以达到预期的副本数。例如,我们使用kubectl delete pod命令将其中的一个副本删除,如下所示:
[root@localhost ~]# kubectl delete pod nginx-deployment-new-94093859-xs3rs pod "nginx-deployment-new-94093859-xs3rs" deleted
稍等片刻,Kubernetes会自动创建一个新的副本,并且调度到另外的节点上,如下所示:

默认情况下,Kubernetes会将Pod调度到所有可用的Node节点上,以达到负载平衡的目的。但是,在某些情况下,用户可以需要将一些特定功能的Pod部署在指定的Node节点上。例如,某些运行数据库的Pod需要运行在内存较大的Node节点上,而某些执行存储功能的Pod需要运行在磁盘I/O快的Node节点上。
在Kubernetes中,可以通过标签功能来标记各种资源,不只是节点,其他的资源,比如Deployment、ReplicaSet等都可以通过标签来标记。
所谓标签,实际上就是一些“键-值对”,在Kubernetes中,用户可以自由地定义自己的标签。
Kubernetes通过kubectl label node命令来设置节点的标签。例如,下面的命令将名为192.168.1.122的节点设置一个名称为mem的标签:
[root@localhost ~]# kubectl label node 192.168.1.122 mem=large node "192.168.1.122" labeled
通过上面的命令,标签已经被成功地添加到了节点上。用户可以通过--show-labels选项将节点的标签显示出来,如下所示:

从上面的输出结果可以看到,实际上Kubernetes已经自己维护了一些系统内部使用的标签,例如beta.kubernetes.io/arch、beta.kubernetes.io/os以及kubernetes.io/hostname等。
有了标签,我们就可以将Pod指定到特定的节点上了。Kubernetes通过资源配置文件的nodeSelector属性来对节点进行选择。修改前面创建的Deployment配置文件,在spec属性中增加nodeSelector属性,如下所示:
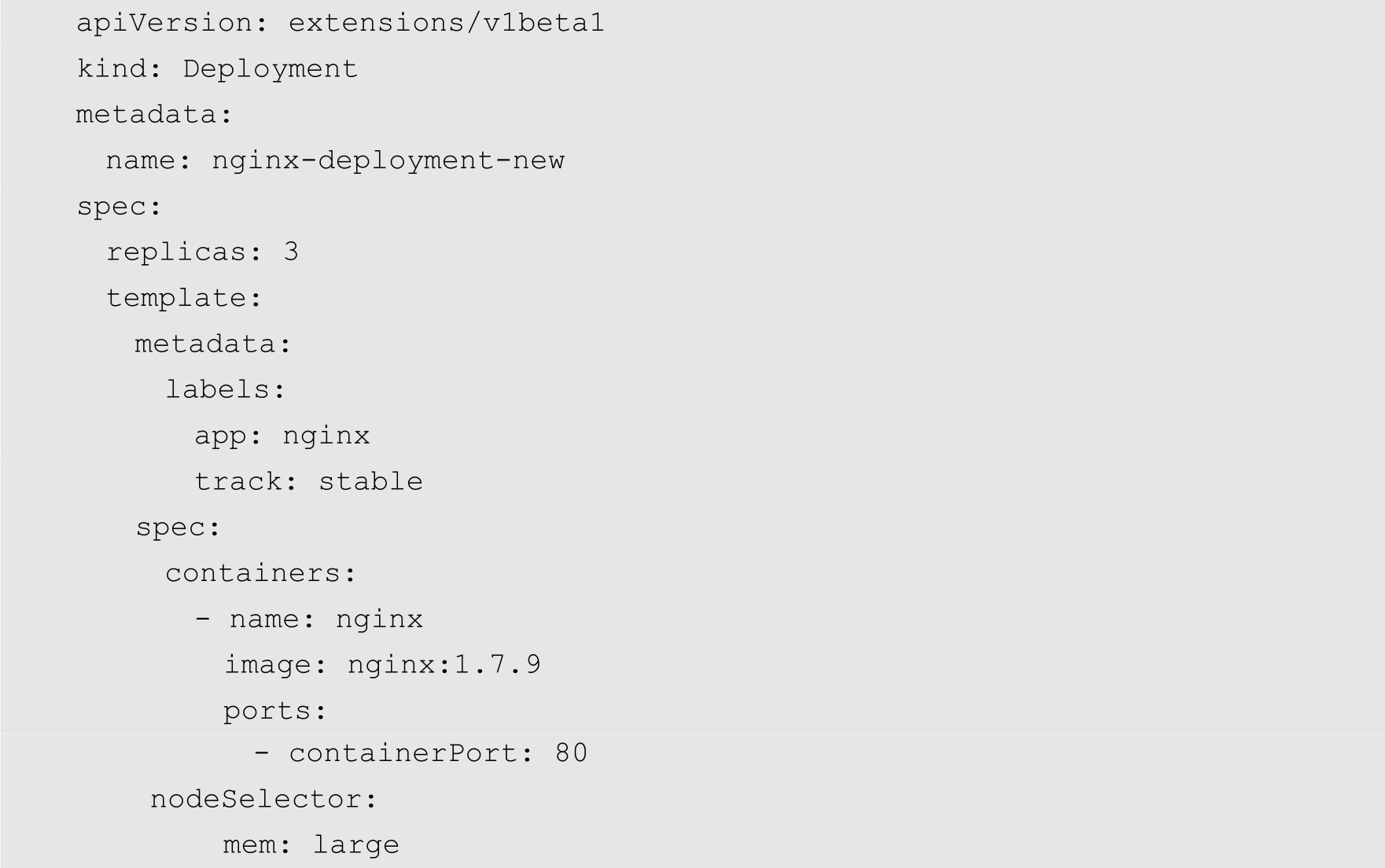
执行kubectl apply命令重新创建Deployment,如下所示:
[root@localhost ~]# kubectl apply -f nginx-deployment.yaml deployment "nginx-deployment-new" created
然后通过kubectl get pods命令查看Pod在节点上的调度情况:

从上面的输出结果可知,现在所有的Pod都被调度到名为192.168.1.122节点上。
如果想要删除某个特定的标签,可以使用以下命令:
[root@localhost ~]# kubectl label node 192.168.1.122 mem- node "192.168.1.122" labeled
在上面的命令中,mem-中的mem为标签的键,后面的减号表示将该标签删除。执行完成之后,再次查看节点的标签,就会发现标签已经被删除了,如下所示:

标签被删除后,Kubernetes并不会立即重新调度Pod到其他节点上,除非用户通过kubectl apply命令重新部署:
[root@localhost ~]# kubectl apply -f nginx-deployment.yaml
除了可以在配置文件中通过nodeSelector属性指定节点之外,用户在命令行中也可以通过-l或者--labels=这两个选项指定节点的标签。例如,下面的命令也可以将Pod部署到含有标签mem=large的节点上:
[root@localhost ~]# kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=3 --labels='mem=large'
对于已经不再使用的Deployment,用户将其从系统中删除。删除Deployment需要使用kubectl delete deployment命令。该命令的使用方法比较简单,直接将Deployment名作为参数传递给它就可以了,如下所示:
[root@localhost ~]# kubectl delete deployment nginx-deployment-new deployment "nginx-deployment-new" deleted
当Deployment被删除之后,由该Deployment所创建的所有的ReplicaSet和Pod都会被自动删除。
在前面的例子中,我们已经得知,通过Deployment创建的Pod副本会分布在各个节点上,每个节点上都有可能运行好几个副本。而DaemonSet则不同,通过它创建的Pod只会运行在同一个节点上,并且最多只会有一个副本。
DaemonSet通常用来创建一些系统性的Pod,例如提供日志管理、存储或者域名服务等。实际上,Kubernetes本身就有一些DaemonSet,这些DaemonSet都位于kube-system命名空间里面。例如,kube-proxy、kube-flannel-ds等都是由DaemonSet创建的。
除了系统自身的DaemonSet之外,用户也可以自定义DaemonSet。下面以一个简单的例子来说明如何运行自己的DaemonSet。
Prometheus的Node Exporter是一个非常有名的、开源的服务器监控系统。用户可以在Kubernetes集群中创建一个Node Exporter的DaemonSet,用来监控各个容器的情况。
为了创建DaemonSet,用户需要创建一个YAML配置文件,其名为node-exporter-daemonset.yml,内容如下:
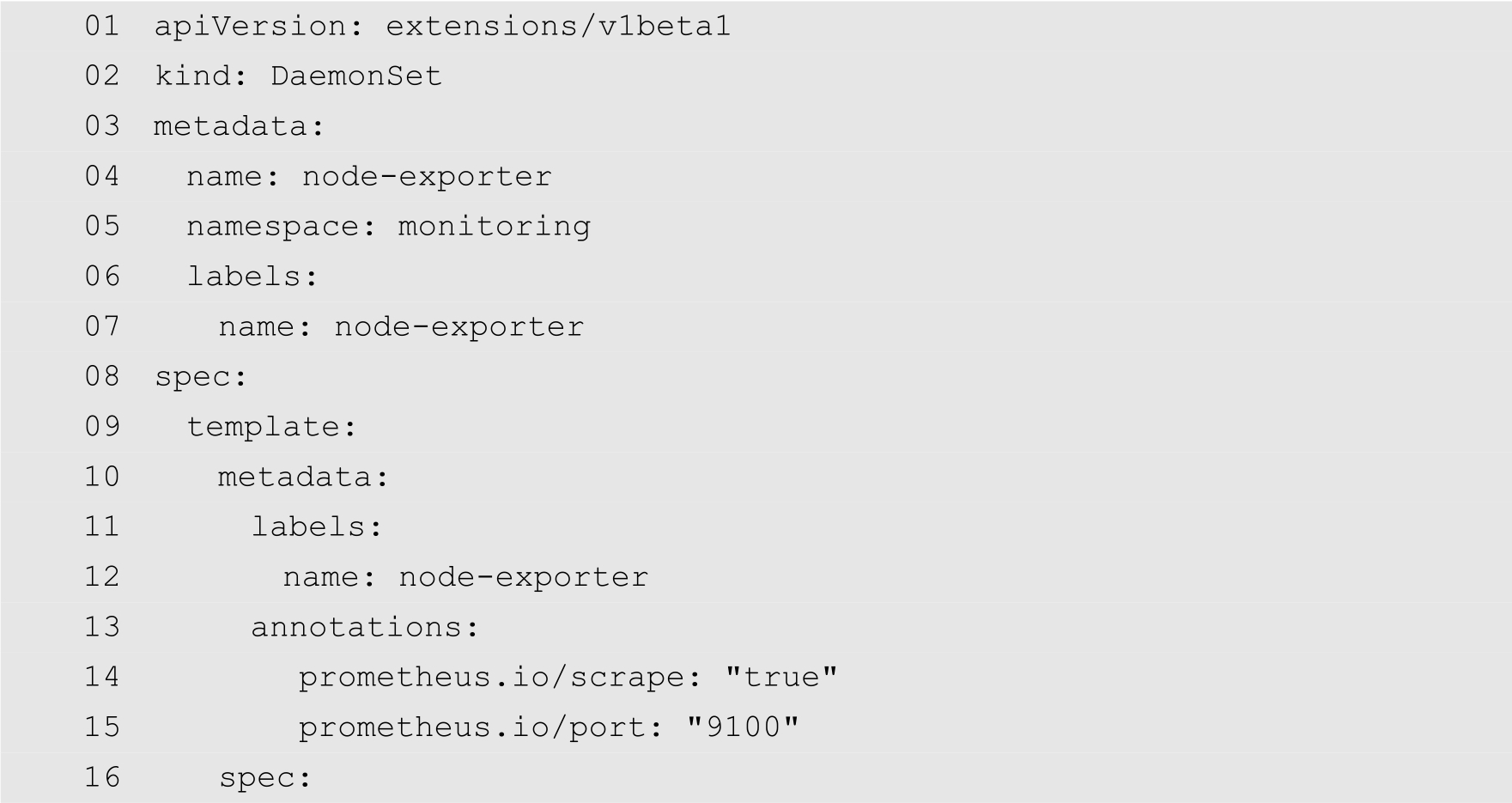

在上面的配置文件中,第2行指定资源类型为DaemonSet。第5行指定命名空间为monitoring。第19行指定容器的网络模式为主机网络。第29行指定容器镜像为prom/node-exporter:v0.15.2。第32行通过Volume将宿主机的/proc、/sys以及/等路径映射到容器中。
由于命名空间monitoring在当前集群中并不存在,因此用户需要首先创建该命名空间,命令如下:
[root@localhost ~]# kubectl create namespace monitoring
创建完成之后,就可以创建DaemonSet了,如下所示:
[root@localhost ~]# kubectl create -f node-exporter-daemonset.yml
最后,用户可以通过kubectl get pods命令查看Pod状态,如下所示:

从上面的输出结果可知,在每个节点上都有一个副本在运行。
在4.1节中,我们详细介绍了Deployment和DaemonSet。在Kubernetes中,除了这2个重要的运行应用的途径之外,还有Job。Job在Kubernetes中的作用也是非常明显的,本节将详细介绍Job的使用方法。
对于Deployment、ReplicaSet以及Replication Controller等类型的控制器而言,它希望Pod保持预期数目、持久地运行下去。除非用户明确删除,否则这些对象一直存在,它们针对的是持久性任务,如Web服务等。对于非持久性任务,比如归档文件,任务完成后,Pod需要结束运行,不需要Pod继续保持在系统中,这个时候就要用到Job。因此,可以说Job是对ReplicaSet、Replication Controller等持久性控制器的补充。
Job的配置文件的语法与前面介绍的Deployment的基本语法大致相同。例如,下面的代码定义了一个Job,该Job的功能是实现倒计时,其代码如下:
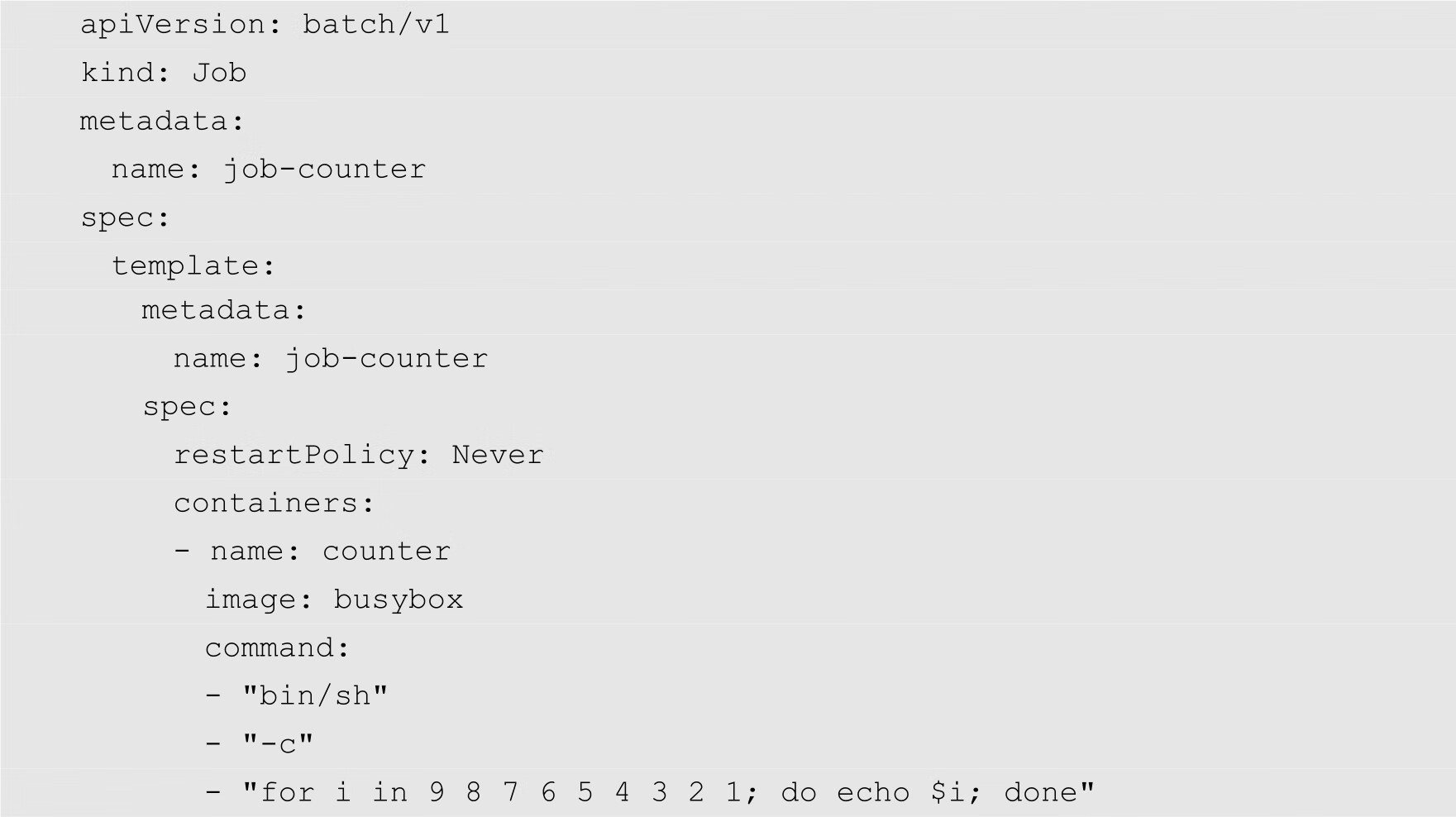
在上面的代码中,kind的值为Job,表示当前创建的是一个Job类型的资源。restartPolicy用来指定在什么情况下需要重启容器,在本例中的值为Never。image指定镜像为busybox。Busybox是一个集成了100多个最常用Linux命令和工具的软件工具箱,它在单一的可执行文件中提供了精简的Unix工具集。BusyBox可运行于多款POSIX环境操作系统中,如Linux(包括Android)、Hurd、FreeBSD等。Busybox既包含了一些简单实用的工具,如cat和echo,也包含了一些更大、更复杂的工具,如grep、find、mount以及telnet,可以说BusyBox是Linux系统的瑞士军刀。
注意
Job的restartPolicy仅支持Never和OnFailure两种,不支持Always,这是因为Job只相当于用来执行一个批处理任务,执行完就结束了。
将上面的代码保存为job-counter.yaml,然后执行以下命令启动该Job:
[root@localhost ~]# kubectl apply -f job-counter.yaml
然后通过kubectl get jobs命令查看Job的状态,如下所示:

从上面命令的输出可知,job-counter的预期值和成功值都是1,这表示我们刚才已经成功执行了一个Pod。
接下来,使用kubectl get pods命令查看Pod的状态,由于刚才启动的Pod已经退出运行,因此需要使用--show-all选项,如下所示:

在上面的列表中,第1行的名为job-counter-6jkrf的Pod,正是刚刚执行完成的Job的Pod。可以得知,该Pod的状态为Completed,表示Pod已经执行完成。
上面的Pod的输出信息保存在日志中,用户可以通过kubectl logs命令查看,如下所示:

这个Job已经按照我们的预期,输出了从9~1的倒计时序列。
作为一种任务计划,总有在执行过程中遇到某些意外的时候。为了能够及时处理这种意外,用户需要及时掌握Job的执行情况。
为了演示Job执行失败的情况,我们修改job-counter.yaml配置文件,将其中的command的值修改为一个错误的命令,如下所示:
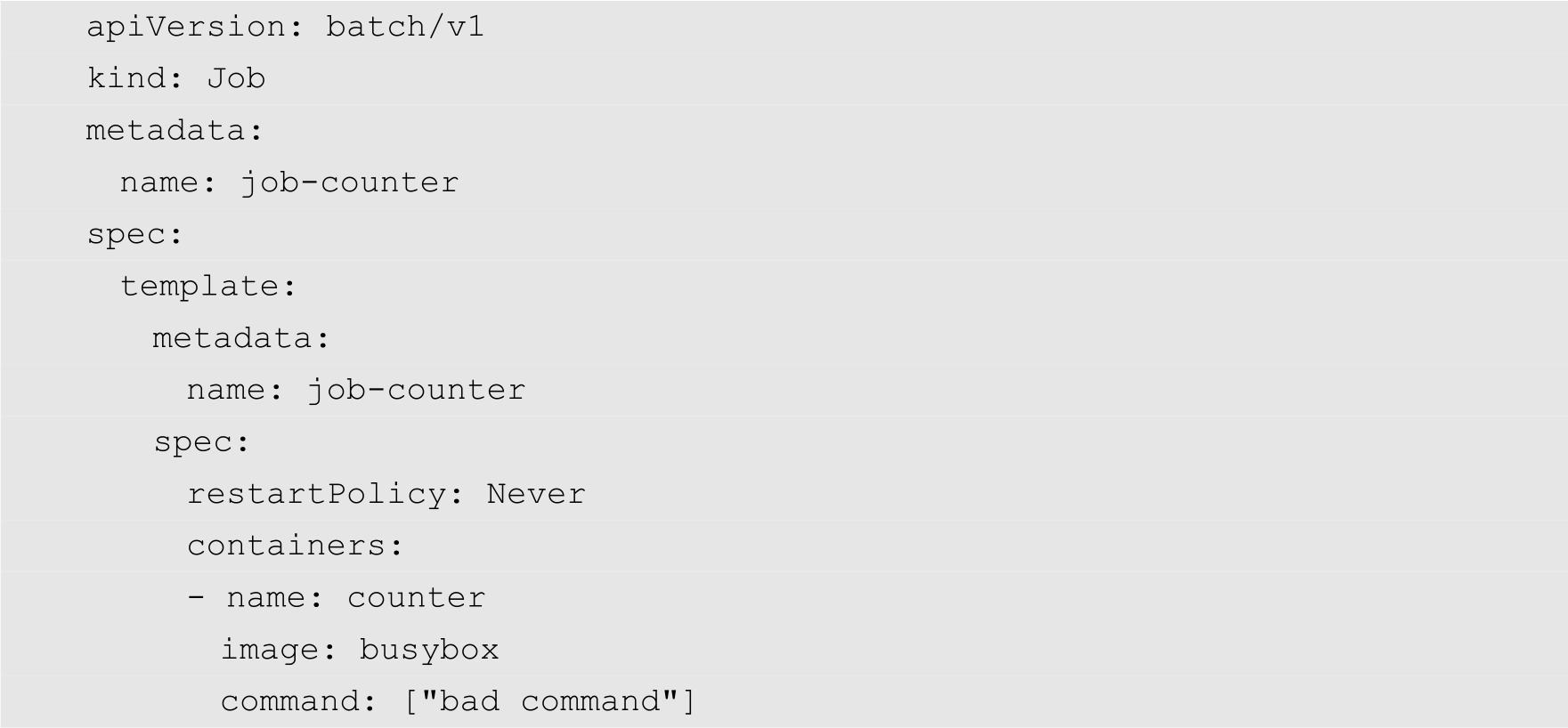
然后删除前面创建的Job:
[root@localhost ~]# kubectl delete job job-counter job "job-counter" deleted
接下来创建新的Job:
[root@localhost ~]# kubectl apply -f job-counter.yaml job "job-counter" created
执行完成之后,通过kubectl get jobs命令查看Job信息:

从上面的输出结果可以得知,预期的副本数为1,而成功的副本数为0。
如果使用kubectl get pods命令查看Pod状态,其结果如下:
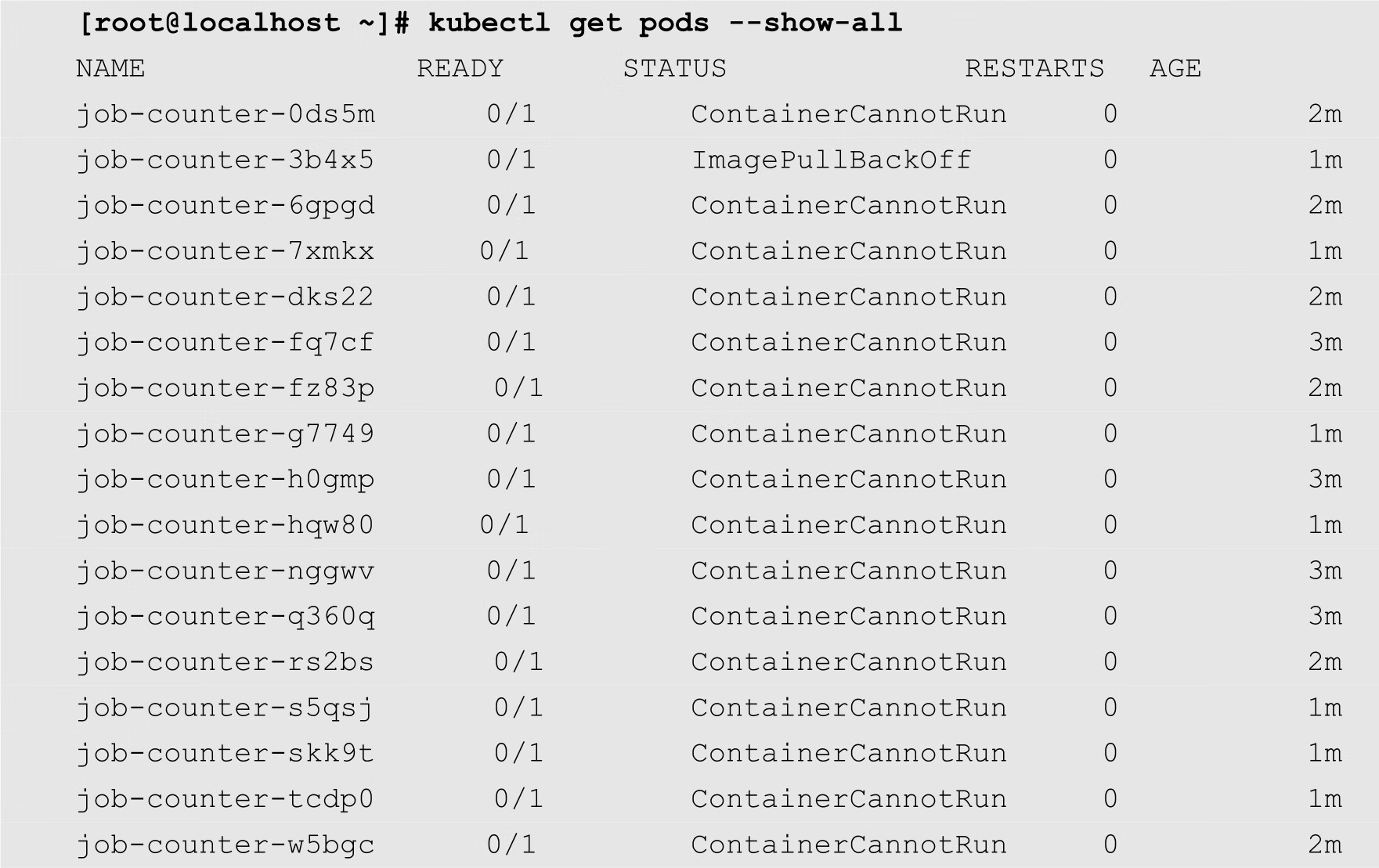
可以发现,上面的输出结果中存在着多个状态为ContainerCannotRun的Pod。从Pod名称中的前缀可以得知,这些Pod都是由前面的Job创建的。此时,如果使用kubectl describe pod命令随便查看一个Pod的信息,则会发现以下错误信息:

上面的错误日志表明,由于我们在配置文件中指定的命令没有被找到,从而导致Job运行失败。
但是读者可能会问,为什么会出现那么多的Pod呢?其原因在于,尽管我们在配置文件中将restartPolicy的值指定为Never,这样在Job启动失败之后,容器不会被重新启动,但是由于预期Pod的副本数为1,而目前的副本数却一直是0,达不到预期的数量。此时,Job会不停地创建新的Pod,一直到达到成功的副本数为1为止。
为了终止这种情况,我们需要删除该Job,命令如下:
[root@localhost ~]# kubectl delete -f job-counter.yaml
在某些情况下,用户可能需要同时运行多个Job副本,以提高工作效率。此时,就涉及某个Job的多个副本并行执行的问题。
Job的并行执行需要使用parallelism属性,该属性为数值型,默认情况下,该属性的值为1,表示只有一个副本在执行。如果需要多个副本同时执行,就需要修改该属性的值。
我们将4.2.1小节中的Job的配置文件进行修改,增加parallelism属性,将其值设置为3,如下所示:
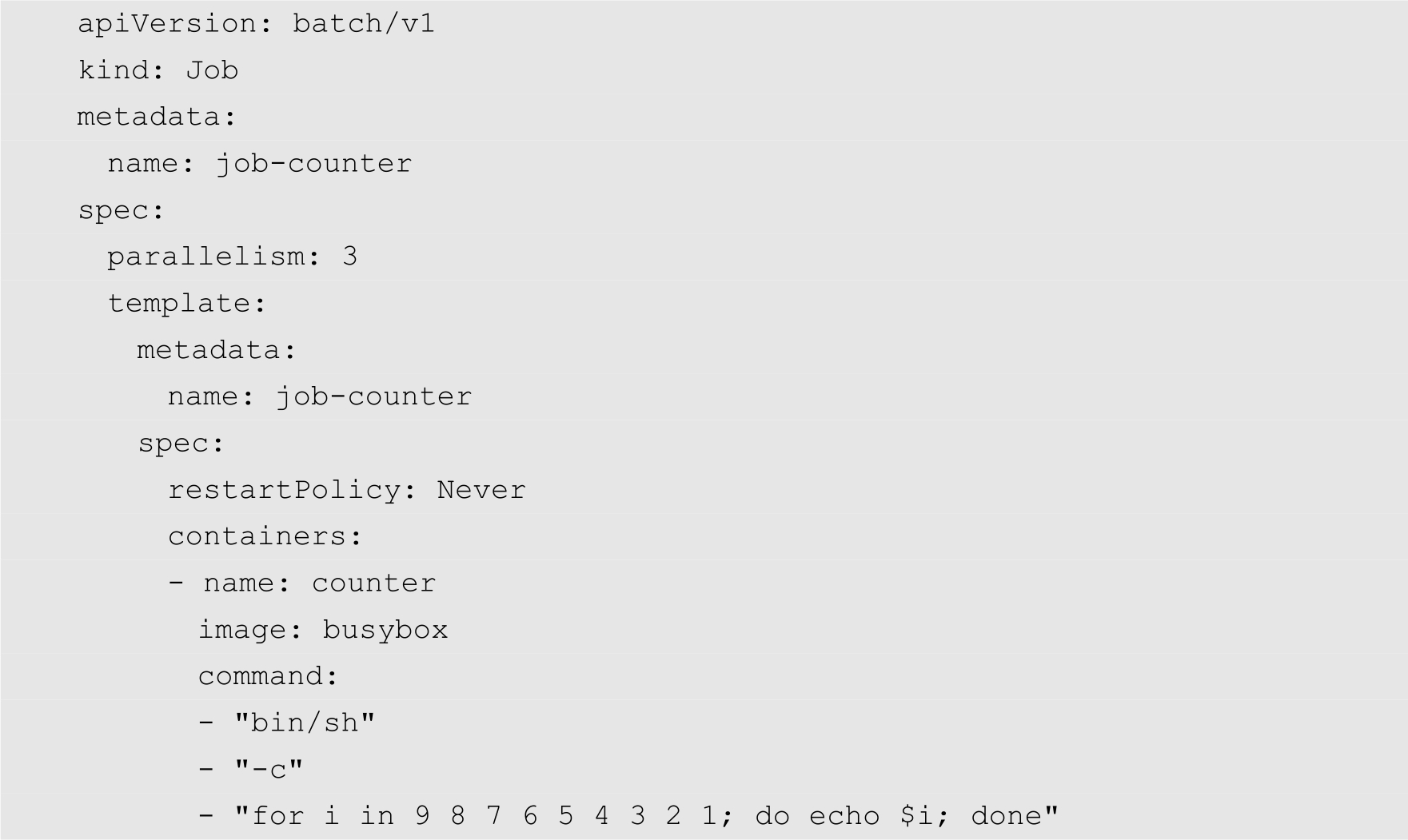
然后通过以下命令运行Job:
[root@localhost ~]# kubectl apply -f job-counter.yaml
执行完成之后,查看Job状态,如下所示:

通过上面的输出可以得知,一共有3个Job成功执行。接下来查看以下Pod的状态,如下所示:

从上面的输出结果可知,一共有3个Pod处于完成状态,它们的AGE值都为2m,这表示它们是同时并行执行的。
在Kubernetes中,Job除了可以并行执行之外,还可以定时执行。这在完成某些计划任务时非常重要。Kubernetes为定时Job专门设置了一种资源类型,其名为CronJob。
CrontabJob需要batch/v2alpha1版本的API,所以需要预先修改kube-apiserver的配置文件,增加以下选项:
KUBE_API_ARGS="--allow_privileged=true
--runtime-config=batch/v2alpha1=true"
然后创建一个CronJob的YAML配置文件,代码如下:
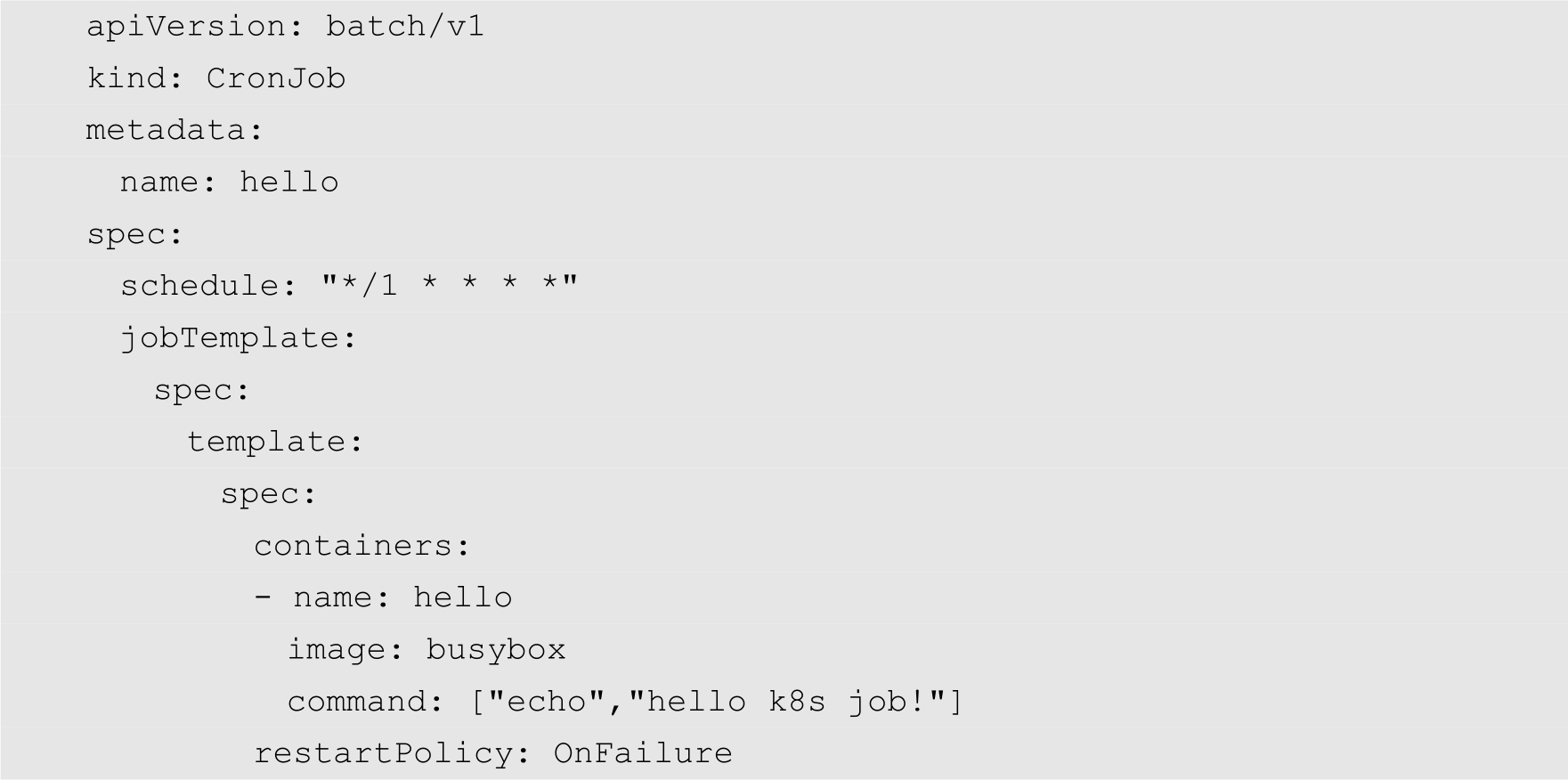
执行kubectl apply命令,创建CronJob,如下所示:
[root@localhost ~]# kubectl apply -f cronjob.yaml
然后查看CronJob的状态:

可以发现,在上面的列表中,没有Job处于活动状态。为了能够观察到Job的执行情况,需要使用--watch选项,如下所示:

现在,从上面的输出结果可以发现,每隔1分钟左右,上面的Job会执行一次。
除了使用配置文件之外,用户也可以使用命令行来创建CronJob。例如,上面的CronJob可以使用以下命令来创建:
