日志对于业务分析和系统分析是非常重要的数据。在一个Kubernetes集群中,大量容器应用运行在众多Node上,各容器和Node的系统组件都会生成许多日志文件。但是容器具有不稳定性,在发生故障时可能被Kubernetes重新调度,Node也可能由于故障无法使用,造成日志丢失,这就要求管理员对容器和系统组件生成的日志进行统一规划和管理。
容器应用和系统组件输出日志的场景如下。
容器应用可以选择将日志输出到不同的目标位置:
◎ 输出到标准输出和标准错误输出;
◎ 输出到某个日志文件;
◎ 输出到某个外部系统。
输出到标准输出和标准错误输出的日志通常由容器引擎接管,并保存在容器运行的Node上,例如Docker会被保存在/var/lib/docker/containers目录下。在Kubernetes中,用户可以通过kubectl logs命令查看容器输出到stdout和stderr的日志,例如:

输出到文件中的日志,其保存位置依赖于容器应用使用的存储类型。如果未指定特别的存储,则容器内应用程序生成的日志文件由容器引擎(例如Docker)进行管理(例如存储为本地文件),在容器退出时可能被删除。需要将日志持久化存储时,容器可以选择使用Kubernetes提供的某种存储卷(Volume),例如hostpath(保存在Node上)、nfs(保存在NFS服务器上)、PVC(保存在某种网络共享存储上)。保存在共享存储卷中的日志要求容器应用确保文件名或子目录名称不冲突。
某些容器应用也可能将日志直接输出到某个外部系统中,例如通过一个消息队列(如Kafka)转发到一个后端日志存储中心。在这种情况下,外部系统的搭建方式和应用程序如何将日志输出到外部系统,应由容器应用程序的运维人员负责,不应由Kubernetes负责。
Kubernetes的系统组件主要包括在Master上运行的管理组件(kube-apiserver、kube-controller-manager和kube-scheduler),以及在每个Node上运行的管理组件(kubelet和kube-proxy)。这些系统组件生成的日志对于Kubernetes集群的正常运行和故障排查都非常重要。
系统组件的日志可以通过--log-dir参数保存到指定的目录下(例如/var/log),或者通过--logtostderr参数输出到标准错误输出中(stderr)。如果系统管理员将这些服务配置为systemd的系统服务,日志则会被journald系统保存。
Kubernetes从1.19版本开始,开始引入对结构化日志的支持,使日志格式统一,便于日志中字段的提取、保存和后续处理。结构化日志以JSON格式保存。目前kube-apiserver、kube-controller-manager、kube-scheduler和kubelet这4个服务都支持通过启动参数--logging-format=json设置JSON格式的日志,需要注意的是,JSON格式的日志在启用systemd的系统中将被保存到journald中,在未使用systemd的系统中将在/var/log目录下生成*.log文件,不能再通过--log-dir参数指定保存目录。
例如,查看kube-controller-manager服务的JSON格式日志:


其中一行JSON日志的内容如下:

Kubernetes应用程序在生成JSON格式日志时,可以设置的字段如下。
◎ ts:UNIX格式的浮点数类型的时间戳(必填项)。
◎ v:日志级别,默认为0(必填项)。
◎ msg:日志信息(必填项)。
◎ err:错误信息,字符串类型(可选项)。
不同的组件也可能输出其他附加字段,例如:

或

Kubernetes的审计日志可通过kube-apiserver服务的--audit-log-*相关参数进行设置,关于审计日志的详细说明请参考10.9节的说明。
对于以上各种日志输出的情况,管理员应该对日志进行以下管理。
(1)对于输出到主机(Node)上的日志,管理员可以考虑在每个Node上都启动一个日志采集工具,将日志采集后汇总到统一日志中心,以供日志查询和分析,具体做法如下。
◎ 对于容器输出到stdout和stderr的日志:管理员应该配置容器引擎(例如Docker)对日志的轮转(rotate)策略,以免文件无限增长,将主机磁盘空间耗尽。
◎ 对于系统组件输出到主机目录上(如/var/log)的日志,管理员应该配置各系统组件日志的轮转(rotate)策略,以免文件无限增长等将主机磁盘空间耗尽。
◎ 对于容器应用使用hostpath输出到Node上的日志:管理员应合理分配主机目录,在满足容器应用存储空间需求的同时,可以考虑使用采集工具将日志采集并汇总到统一的日志中心,并定时清理Node的磁盘空间。
(2)对于输出到容器内的日志,容器应用可以将日志直接输出到容器环境内的某个目录下,这可以减轻应用程序在共享存储中管理不同文件名或子目录的复杂度。在这种情况下,管理员可以为应用容器提供一个日志采集的sidecar容器,对容器的日志进行采集,并将其汇总到某个日志中心,供业务运维人员查询和分析。
在Kubernetes生态中,推荐采用Fluentd+Elasticsearch+Kibana完成对系统组件和容器日志的采集、汇总和查询的统一管理机制。下面对系统的部署和应用进行说明。
在本节的示例中,我们先对Node上的各种日志进行采集和汇总。Fluentd+ Elasticsearch+Kibana系统的逻辑关系架构如图10.14所示。
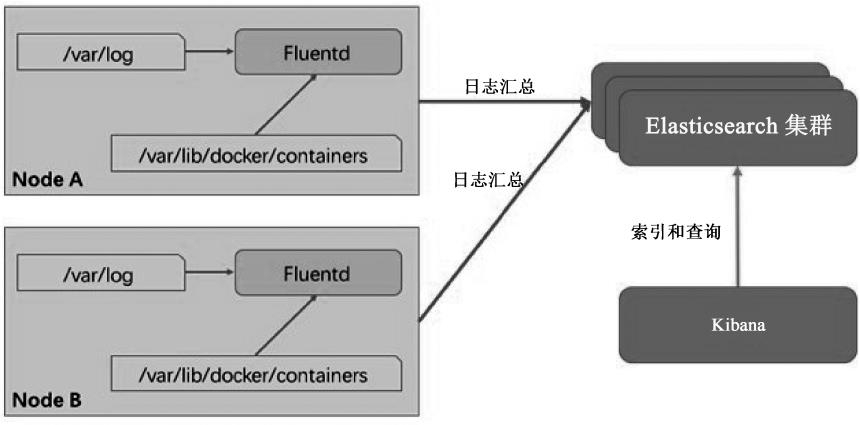
图10.14 Fluentd+Elasticsearch+Kibana系统的逻辑关系架构
这里假设将Kubernetes系统组件的日志输出到/var/log目录下,容器输出到stdout和stderr的日志由Docker Server保存在/var/lib/docker/containers目录下。我们通过在每个Node上都部署一个Fluentd容器来采集本节点在这两个目录下的日志文件,然后将其汇总到Elasticsearch库中保存,用户通过Kibana提供的Web页面查询日志。
部署过程主要包括3个组件:Elasticsearch、Fluentd和Kibana。
Elasticsearch的Deployment和Service定义如下:



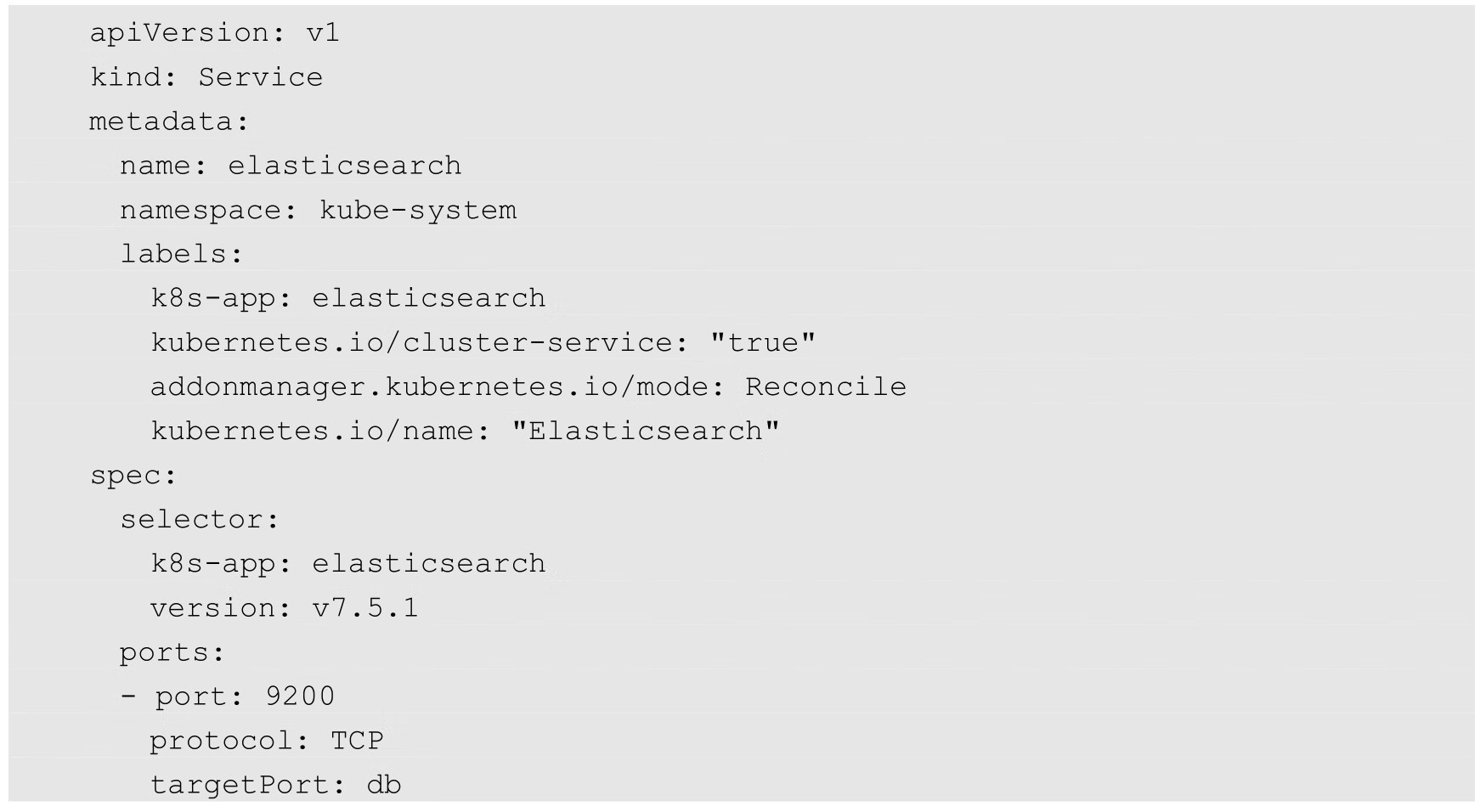
关键配置说明如下。
◎ 需要通过一个初始化容器设置系统参数vm.max_map_count=262144,这是Elasticsearch的需求。如果在Node的操作系统上已设置过,则无须通过初始化容器进行设置。
◎ 数据存储目录:在本例中使用hostpath将数据保存在Node上,我们应根据实际需求选择合适的存储类型,例如某种高可用的共享存储。
◎ 资源限制应根据实际情况进行调整,如果设置得太小,则可能会导致OOM Kill。
◎ 将discovery.type设置为single-node意为单节点模式,Elasticsearch也可以被部署为高可用集群模式,包括master、client、data等节点,详细的部署配置请参考Elasticsearch官方文档的说明。
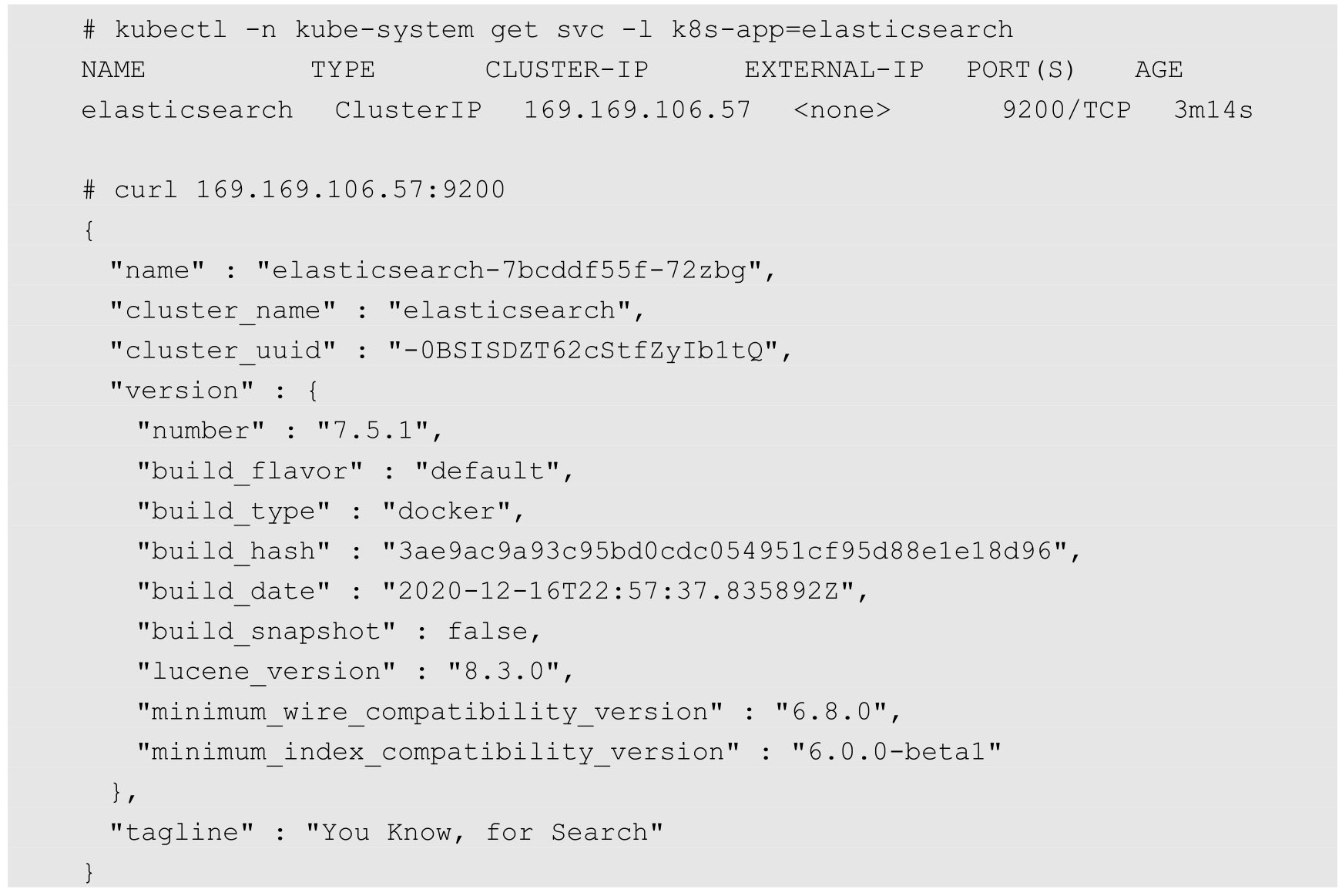
这里通过kubectl create命令完成部署,并确认Pod运行成功:

可以通过访问Elasticsearch服务的URL验证Elasticsearch是否正常运行:
Fluentd以DaemonSet模式在每个Node上都启动一个Pod进行日志采集,对各种日志采集和连接Elasticsearch服务的具体配置使用ConfigMap进行设置。Fluentd的YAML定义如下:


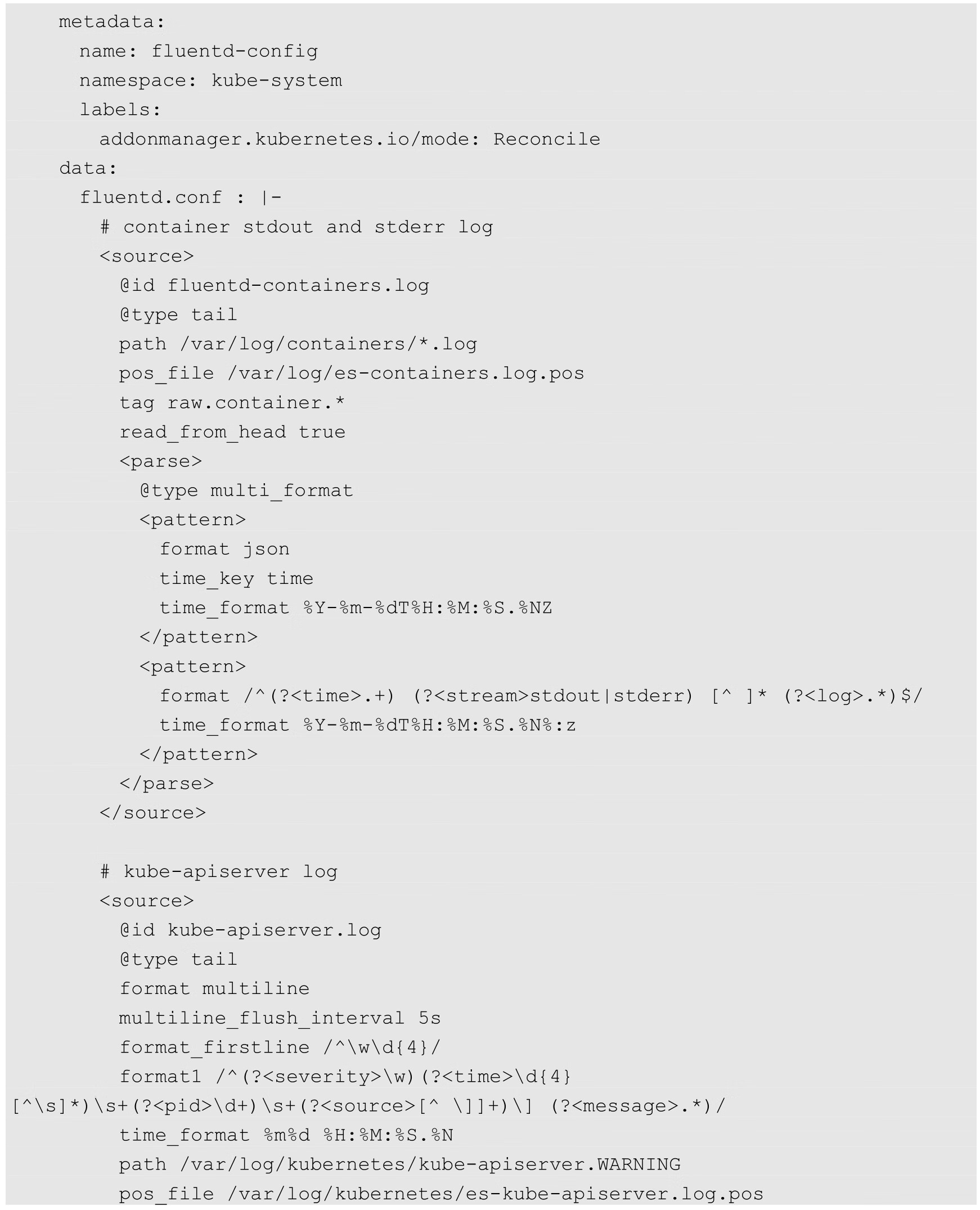
关键配置说明如下。
◎ 将宿主机Node的/var/log和/var/lib/docker/containers目录挂载到fluentd容器中,用于读取容器输出到stdout和stderr的日志,以及Kubernetes组件的日志。
◎ 在以上示例中采集了kube-apiserver服务的WARNING日志,其他组件的配置省略。
◎ 资源限制应根据实际情况进行调整,避免Fluentd占用太多资源。
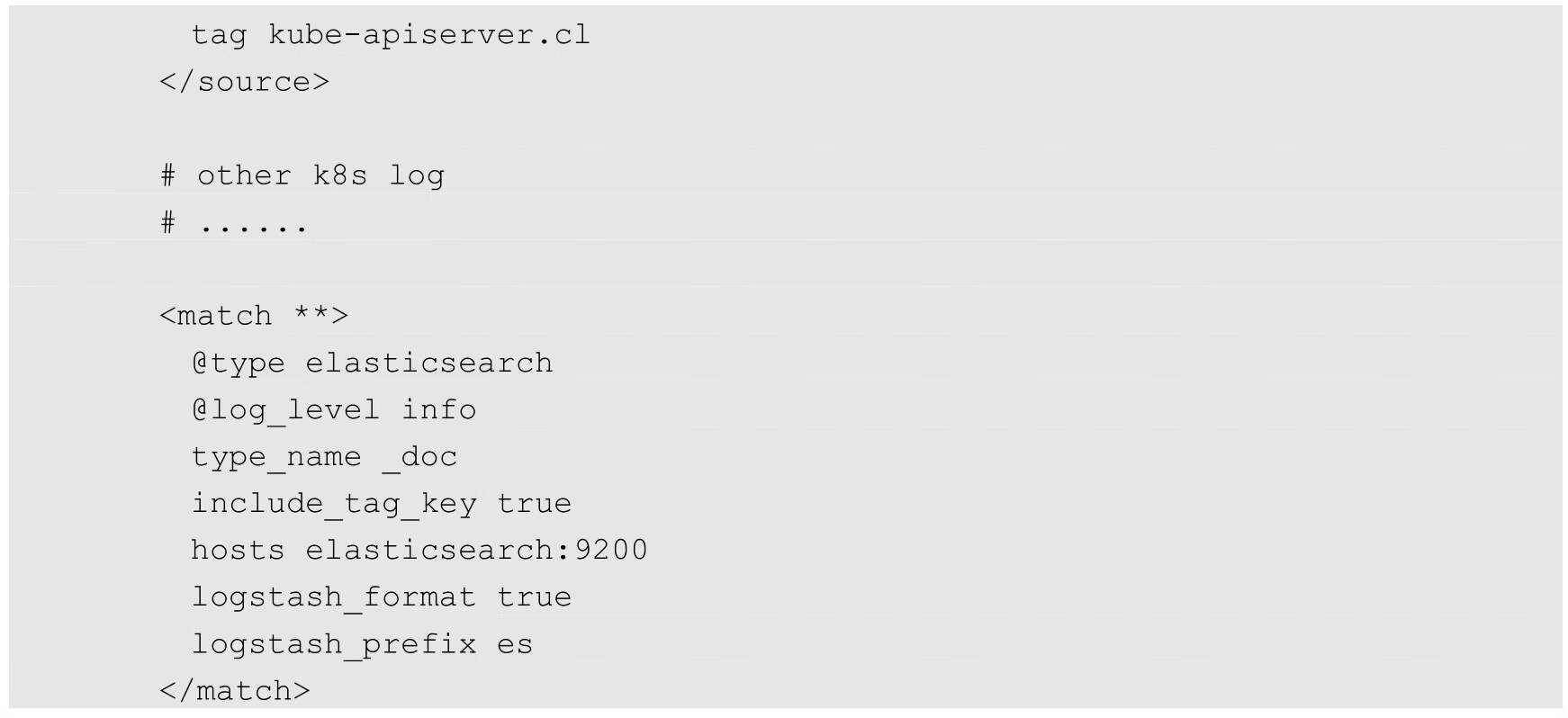
◎ hosts elasticsearch:9200:设置Elasticsearch服务的访问地址,此处使用了Service名称,由于Fluentd与Elasticsearch处于同一个命名空间中,所以此处省略了命名空间的名称。
◎ logstash_prefix es:Fluentd在Elasticsearch中创建索引(Index)的前缀。
通过kubectl create命令创建Fluentd容器:

确保Fluentd在每个Node上都正确运行:


查看Fluentd的容器日志,会看到连接到Elasticsearch服务的记录,以及后续采集各种日志文件内容的记录:
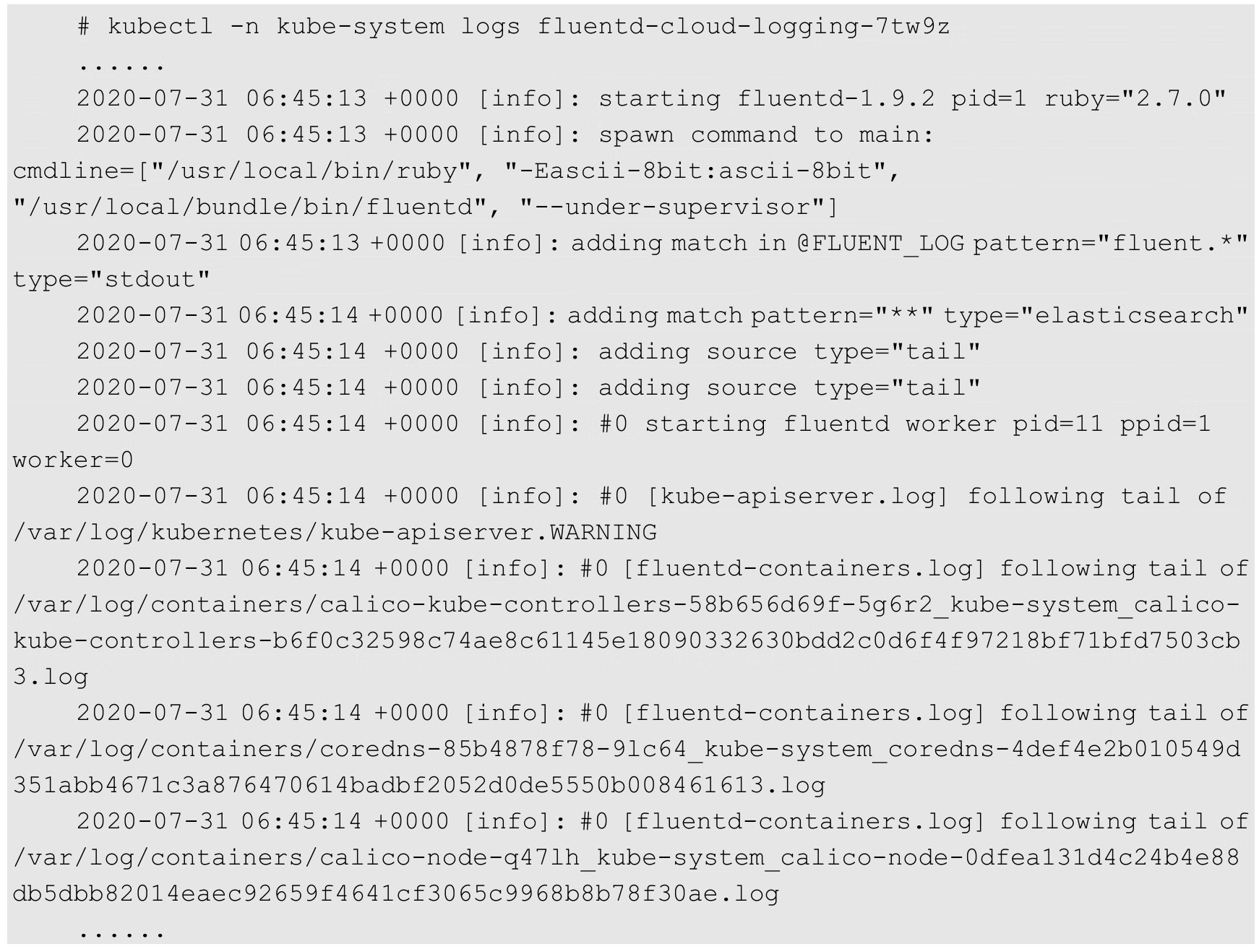
此时通过Elasticsearch服务的API,即可看到已经创建的索引(Index)信息:

至此已经运行了Elasticsearch和Fluentd,数据的采集、汇总和保存工作已经完成,接下来部署Kibana服务提供日志查询的Web服务。
Kibana服务的Deployment和Service定义如下:

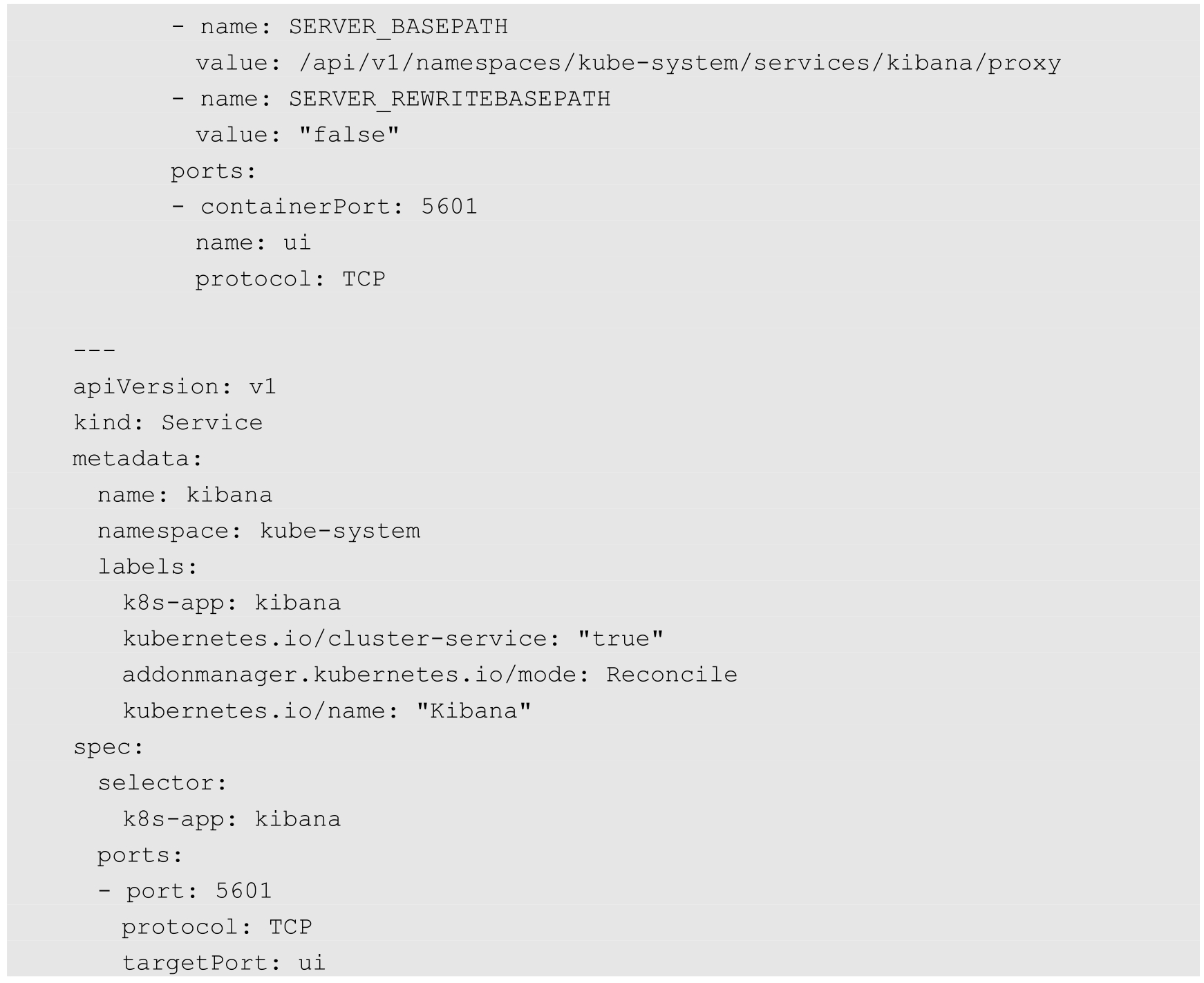
关键配置说明如下。
◎ ELASTICSEARCH_HOSTS:设置Elasticsearch服务的访问地址,此处使用服务名称。
◎ SERVER_BASEPATH:设置Kibana服务通过API Server代理的访问路径。
通过kubectl create命令部署Kibana服务:

确保Kibana成功运行:

通过kubectl cluster-info命令查看Kibana服务的访问URL地址:

在浏览器中输入URL即可打开Kibana页面。
在Elasticsearch索引管理页面可以看到当前Elasticsearch库中的索引列表和状态,如图10.15所示。
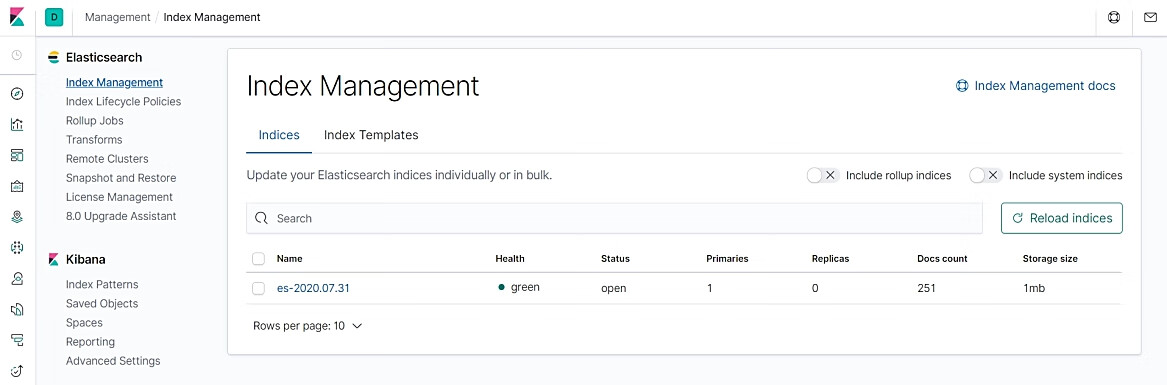
图10.15 索引列表和状态
在Kibana Index Patterns页面创建index pattern“es-*”,如图10.16所示。
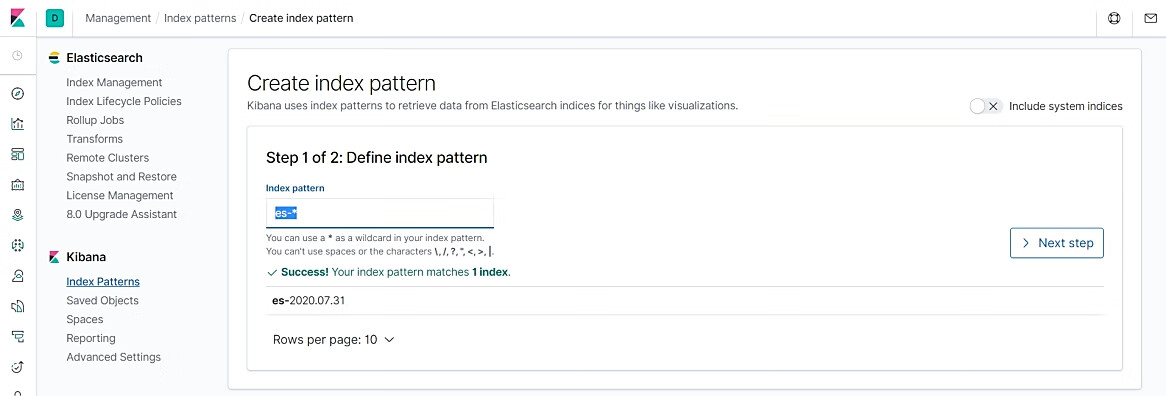
图10.16 创建index pattern
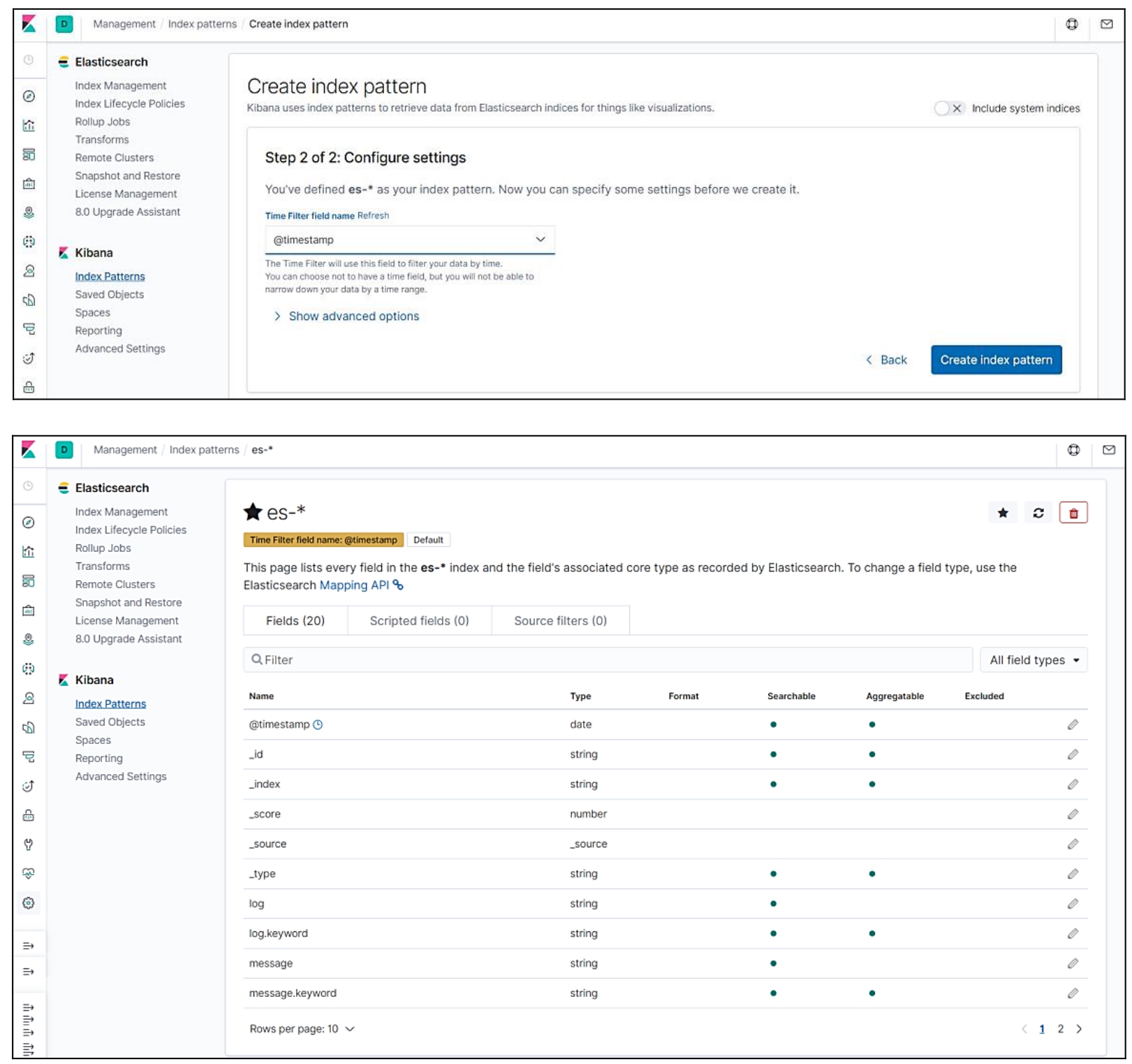
图10.16 创建index pattern(续)
成功创建index pattern之后,就可以在Discover页面查询日志记录了,默认显示过去15min的日志列表,如图10.17所示。
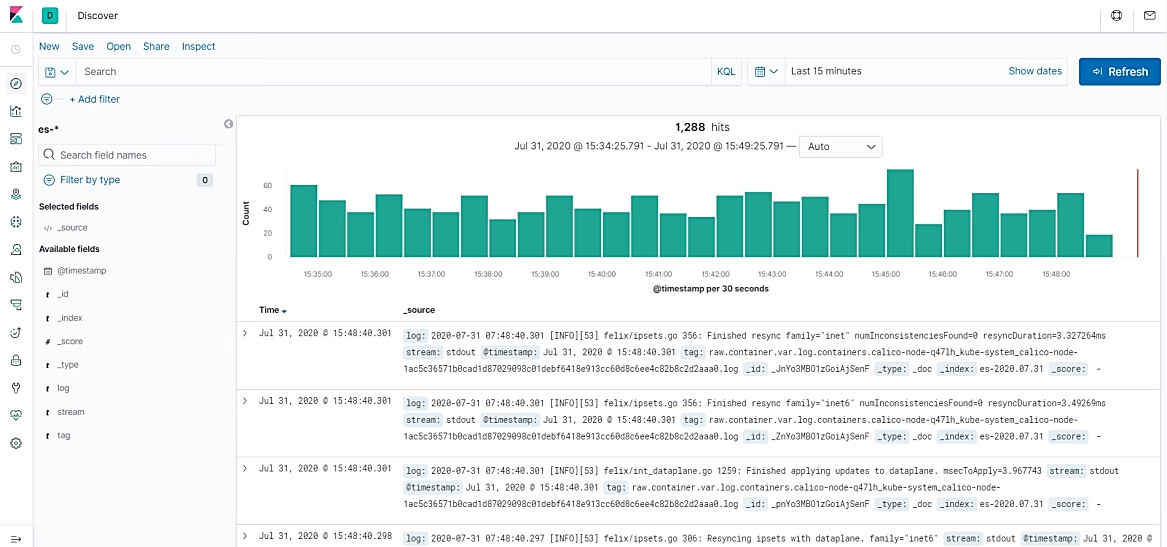
图10.17 Kibana查询日志页面
在搜索栏中输入“error”,可以搜索出包含该关键字的日志记录,如图10.18所示。
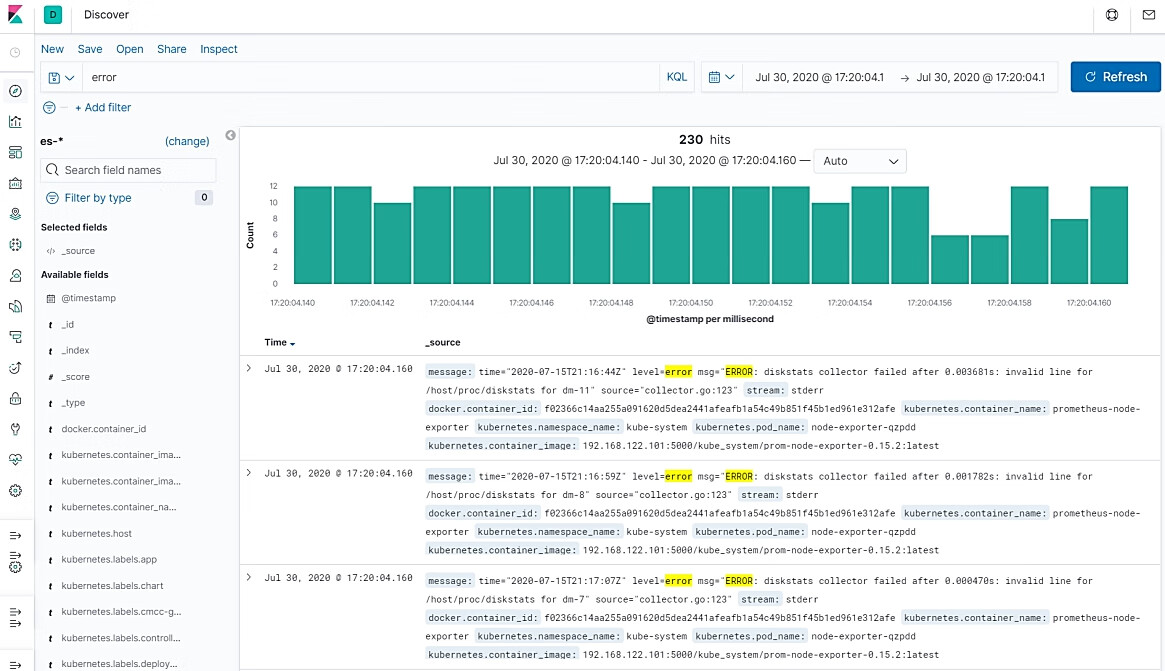
图10.18 Kibana日志关键字的搜索页面
至此,Kubernetes集群范围内的统一日志管理系统就搭建完成了。
对于容器应用输出到容器目录下的日志,可以为业务应用容器配置一个日志采集sidecar容器,对业务容器生成的日志进行采集并汇总到某个日志中心,供业务运维人员查询和分析,这通常用于业务日志的采集和汇总。后端的日志存储可以使用Elasticsearch,也可以使用其他类型的数据库(如MongoDB),或者通过消息队列进行转发(如Kafka),需要根据业务应用的具体需求进行合理选择。
日志采集sidecar工具也有多种选择,常见的开源软件包括Fluentd、Filebeat、Flume等,在下例中使用Fluentd进行说明。
为业务应用容器配置日志采集sidecar时,需要在Pod中定义两个容器,然后创建一个共享的Volume供业务应用容器生成日志文件,并供日志采集sidecar读取日志文件。例如:
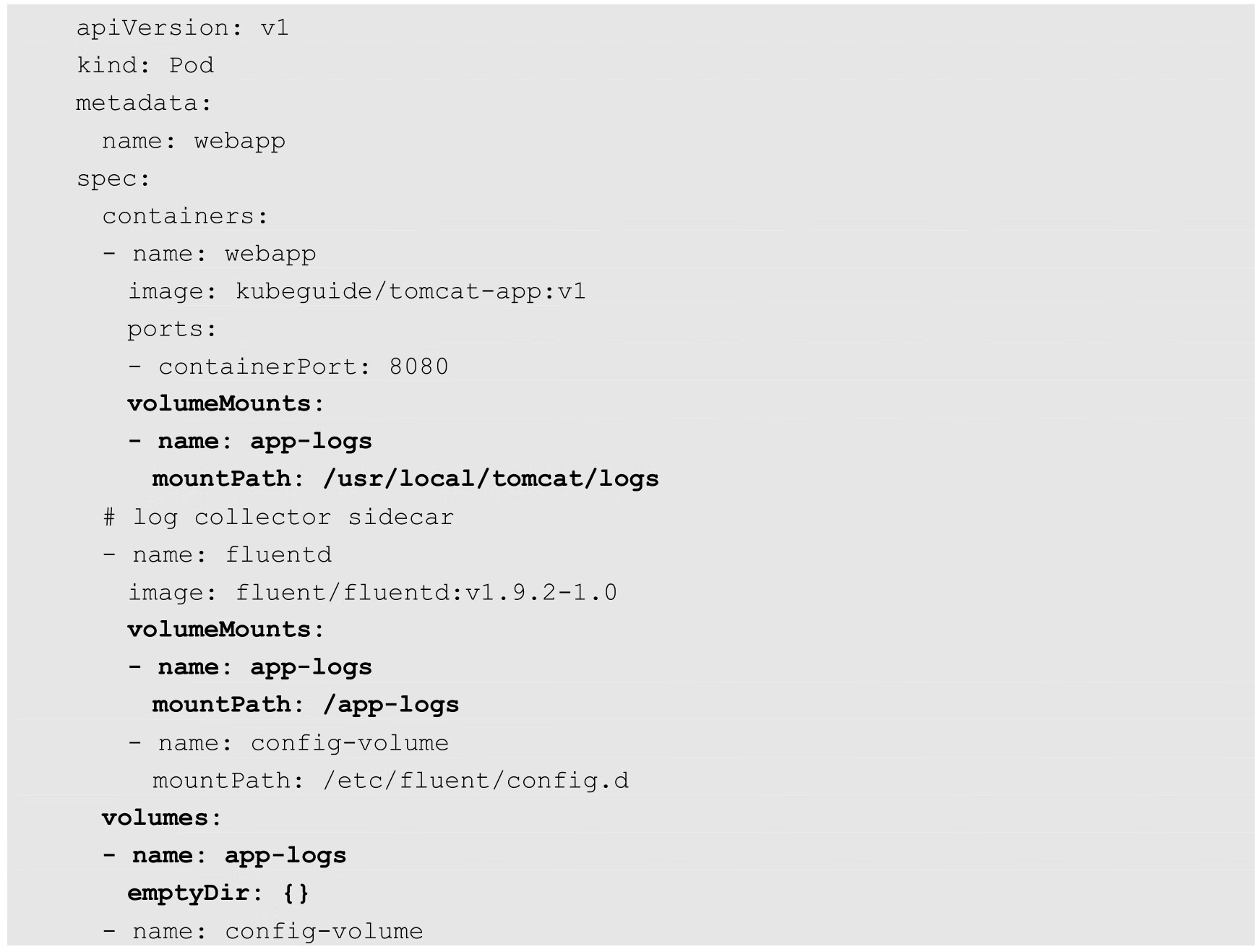

在这个Pod中创建了一个类型为emptyDir的Volume,挂载到webapp容器的/usr/local/tomcat/logs目录下,也挂载到fluentd容器中的/app-logs目录下。Volume的类型不限于emptyDir,需要根据业务需求合理选择。
在Pod创建成功之后,webapp容器会在/usr/local/tomcat/logs目录下持续生成日志文件,fluentd容器作为sidecar持续采集应用程序的日志文件,并将其保存到后端的日志库中。需要注意的是,webapp容器应负责日志文件的清理工作,以免耗尽磁盘空间。