
随着Kubernetes的发展,用户对Kubernetes的扩展性也提出了越来越高的要求。从1.7版本开始,Kubernetes引入扩展API资源的能力,使得开发人员在不修改Kubernetes核心代码的前提下可以对Kubernetes API进行扩展,并仍然使用Kubernetes的语法对新增的API进行操作,这非常适用于在Kubernetes上通过其API实现其他功能(例如第三方性能指标采集服务)或者测试实验性新特性(例如外部设备驱动)。
在Kubernetes中,所有对象都被抽象定义为某种资源对象,同时系统会为其设置一个API URL入口(API Endpoint),对资源对象的操作(如新增、删除、修改、查看等)都需要通过Master的核心组件API Server调用资源对象的API来完成。与API Server的交互可以通过kubectl命令行工具或访问其RESTful API进行。每个API都可以设置多个版本,在不同的API URL路径下区分,例如“/api/v1”或“/apis/extensions/v1beta1”等。使用这种机制后,用户可以很方便地定义这些API资源对象(YAML配置),并将其提交给Kubernetes(调用RESTful API),来完成对容器应用的各种管理工作。
Kubernetes系统内置的Pod、RC、Service、ConfigMap、Volume等资源对象已经能够满足常见的容器应用管理要求,但如果用户希望将其自行开发的第三方系统纳入Kubernetes,并使用Kubernetes的API对其自定义的功能或配置进行管理,就需要对API进行扩展了。目前Kubernetes提供了以下两种API扩展机制供用户扩展API。
(1)CRD:复用Kubernetes的API Server,无须编写额外的API Server。用户只需要定义CRD,并且提供一个CRD控制器,就能通过Kubernetes的API管理自定义资源对象了,同时要求用户的CRD对象符合API Server的管理规范。
(2)API聚合:用户需要编写额外的API Server,可以对资源进行更细粒度的控制(例如,如何在各API版本之间切换),要求用户自行处理对多个API版本的支持。
本节主要对CRD和API聚合这两种API扩展机制的概念和用法进行详细说明。
CRD是Kubernetes从1.7版本开始引入的特性,在Kubernetes早期版本中被称为TPR(ThirdPartyResources,第三方资源)。TPR从Kubernetes 1.8版本开始停用,被CRD全面替换。
CRD本身只是一段声明,用于定义用户自定义的资源对象。但仅有CRD的定义并没有实际作用,用户还需要提供管理CRD对象的CRD控制器(CRD Controller),才能实现对CRD对象的管理。CRD控制器通常可以通过Go语言进行开发,需要遵循Kubernetes的控制器开发规范,基于客户端库client-go实现Informer、ResourceEventHandler、Workqueue等组件具体的功能处理逻辑,详细的开发过程请参考官方示例和client-go库的说明。
与其他资源对象一样,对CRD的定义也使用YAML配置进行声明。以Istio系统中的自定义资源VirtualService为例,配置文件crd-virtualservice.yaml的内容如下:

CRD定义中的关键字段如下。
(1)group:设置API所属的组,将其映射为API URL中/apis/的下一级目录,设置networking.istio.io生成的API URL路径为/apis/networking.istio.io。
(2)scope:该API的生效范围,可选项为Namespaced(由Namespace限定)和Cluster(在集群范围全局生效,不局限于任何命名空间),默认值为Namespaced。
(3)versions:设置此CRD支持的版本,可以设置多个版本,用列表形式表示。目前还可以设置名为version的字段,只能设置一个版本,在将来的Kubernetes版本中会被弃用,建议使用versions进行设置。如果该CRD支持多个版本,则每个版本都会在API URL“/apis/networking.istio.io”的下一级进行体现,例如/apis/networking.istio.io/v1或/apis/networking.istio.io/v1alpha3等。每个版本都可以设置下列参数。
◎ name:版本的名称,例如v1、v1alpha3等。
◎ served:是否启用,设置为true表示启用。
◎ storage:是否进行存储,只能有一个版本被设置为true。
(4)names:CRD的名称,包括单数、复数、kind、所属组等名称的定义,可以设置如下参数。
◎ kind:CRD的资源类型名称,要求以驼峰式命名规范进行命名(单词的首字母都大写),例如VirtualService。
◎ listKind:CRD列表,默认设置为<kind>List格式,例如VirtualServiceList。
◎ singular:单数形式的名称,要求全部小写,例如virtualservice。
◎ plural:复数形式的名称,要求全部小写,例如virtualservices。
◎ shortNames:缩写形式的名称,要求全部小写,例如vs。
◎ categories:CRD所属的资源组列表。例如,VirtualService属于istio-io组和networking-istio-io组,用户通过查询istio-io组和networking-istio-io组,也可以查询到该CRD实例。
使用kubectl create命令完成CRD的创建:

在CRD创建成功后,由于本例的scope设置了命名空间限定,所以可以通过API Endpoint“/apis/networking.istio.io/v1alpha3/namespaces/<namespace>/virtualservices/”管理该CRD资源。
用户接下来就可以基于该CRD的定义创建自定义资源对象了。
基于CRD的定义,用户可以像创建Kubernetes系统内置的资源对象(如Pod)一样创建CRD资源对象。在下面的例子中,virtualservice-helloworld.yaml定义了一个类型为VirtualService的资源对象:


除了需要设置该CRD资源对象的名称,还需要在spec段设置相应的参数。在spec中可以设置的字段是由CRD开发者自定义的,需要根据CRD开发者提供的手册进行配置。这些参数通常包含特定的业务含义,由CRD控制器进行处理。
使用kubectl create命令完成CRD资源对象的创建:

然后,用户就可以像操作Kubernetes内置的资源对象(如Pod、RC、Service)一样去操作CRD资源对象了,包括查看、更新、删除和watch等操作。
查看CRD资源对象:

也可以通过CRD所属的categories进行查询:

随着Kubernetes的演进,CRD也在逐步添加一些高级特性和功能,包括subresources子资源、校验(Validation)机制、自定义查看CRD时需要显示的列,以及finalizer预删除钩子。
Kubernetes从1.11版本开始,在CRD的定义中引入了名为subresources的配置,可以设置的选项包括status和scale两类。
◎ status:启用/status路径,其值来自CRD的.status字段,要求CRD控制器能够设置和更新这个字段的值。
◎ scale:启用/scale路径,支持通过其他Kubernetes控制器(如HorizontalPodAutoscaler控制器)与CRD资源对象实例进行交互。用户通过kubectl scale命令也能对该CRD资源对象进行扩容或缩容操作,要求CRD本身支持以多个副本的形式运行。
下面是一个设置了subresources的CRD示例:

基于该CRD的定义,创建一个自定义资源对象my-crontab.yaml:

之后就能通过API Endpoint查看该资源对象的状态了:

并查看该资源对象的扩缩容(scale)信息:

用户还可以使用kubectl scale命令对Pod的副本数量进行调整,例如:

Kubernetes从1.8版本开始引入了基于OpenAPI v3 schema或validatingadmissionwebhook的校验机制,用于校验用户提交的CRD资源对象配置是否符合预定义的校验规则。该机制到Kubernetes 1.13版本时升级为Beta版本。要使用该功能,需要为kube-apiserver服务开启--feature-gates=CustomResourceValidation=true特性开关。
下面的例子为CRD定义中的两个字段(cronSpec和replicas)设置了校验规则:

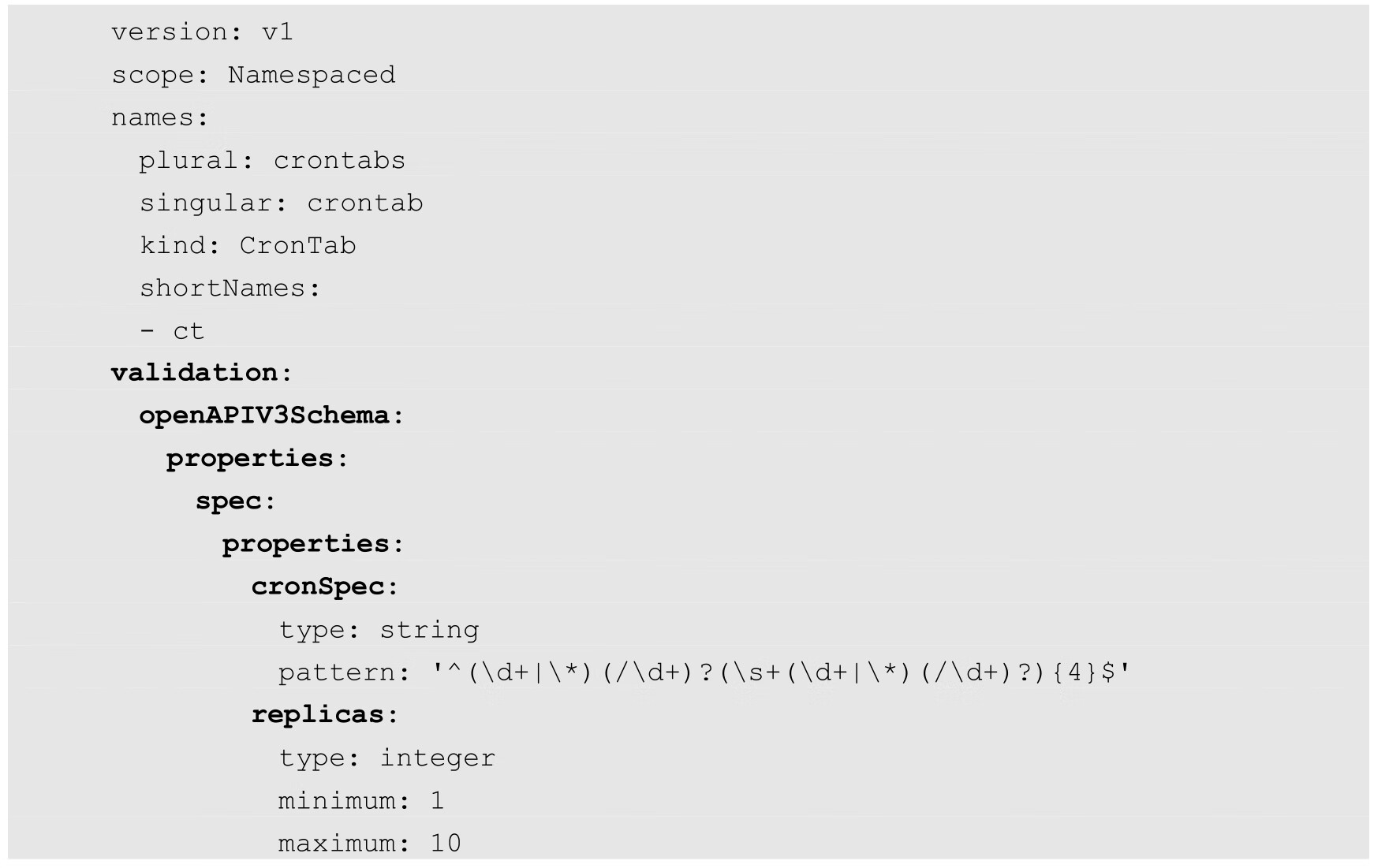
校验规则如下。
◎ spec.cronSpec:必须为字符串类型,并且满足正则表达式的格式。
◎ spec.replicas:必须将其设置为1~10的整数。
对于不符合要求的CRD资源对象定义,系统将拒绝创建。
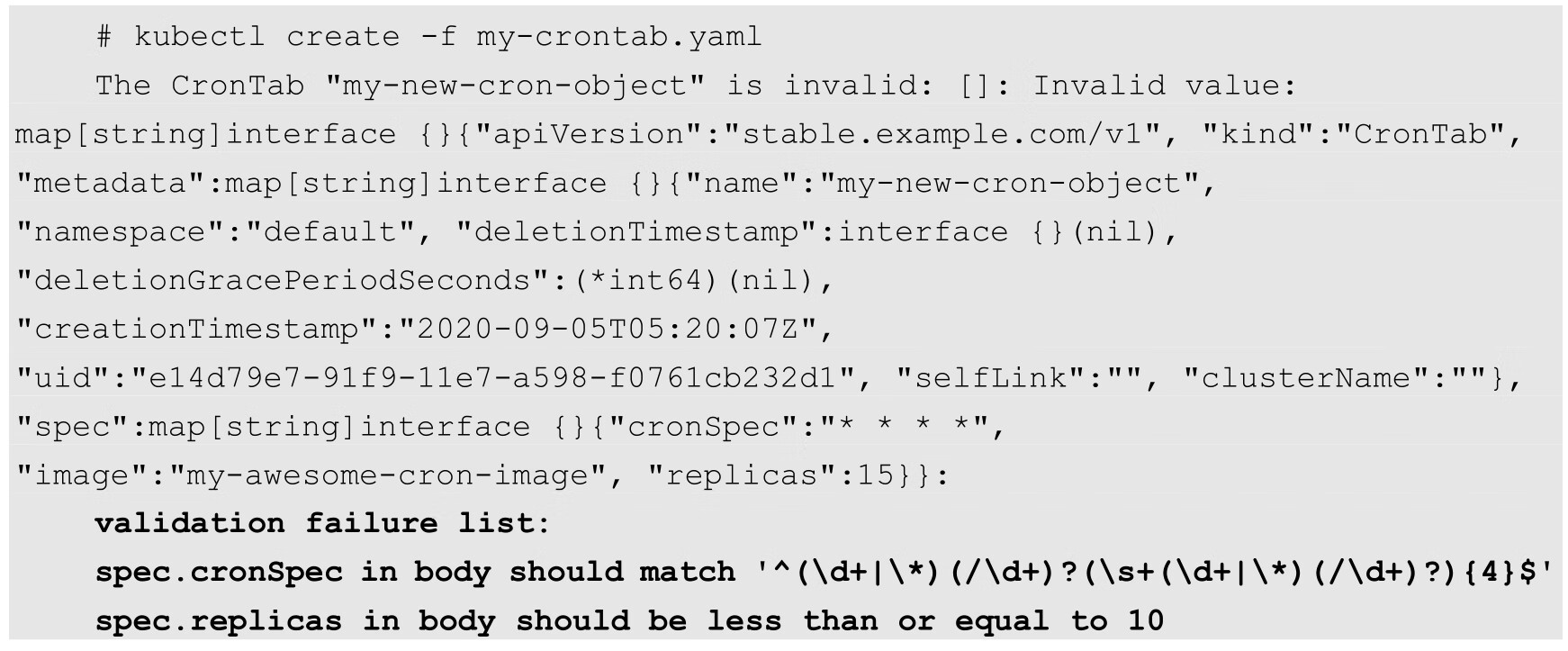
例如,下面的my-crontab.yaml示例违反了CRD中validation设置的校验规则,即cronSpec没有满足正则表达式的格式,replicas的值大于10:

创建时,系统将报出validation失败的错误信息:
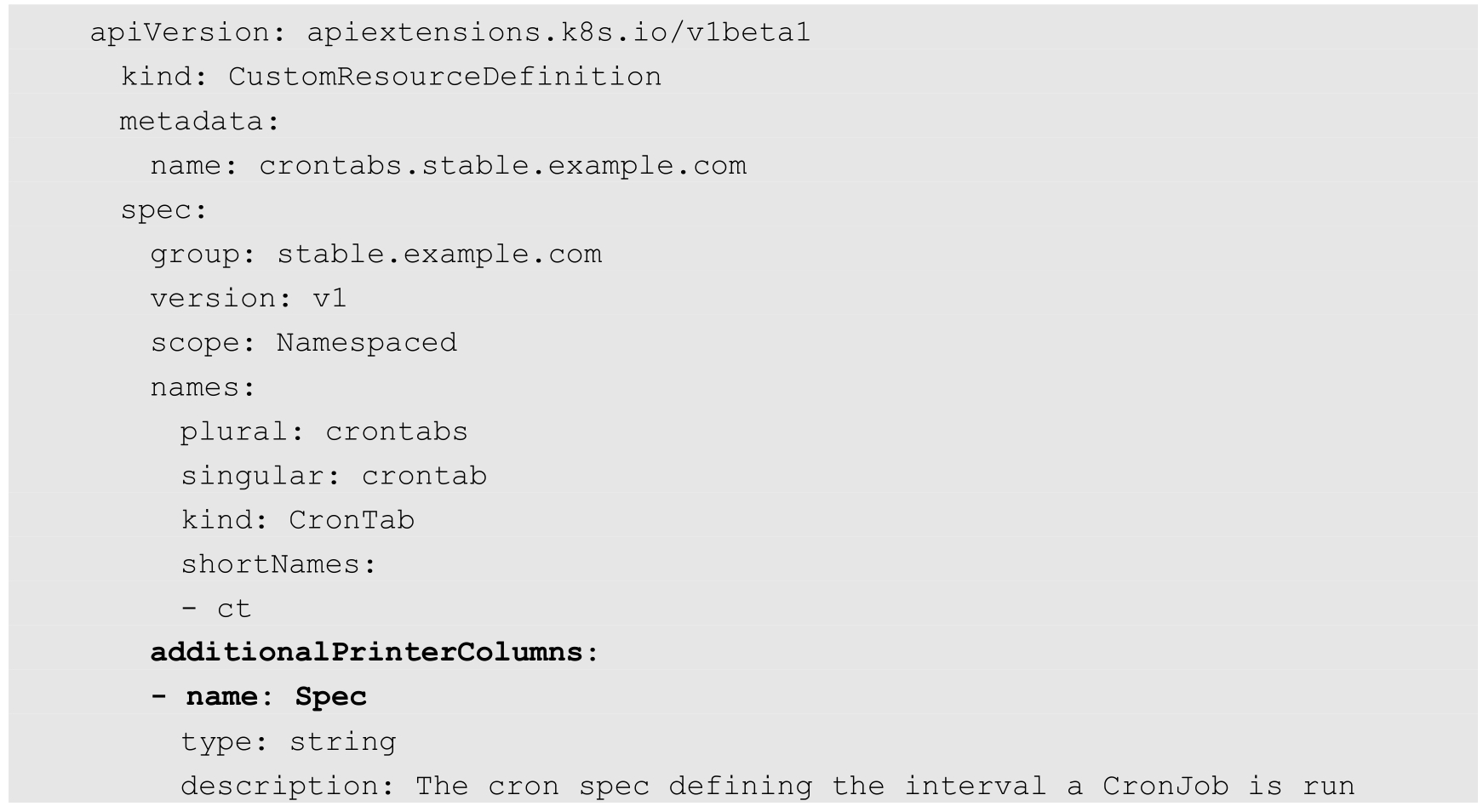
从Kubernetes 1.11版本开始,通过kubectl get命令能够显示哪些字段由服务端(API Server)决定,还支持在CRD中设置需要在查看(get)时显示的自定义列,在spec.additionalPrinterColumns字段设置即可。
在下面的例子中设置了3个需要显示的自定义列Spec、Replicas和Age,并在JSONPath字段设置了自定义列的数据来源:

运行kubectl get命令查看CronTab资源对象,会显示出这3个自定义列:

Finalizer设置的方法在删除CRD资源对象时调用,以实现CRD资源对象的清理工作。
在下面的例子中为CRD“CronTab”设置了一个finalizer(也可以设置多个),其值为URL“finalizer.stable.example.com”:

在用户发起删除该资源对象的请求时,Kubernetes不会直接删除这个资源对象,而是在元数据部分设置时间戳“metadata.deletionTimestamp”的值,将其标记为开始删除该CRD对象。然后控制器开始执行finalizer定义的钩子方法“finalizer.stable.example.com”进行清理工作。对于耗时较长的清理操作,还可以设置metadata.deletionGracePeriodSeconds超时时间,在超过这个时间后由系统强制终止钩子方法的执行。在控制器执行完钩子方法后,控制器应负责删除相应的finalizer。当全部finalizer都触发控制器执行钩子方法并都被删除之后,Kubernetes才会最终删除该CRD资源对象。
Kubernetes发展到1.17版本时,CRD资源对象的多版本特性达到稳定阶段。用户在定义一个CRD时,需要在spec.versions字段中列出支持的全部版本号,例如在下面的例子中,CRD支持v1beta1、v1两个版本:

问题来了,在支持多个版本的CRD资源对象时,存在低版本的资源对象升级到高版本的转换问题,所以Kubernetes同时实现了Webhook Conversion for Custom Resources特性,通过使用Webhook回调接口来完成CRD资源对象多版本的转换问题。具体做法:开发并部署一个CRD多版本对象转换的Webhook服务;通过修改spec中的conversion部分来使用上述自定义转换的Webhook。
在CRD对象中,除了部分字段(如apiVersion、kind和metadata等)会被API Server强制校验,其他字段都是用户自定义的,并不会被API Server校验,这就存在一些问题,比如某些数据被运维人员或其他不清楚此CRD格式的人设置为非法数据,仍然会被API Server接受并更新,导致应用失败或异常。因此,Kubernetes也为CRD对象增加了结构化定义和相关数据校验的特性,这一特性是通过OpenAPI v3.0 validation schema实现的,即在CRD中增加了一个schema的定义。下面是一个完整的例子:
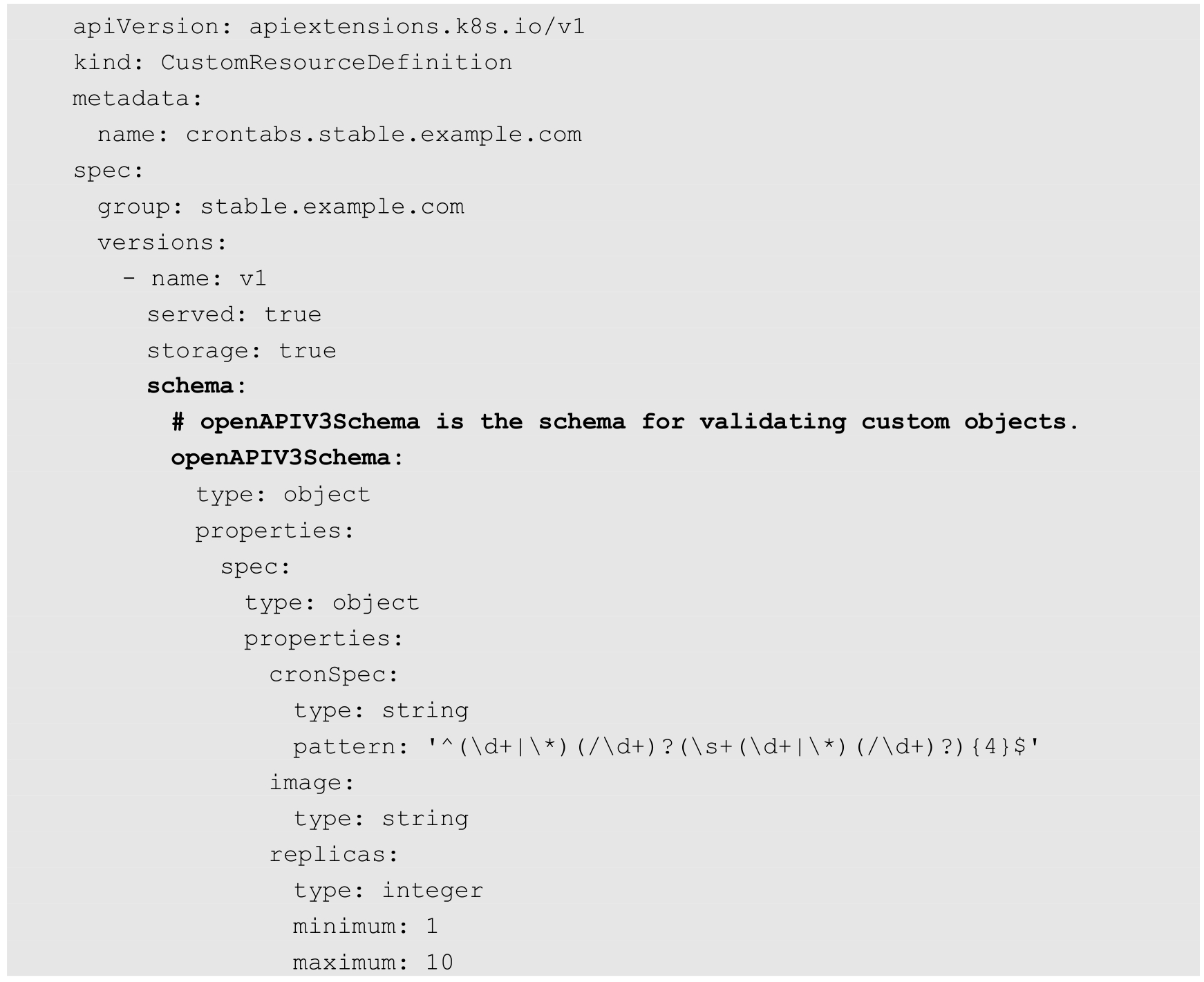
CRD的OpenAPI v3.0 validation schema具有以下一些特性。
◎ 可以给CRD中的某个字段设置默认值,即Defaulting特性,此特性在Kubernetes 1.17时升级为GA版本。
◎ 通过validation schema校验的CRD对象的数据被写入etcd里持久保存,如果在CRD里出现一个未知的字段,即schema里没有声明的字段,则这个字段会被“剪除”,这个特性被称为Field pruning。
通过增加OpenAPI v3.0 validation schema,CRD也能像普通的Kubernetes资源对象一样,具备结构化数据存储能力并且确保写入API Server的数据都是合法的。如果schema方式还不足以验证特殊的CRD数据结构,则还可以通过Admission Webhooks实现更为复杂的数据校验规则。
CRD极大扩展了Kubernetes的能力,使用户像操作Pod一样操作自定义的各种资源对象。CRD已经在一些基于Kubernetes的第三方开源项目中得到广泛应用,包括CSI存储插件、Device Plugin(GPU驱动程序)、Istio(Service Mesh管理)等,已经逐渐成为扩展Kubernetes能力的标准。
API聚合机制是Kubernetes 1.7版本引入的特性,能够将用户扩展的API注册到kube-apiserver上,仍然通过API Server的HTTP URL对新的API进行访问和操作。为了实现这个机制,Kubernetes在kube-apiserver服务中引入了一个API聚合层(API Aggregation Layer),用于将扩展API的访问请求转发到用户提供的API Server上,由它完成对API请求的处理。
设计API聚合机制的主要目标如下。
◎ 增加API的扩展性:使得开发人员可以编写自己的API Server来发布其API,而无须对Kubernetes核心代码进行任何修改。
◎ 无须等待Kubernetes核心团队的繁杂审查:允许开发人员将其API作为单独的API Server发布,使集群管理员不用对Kubernetes的核心代码进行修改就能使用新的API,也就无须等待社区繁杂的审查了。
◎ 支持实验性新特性API开发:可以在独立的API聚合服务中开发新的API,不影响系统现有的功能。
◎ 确保新的API遵循Kubernetes的规范:如果没有API聚合机制,开发人员就可能被迫推出自己的设计,可能不遵循Kubernetes规范。
总的来说,API聚合机制的目标是提供集中的API发现机制和安全的代理功能,将开发人员的新API动态地、无缝地注册到Kubernetes API Server中进行测试和使用。
下面对API聚合机制的使用方式进行详细说明。
为了能够将用户自定义的API注册到Master的API Server中,首先需要配置kube-apiserver服务的以下启动参数来启用API聚合功能。
◎ --requestheader-client-ca-file=/etc/kubernetes/ssl_keys/ca.crt:客户端CA证书。
◎ --requestheader-allowed-names=:允许访问的客户端common names列表,通过header中--requestheader-username-headers参数指定的字段获取。客户端common names的名称需要在client-ca-file中进行设置,将其设置为空值时,表示任意客户端都可访问。
◎ --requestheader-extra-headers-prefix=X-Remote-Extra-:请求头中需要检查的前缀名。
◎ --requestheader-group-headers=X-Remote-Group:请求头中需要检查的组名。
◎ --requestheader-username-headers=X-Remote-User:请求头中需要检查的用户名。
◎ --proxy-client-cert-file=/etc/kubernetes/ssl_keys/kubelet_client.crt:在请求期间验证Aggregator的客户端CA证书。
◎ --proxy-client-key-file=/etc/kubernetes/ssl_keys/kubelet_client.key:在请求期间验证Aggregator的客户端私钥。
如果kube-apiserver所在的主机上没有运行kube-proxy,即无法通过服务的ClusterIP地址进行访问,那么还需要设置以下启动参数:

在设置完成后重启kube-apiserver服务,就启用API聚合功能了。
在启用了API Server的API聚合功能之后,用户就能将自定义API资源注册到Kubernetes Master的API Server中了。用户只需配置一个APIService资源对象,就能进行注册了。APIService示例的YAML文件如下:
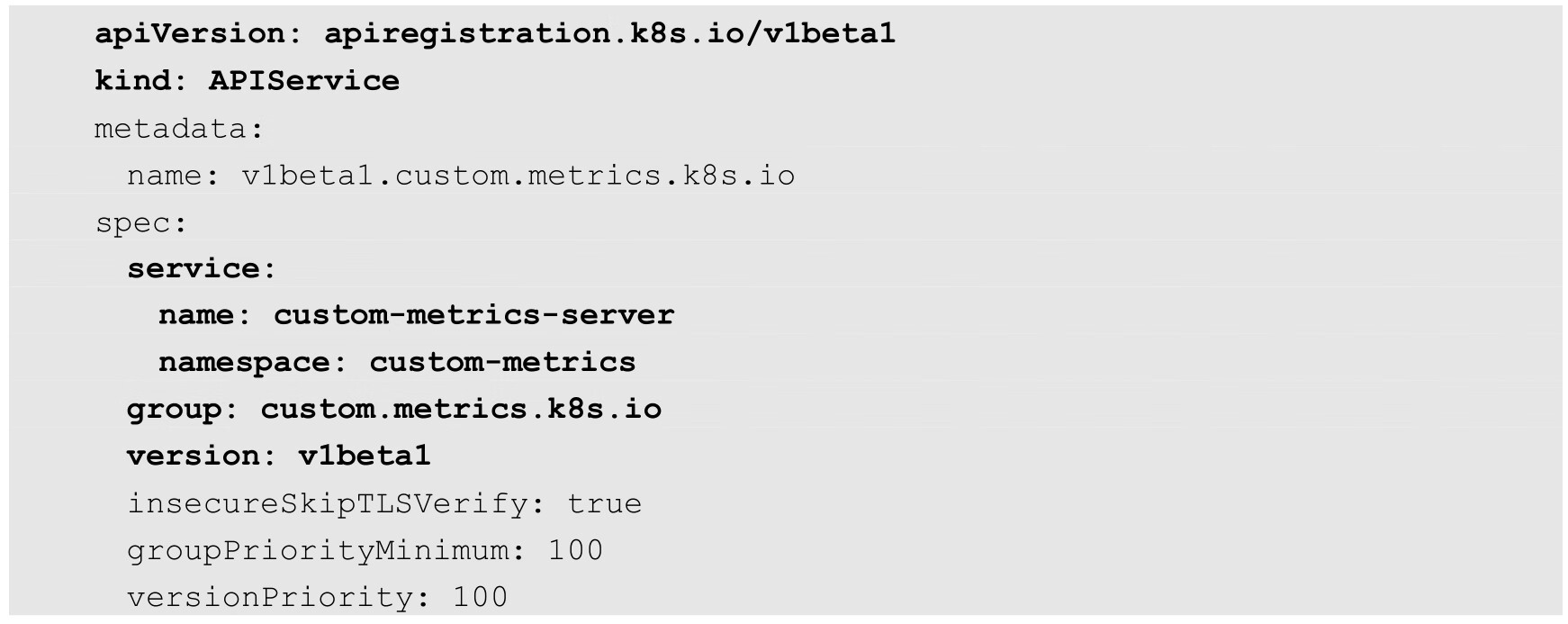
在这个APIService中设置的API组名为custom.metrics.k8s.io,版本号为v1beta1,这两个字段将作为API路径的子目录注册到API路径/apis/下。注册成功后,就能通过Master API路径/apis/custom.metrics.k8s.io/v1beta1访问自定义的API Server了。
在service段通过name和namespace设置了后端的自定义API Server,本例中的服务名为custom-metrics-server,命名空间为custom-metrics。
通过kubectl create命令将这个APIService定义发送给Master,就完成了注册操作。之后,通过Master API Server对/apis/custom.metrics.k8s.io/v1beta1路径的访问都会被API聚合层代理转发到后端服务custom-metrics-server.custom-metrics.svc上了。
仅仅注册APIService资源还是不够的,用户对/apis/custom.metrics.k8s.io/v1beta1路径的访问实际上都被转发给了custom-metrics-server.custom-metrics.svc服务。这个服务通常能以普通Pod的形式在Kubernetes集群中运行。当然,这个服务需要由自定义API的开发者提供,并且需要遵循Kubernetes的开发规范,详细的开发示例可以参考官方给出的示例说明。
下面是部署自定义API Server的常规操作步骤。
(1)确保APIService API已启用,这需要通过kube-apiserver的启动参数--runtime-config进行设置,默认是启用的。
(2)建议创建一个RBAC规则,允许添加APIService资源对象,因为API扩展对整个Kubernetes集群都生效,所以不推荐在生产环境中对API扩展进行开发或测试。
(3)创建一个新的命名空间用于运行扩展的API Server。
(4)创建一个CA证书用于对自定义API Server的HTTPS安全访问进行签名。
(5)创建服务端证书和秘钥用于自定义API Server的HTTPS安全访问。服务端证书应该由上面提及的CA证书进行签名,也应该包含含有DNS域名格式的CN名称。
(6)在新的命名空间中使用服务端证书和秘钥创建Kubernetes Secret对象。
(7)部署自定义API Server实例,通常可以以Deployment形式进行部署,并且将之前创建的Secret挂载到容器内部。该Deployment也应被部署在新的命名空间中。
(8)确保自定义的API Server通过Volume加载了Secret中的证书,这将用于后续的HTTPS握手校验。
(9)在新的命名空间中创建一个Service Account对象。
(10)创建一个ClusterRole用于对自定义API资源进行操作。
(11)使用之前创建的ServiceAccount为刚刚创建的ClusterRole创建一个ClusterRolebinding。
(12)使用之前创建的ServiceAccount为系统ClusterRole“system:auth-delegator”创建一个ClusterRolebinding,以使其可以将认证决策代理转发给Kubernetes核心API Server。
(13)使用之前创建的ServiceAccount为系统Role“extension-apiserver-authentication-reader”创建一个Rolebinding,以允许自定义API Server访问名为“extension-apiserver-authentication”的系统ConfigMap。
(14)创建APIService资源对象。
(15)访问APIService提供的API URL路径,验证对资源的访问能否成功。
下面以部署Metrics Server为例,说明一个聚合API的实现方式。
随着API聚合机制的出现,Heapster也进入弃用阶段,逐渐被Metrics Server替代。Metrics Server通过聚合API提供Pod和Node的资源使用数据,供HPA控制器、VPA控制器及kubectl top命令使用。Metrics Server的源码可以在其GitHub代码库中找到,在部署完成后,Metrics Server将通过Kubernetes核心API Server的/apis/metrics.k8s.io/v1beta1路径提供Pod和Node的监控数据。
首先,部署Metrics Server实例,在下面的YAML配置中包含一个ServiceAccount、一个Deployment和一个Service的定义:


然后,创建Metrics Server所需的RBAC权限配置:


最后,定义APIService资源,主要设置自定义API的组(group)、版本号(version)及对应的服务(metrics-server.kube-system):

在所有资源都成功创建之后,在命名空间kube-system中会看到新建的metrics-server Pod。
通过Kubernetes Master API Server的URL“/apis/metrics.k8s.io/v1beta1”就能查询到Metrics Server提供的Pod和Node的性能数据了:


