
Kubernetes的早期版本依靠Heapster来实现完整的性能数据采集和监控功能,Kubernetes从1.8版本开始,性能数据开始以Metrics API方式提供标准化接口,并且从1.10版本开始将Heapster替换为Metrics Server。在Kubernetes新的监控体系中,Metrics Server用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标。对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
Metrics Server在部署完成后,将通过Kubernetes核心API Server的/apis/metrics.k8s.io/v1beta1路径提供Node和Pod的监控数据。Metrics Server源代码和部署配置可以在Kubernete官方GitHub代码库中找到。
Metrics Server提供的数据既可以用于基于CPU和内存的自动水平扩缩容(HPA)功能,也可以用于自动垂直扩缩容(VPA)功能,VPA相关的内容请参考12.3节的说明。
Metrics Server的YAML配置主要包括以下内容。
(1)Deployment和Service的定义及相关RBAC策略:

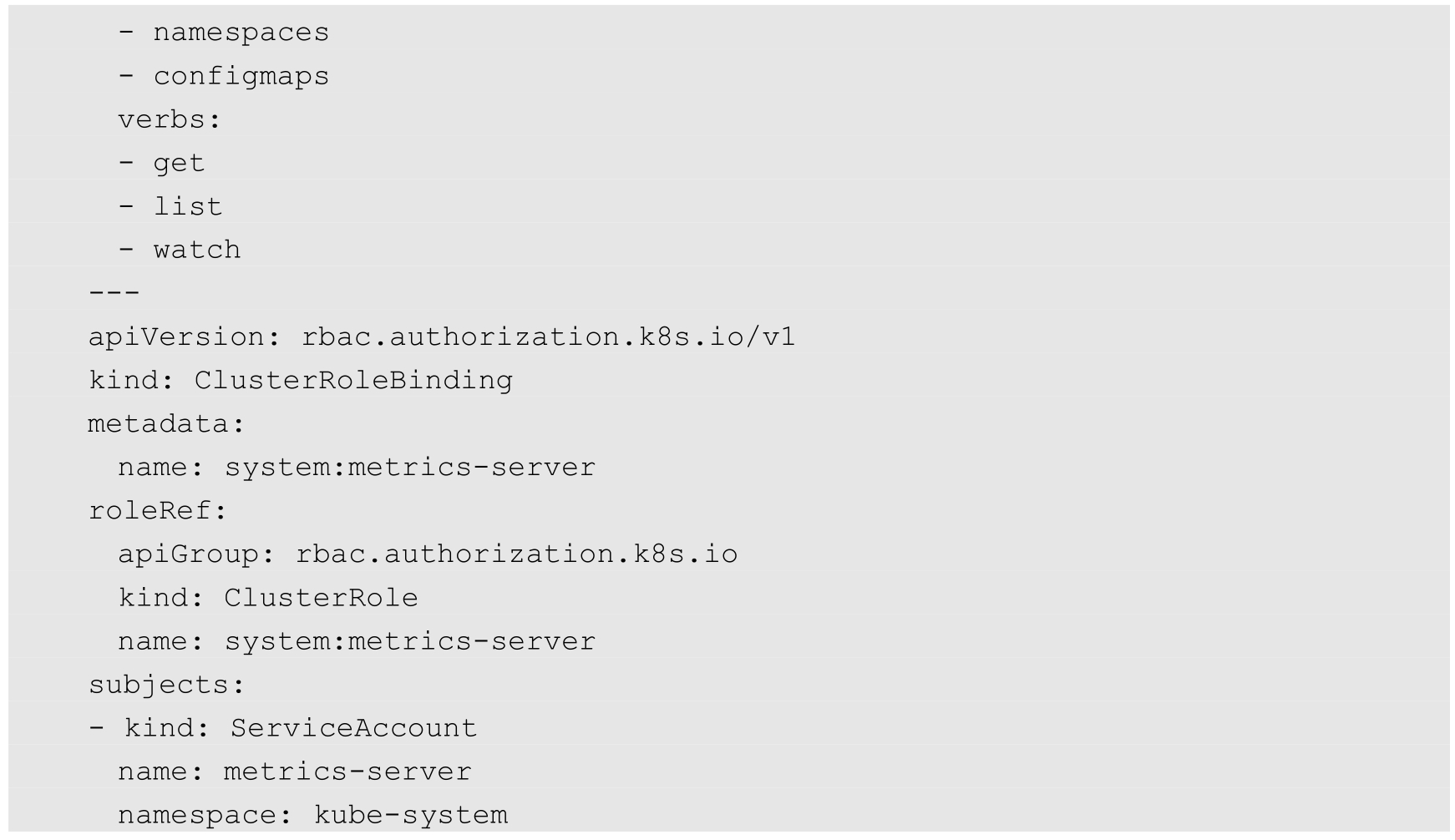
(2)APIService资源及相关RBAC策略:


通过kubectl create命令创建metrics-server服务:


确认metrics-server的Pod启动成功:

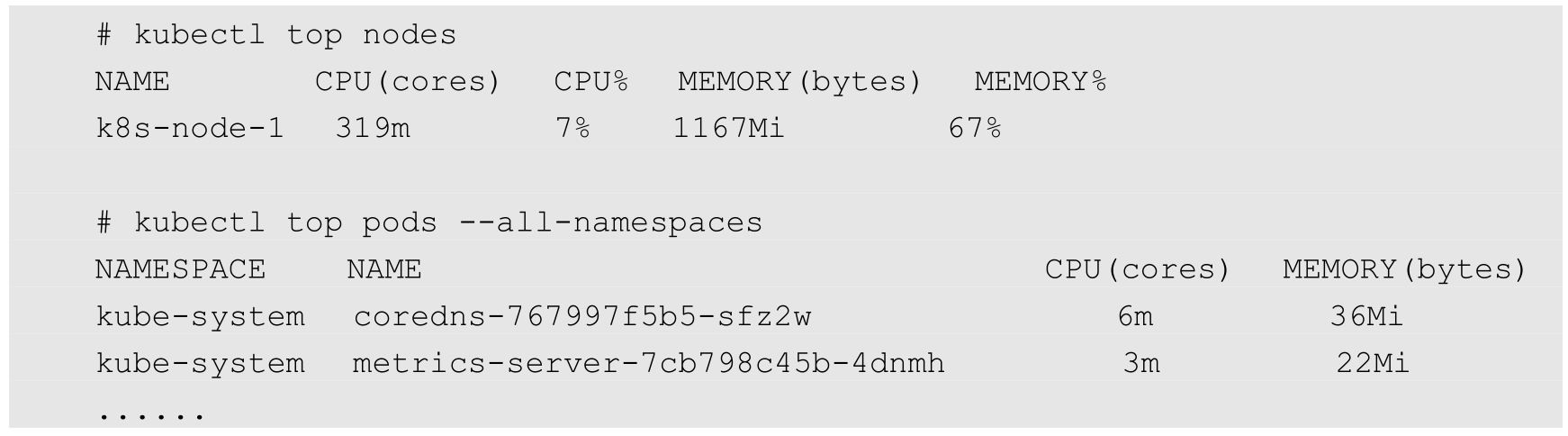
接下来就可以使用kubectl top nodes和kubectl top pods命令监控Node和Pod的CPU、内存资源的使用情况了:
Prometheus是由SoundCloud公司开发的开源监控系统,是继Kubernetes之后CNCF第2个毕业的项目,在容器和微服务领域得到了广泛应用。Prometheus的主要特点如下。
◎ 使用指标名称及键值对标识的多维度数据模型。
◎ 采用灵活的查询语言PromQL。
◎ 不依赖分布式存储,为自治的单节点服务。
◎ 使用HTTP完成对监控数据的拉取。
◎ 支持通过网关推送时序数据。
◎ 支持多种图形和Dashboard的展示,例如Grafana。
Prometheus生态系统由各种组件组成,用于功能的扩充。
◎ Prometheus Server:负责监控数据采集和时序数据存储,并提供数据查询功能。
◎ 客户端SDK:对接Prometheus的开发工具包。
◎ Push Gateway:推送数据的网关组件。
◎ 第三方Exporter:各种外部指标收集系统,其数据可以被Prometheus采集。
◎ AlertManager:告警管理器。
◎ 其他辅助支持工具。
Prometheus的核心组件Prometheus Server的主要功能包括:从Kubernetes Master中获取需要监控的资源或服务信息;从各种Exporter中抓取(Pull)指标数据,然后将指标数据保存在时序数据库(TSDB)中;向其他系统提供HTTP API进行查询;提供基于PromQL语言的数据查询;可以将告警数据推送(Push)给AlertManager,等等。
Prometheus的系统架构图如图10.5所示。
我们可以直接基于官方提供的镜像部署Prometheus,也可以通过Operator模式部署Prometheus。本文以直接部署为例,Operator模式的部署案例可以参考3.12.2节的示例。下面对如何部署Prometheus、node_exporter、Grafana服务进行说明。
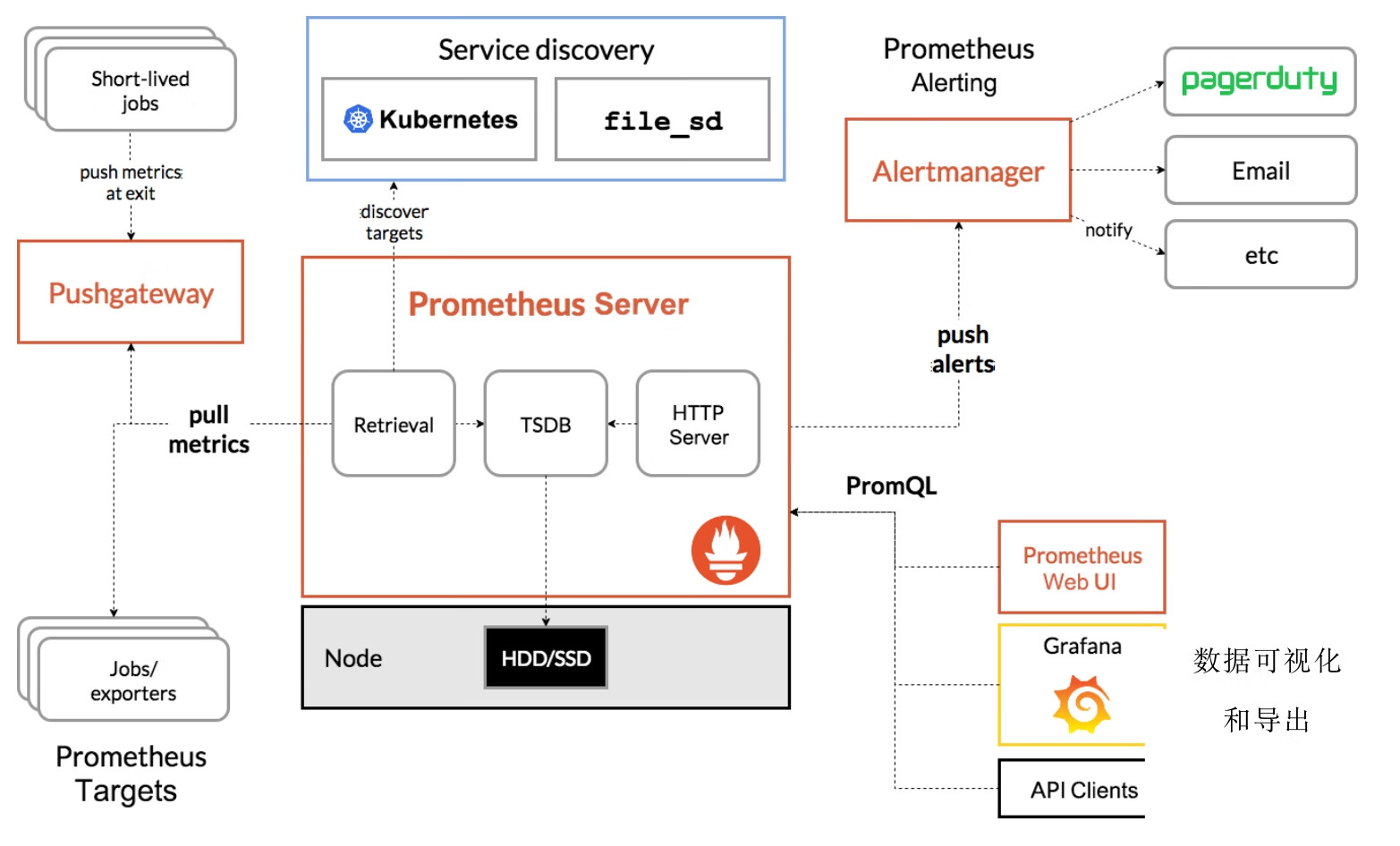
图10.5 Prometheus的系统架构图
首先,创建一个ConfigMap,用于保存Prometheus的主配置文件prometheus.yml,配置需要监控的Kubernetes集群的资源对象或服务(如Master、Node、Pod、Service、Endpoint等),更详细的配置说明请参考Prometheus官网文档:




接下来部署Prometheus Deployment、Service及相关RBAC策略:





Prometheus Deployment的关键配置参数如下。
◎ --config.file:配置文件prometheus.yml的路径。
◎ --storage.tsdb.path:数据存储目录,对其Volume建议使用高可用存储。
◎ --storage.tsdb.retention:数据保存时长,根据数据保留时间需求进行设置。
通过kubectl create命令创建Prometheus服务:

确认Prometheus Pod运行成功:

Prometheus提供了一个简单的Web页面用于查看已采集的监控数据,上面的Service定义了NodePort为9090,我们可以通过访问Node的9090端口访问这个页面,如图10.6所示。
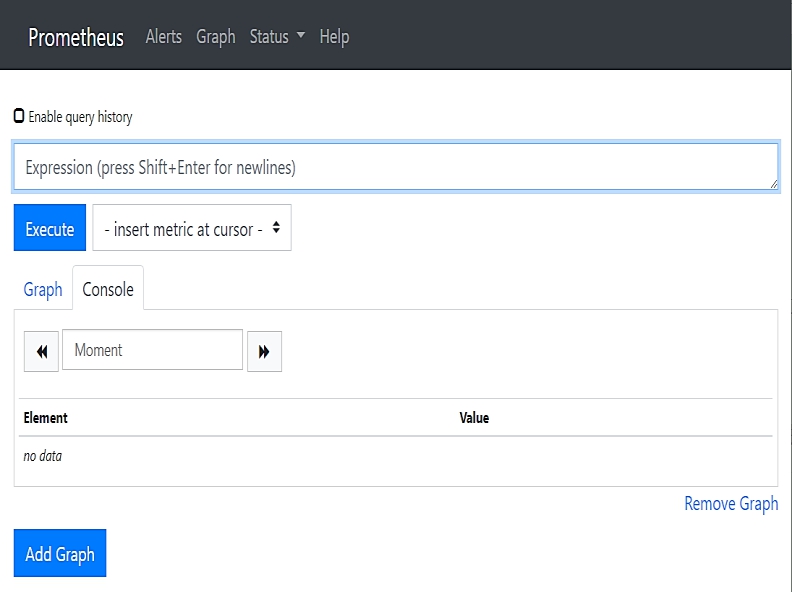
图10.6 Prometheus提供的Web页面
在Prometheus提供的Web页面上,可以输入PromQL查询语句对指标数据进行查询,也可以选择一个指标进行查看,例如选择container_network_receive_bytes_total指标查看容器的网络接收字节数,如图10.7所示。
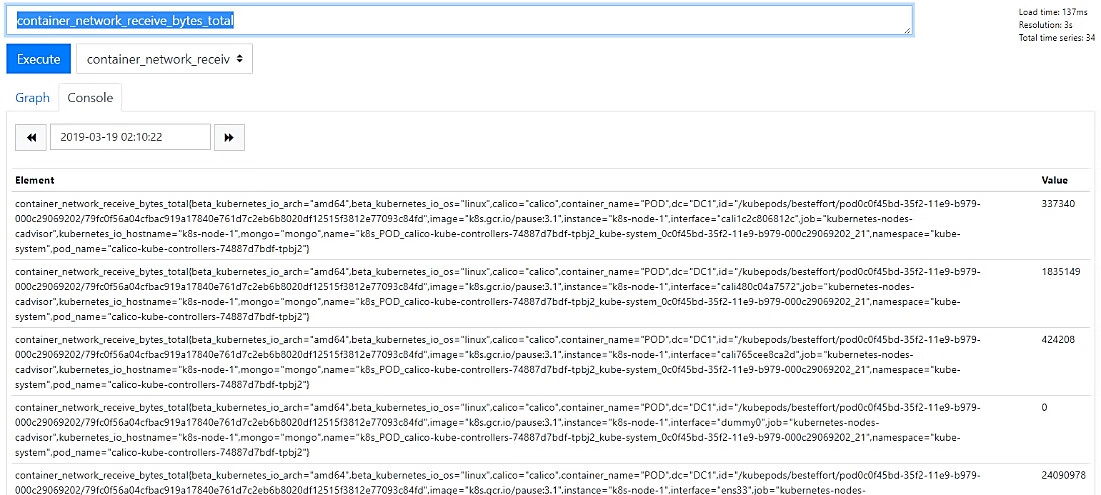
图10.7 在Prometheus页面查看指标的值
单击Graph标签,可以查看该指标的时序图,如图10.8所示。另外,在Status菜单下还可以查看当前运行状态、配置内容(prometheus.yml)、其他规则等信息。例如,在Target页面可以看到Prometheus当前采集的Target列表,如图10.9所示。
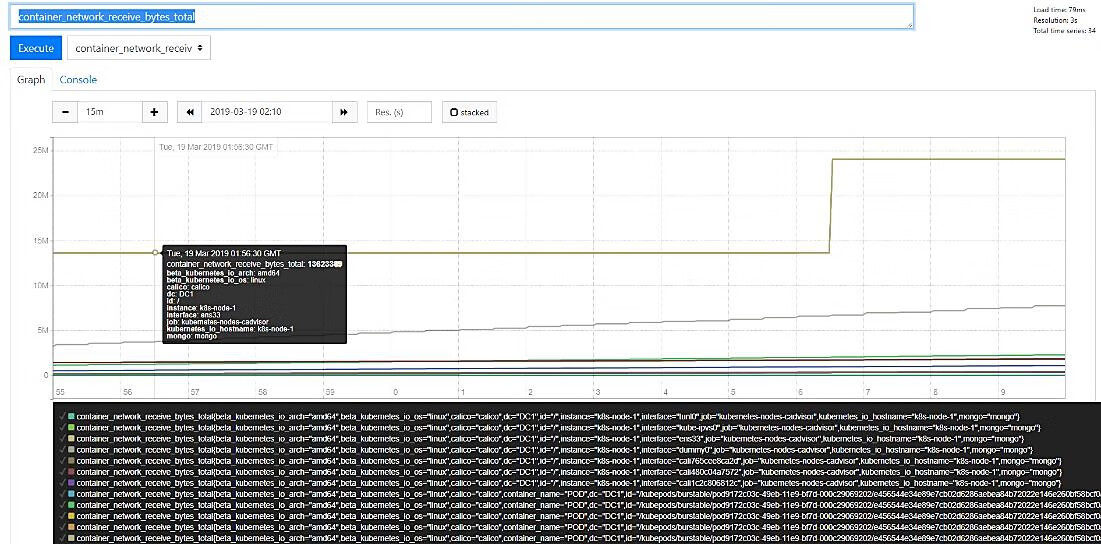
图10.8 在Prometheus页面查询指标的时序图
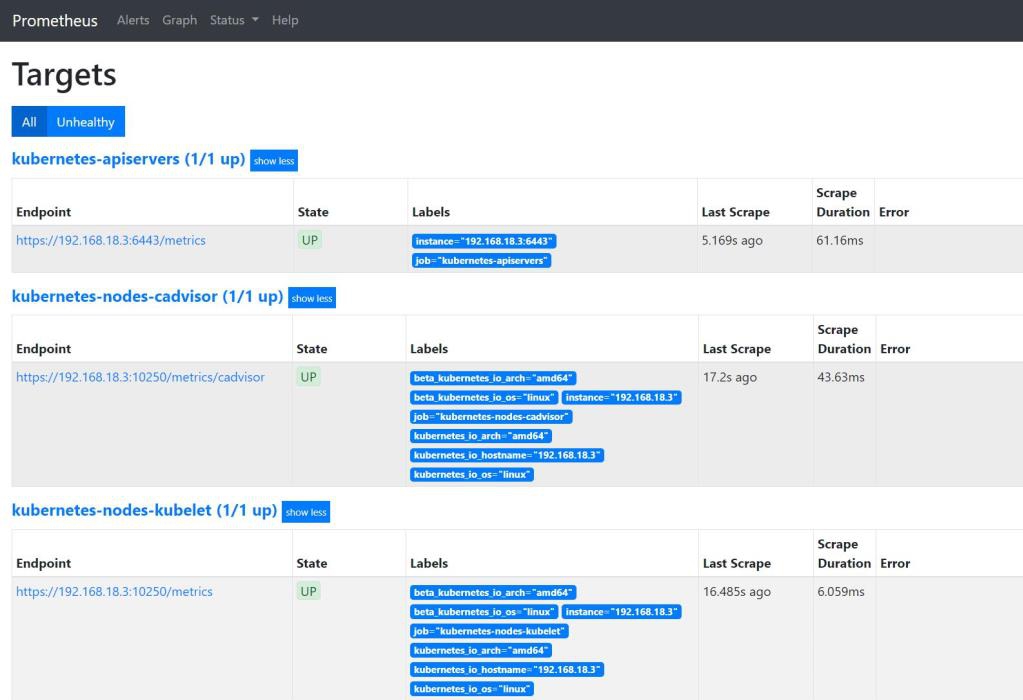
图10.9 Prometheus当前采集的Target列表
Prometheus支持对各种系统和服务部署各种Exporter进行指标数据的采集。目前Prometheus支持多种开源软件的Exporter,包括数据库、硬件系统、消息系统、存储系统、HTTP服务器、日志服务等,可以从Prometheus官网获取各种Exporter的信息。
下面以官方维护的node_exporter为例进行部署。node_exporter主要用于采集主机相关的性能指标数据,其YAML文件示例如下:



通过kubectl create命令创建Prometheus服务:

在部署完成后,在每个Node上都运行了一个node-exporter Pod:

从Prometheus的Web页面就可以查看node-exporter采集的Node指标数据了,包括CPU、内存、文件系统、网络等信息,通过以node_开头的指标名称可以查询,如图10.10所示。
采集的指标来源于arp、bcache、bonding、conntrack、cpu、diskstats等采集器(collector),默认的采集器和可以额外设置的采集器均可在node-exporter的GitHub官网进行查询,如图10.11所示。
图10.10 node_exporter提供的Node性能指标
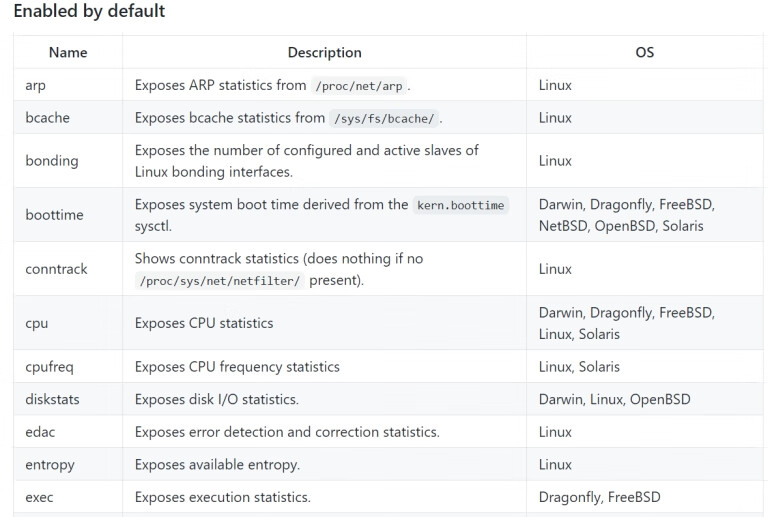
图10.11 查询界面
最后,部署Grafana用于展示专业的监控页面,其YAML文件如下:


部署完成后,通过Kubernetes Master的proxy接口URL访问Grafana页面,例如http://192.168.18.3:8080/api/v1/namespaces/kube-system/services/grafana/proxy。
在Grafana的设置页面添加类型为Prometheus的数据源,输入Prometheus服务的URL(如http://prometheus:9090)进行保存,如图10.12所示。
在Grafana的Dashboard控制面板中导入预置的Dashboard面板,以显示各种监控图表。Grafana官网提供了许多针对Kubernetes集群监控的Dashboard面板,可以下载、导入并使用。图10.13显示了一个可以监控Kubernetes集群总的CPU、内存、文件系统、网络吞吐率的Dashboard。
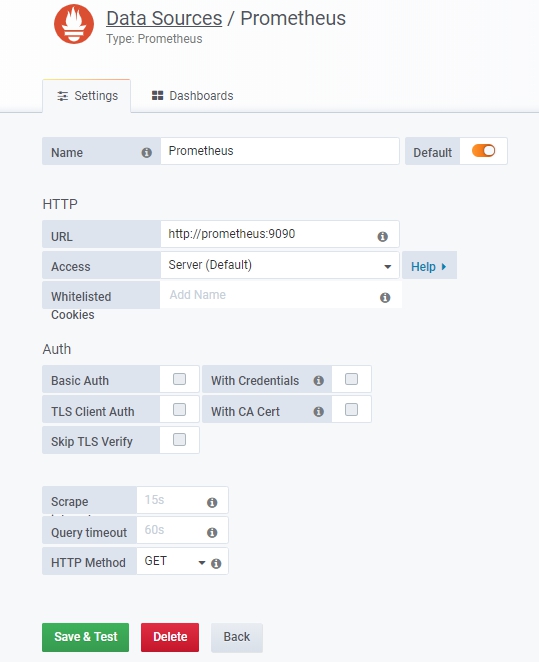
图10.12 Grafana配置数据源页面

图10.13 Kubernetes集群监控页面
至此,基于Prometheus+Grafana的Kubernetes集群监控系统就搭建完成了。