Docker给我们带来了不同的网络模式,Kubernetes也以一种不同的方式来解决这些网络模式的挑战,但有些难以理解,特别是对于刚开始接触Kubernetes网络的开发者来说。前面讲解了Kubernetes、Docker理论,本节将通过一个完整的实验,从部署一个Pod开始,一步一步地部署Kubernetes的组件,剖析Kubernetes在网络层是如何实现及工作的。
这里使用虚拟机完成实验。如果要部署在物理机器上或者云服务商的环境中,则涉及的网络模型很可能稍微不同。不过从网络角度来看,Kubernetes的机制是类似且一致的。
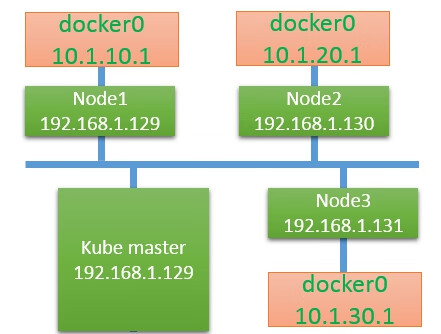
我们的实验环境如图7.11所示。
图7.11 实验环境
Kubernetes的网络模型要求每个Node上的容器都可以相互访问。
默认的Docker网络模型提供了一个IP地址段是172.17.0.0/16的docker0网桥。每个容器都会在这个子网内获得IP地址,并且将docker0网桥的IP地址(172.17.42.1)作为其默认网关。需要注意的是,Docker宿主机外面的网络不需要知道任何关于这个172.17.0.0/16的信息或者知道如何连接到其内部,因为Docker的宿主机针对容器发出的数据,在物理网卡地址后面都做了IP伪装MASQUERADE(隐含NAT)。也就是说,在网络上看到的任何容器数据流都来源于该Docker节点的物理IP地址。这里所说的网络都指连接这些主机的物理网络。这个模型便于使用,但是并不完美,需要依赖端口映射的机制。
在Kubernetes的网络模型中,每台主机上的docker0网桥都是可以被路由到的。也就是说,在部署了一个Pod时,在同一个集群中,各主机都可以访问其他主机上的Pod IP,并不需要在主机上做端口映射。综上所述,我们可以在网络层将Kubernetes的节点看作一个路由器。如果将实验环境改画成一个网络图,那么它看起来如图7.12所示。

图7.12 实验环境网络图
为了支持Kubernetes网络模型,我们采取了直接路由的方式来实现,在每个Node上都配置相应的静态路由项,例如在192.168.1.129这个Node上配置了两个路由项:

这意味着,每一个新部署的容器都将使用这个Node(docker0的网桥IP)作为它的默认网关。而这些Node(类似路由器)都有其他docker0的路由信息,这样它们就能够相互连通了。
接下来通过一些实际案例,看看Kubernetes在不同的场景下其网络部分到底做了什么。
部署的RC/Pod描述文件如下(frontend-controller.yaml):


为了便于观察,这里假定在一个空的Kubernetes集群上运行,提前清理了所有Replication Controller、Pod和其他Service:

让我们检查一下此时某个Node上的网络接口都有哪些。Node1的状态如下:
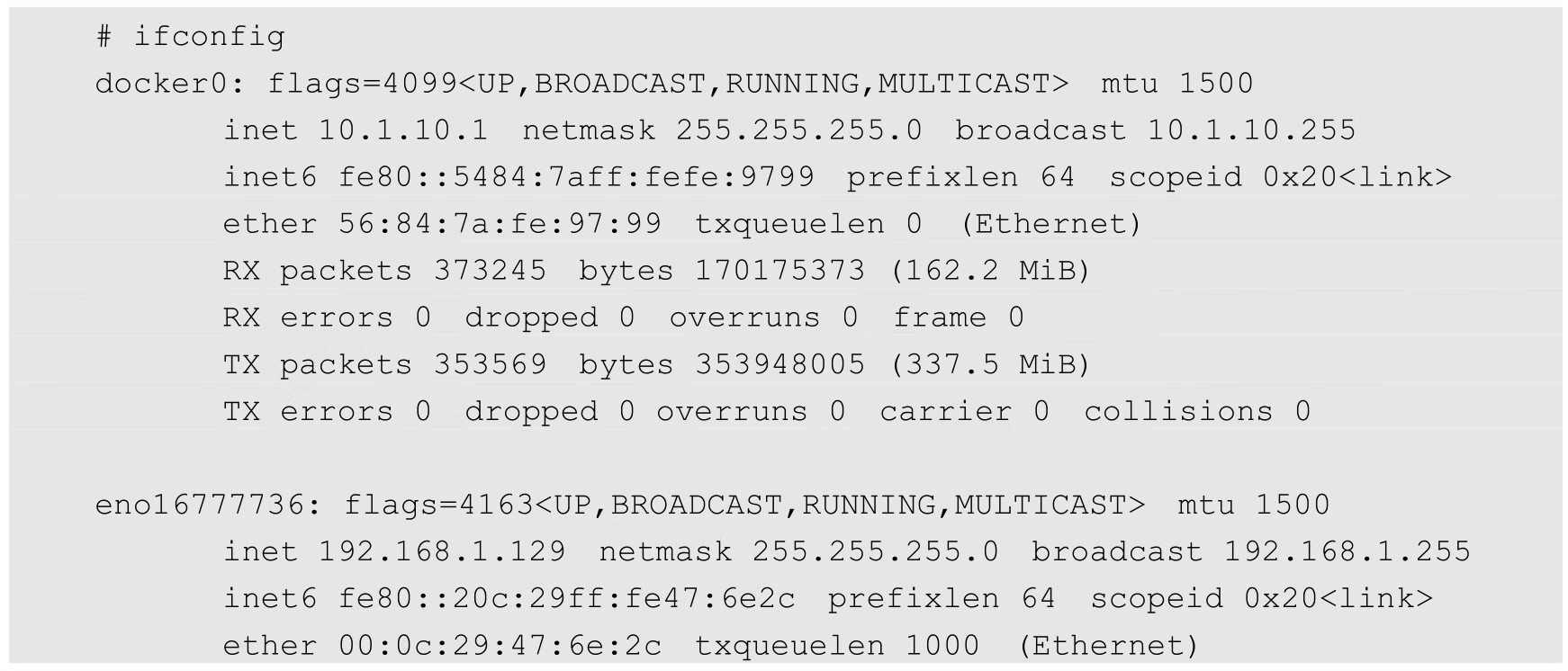
可以看出,有一个docker0网桥和一个本地地址的网络端口。现在部署一下我们在前面准备的RC/Pod配置文件,看看会发生什么:

可以看到一些有趣的事情。Kubernetes为这个Pod找了一个主机192.168.1.130(Node2)来运行它。另外,这个Pod获得了Node2的docker0网桥上的一个IP地址。我们登录Node2查看正在运行的容器:

在Node2上现在运行了两个容器,在我们的RC/Pod定义文件中仅仅包含一个,那么这第2个是从哪里来的呢?第2个看起来运行的是一个叫作k8s.gcr.io/pause:latest的镜像,而且这个容器已经有端口映射到它上面了,为什么这样呢?让我们深入容器内部去看一下具体原因。使用Docker的inspect命令来查看容器的详细信息,特别要关注容器的网络模型:

有趣的结果是,在查看完每个容器的网络模型后,我们都可以看到这样的配置:我们检查的第1个容器是运行了k8s.gcr.io/pause:latest镜像的容器,它使用了Docker默认的网络模型bridge;而我们检查的第2个容器,也就是在RC/Pod中定义运行的php-redis容器,使用了非默认的网络配置和映射容器的模型,指定了映射目标容器为k8s.gcr.io/pause:latest。
一起来仔细思考这个过程,为什么Kubernetes要这么做呢?
首先,一个Pod内的所有容器都需要共用同一个IP地址,这就意味着一定要使用网络的容器映射模式。然而,为什么不能只启动1个容器,而将第2个容器关联到第1个容器呢?我们认为Kubernetes是从两方面来考虑这个问题的:首先,如果在Pod内有多个容器,则可能很难连接这些容器;其次,后面的容器还要依赖第1个被关联的容器,如果第2个容器关联到第1个容器,且第1个容器死掉的话,那么第2个容器也将死掉。启动一个基础容器,然后将Pod内的所有容器都连接到它上面会更容易一些。因为我们只需为基础的k8s.gcr.io/pause容器执行端口映射规则,这也简化了端口映射的过程。所以我们启动Pod后的网络模型类似于图7.13。
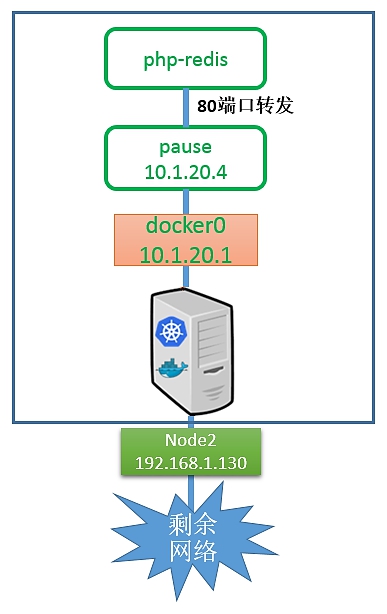
图7.13 启动Pod后的网络模型
在这种情况下,实际Pod的IP数据流的网络目标都是这个k8s.gcr.io/pause容器。图7.13有点儿取巧地显示了是k8s.gcr.io/pause容器将端口80的流量转发给了相关容器。而Pause容器只是看起来转发了网络流量,但它并没有真的这么做。实际上,应用容器直接监听了这些端口,和k8s.gcr.io/pause容器共享同一个网络堆栈。这就是为什么实际容器的端口映射在Pod内都显示到k8s.gcr.io/pause容器上了。我们可以通过docker port命令来检验一下:

综上所述,k8s.gcr.io/pause容器实际上只是负责接管这个Pod的Endpoint,并没有做更多的事情。那么Node呢?它需要将数据流传给k8s.gcr.io/pause容器吗?我们来检查一下iptables的规则,看看有什么发现:


上面的这些规则并没有被应用到我们刚刚定义的Pod上。当然,Kubernetes会给每一个Kubernetes节点都提供一些默认的服务,上面的规则就是Kubernetes默认的服务所需的。关键是,我们没有看到任何IP伪装的规则,并且没有任何指向Pod 10.1.20.4内的端口映射。
我们已经了解了Kubernetes如何处理基本的元素即Pod的连接问题,接下来看一下它是如何处理Service的。Service允许我们在多个Pod之间抽象一些服务,而且服务可以通过提供同一个Service的多个Pod之间的负载均衡机制来支持水平扩展。我们再次将环境初始化,删除刚刚创建的RC或Pod来确保集群是空的:


然后准备一个名为frontend的Service配置文件:

接着在Kubernetes集群中定义这个服务:

在服务正确创建后,可以看到Kubernetes集群已经为这个服务分配了一个虚拟IP地址20.1.244.75,这个IP地址是在Kubernetes的Portal Network中分配的。而这个Portal Network的地址范围是我们在Kubmaster上启动API服务进程时,使用--service-cluster-ip-range=xx命令行参数指定的:


这个IP段可以是任何段,只要不和docker0或者物理网络的子网冲突就可以。选择任意其他网段的原因是,这个网段将不会在物理网络和docker0网络上进行路由。这个Portal Network针对的是每一个Node都有局部的特殊性,实际上它存在的意义是让容器的流量都指向默认网关(也就是docker0网桥)。在继续实验前先登录Node1,看一下在我们定义服务后发生了什么变化。首先检查一下iptables或Netfilter的规则:

第1行是挂在PREROUTING链上的端口重定向规则,所有进入的流量如果满足20.1.244.75:80,则都会被重定向到端口33761。第2行是挂在OUTPUT链上的目标地址NAT,做了和上述第1行规则类似的工作,但针对的是当前主机生成的外出流量。所有主机生成的流量都需要使用这个DNAT规则来处理。简而言之,这两个规则使用了不同的方式做了类似的事情,就是将所有从节点生成的发送给20.1.244.75:80的流量重定向到本地的33761端口。
至此,目标为Service IP地址和端口的任何流量都将被重定向到本地的33761端口。这个端口连到哪里去了呢?这就到了kube-proxy发挥作用的地方了。这个kube-proxy服务给每一个新创建的服务都关联了一个随机的端口号,并且监听那个特定的端口,为服务创建了相关的负载均衡对象。在我们的实验中,随机生成的端口刚好是33761。通过监控Node1上Kubernetes-Service的日志,在创建服务时可以看到下面的记录:

可以知道,所有流量都被导入kube-proxy中了。我们现在需要它完成一些负载均衡工作,创建Replication Controller并观察结果。下面是Replication Controller的配置文件:
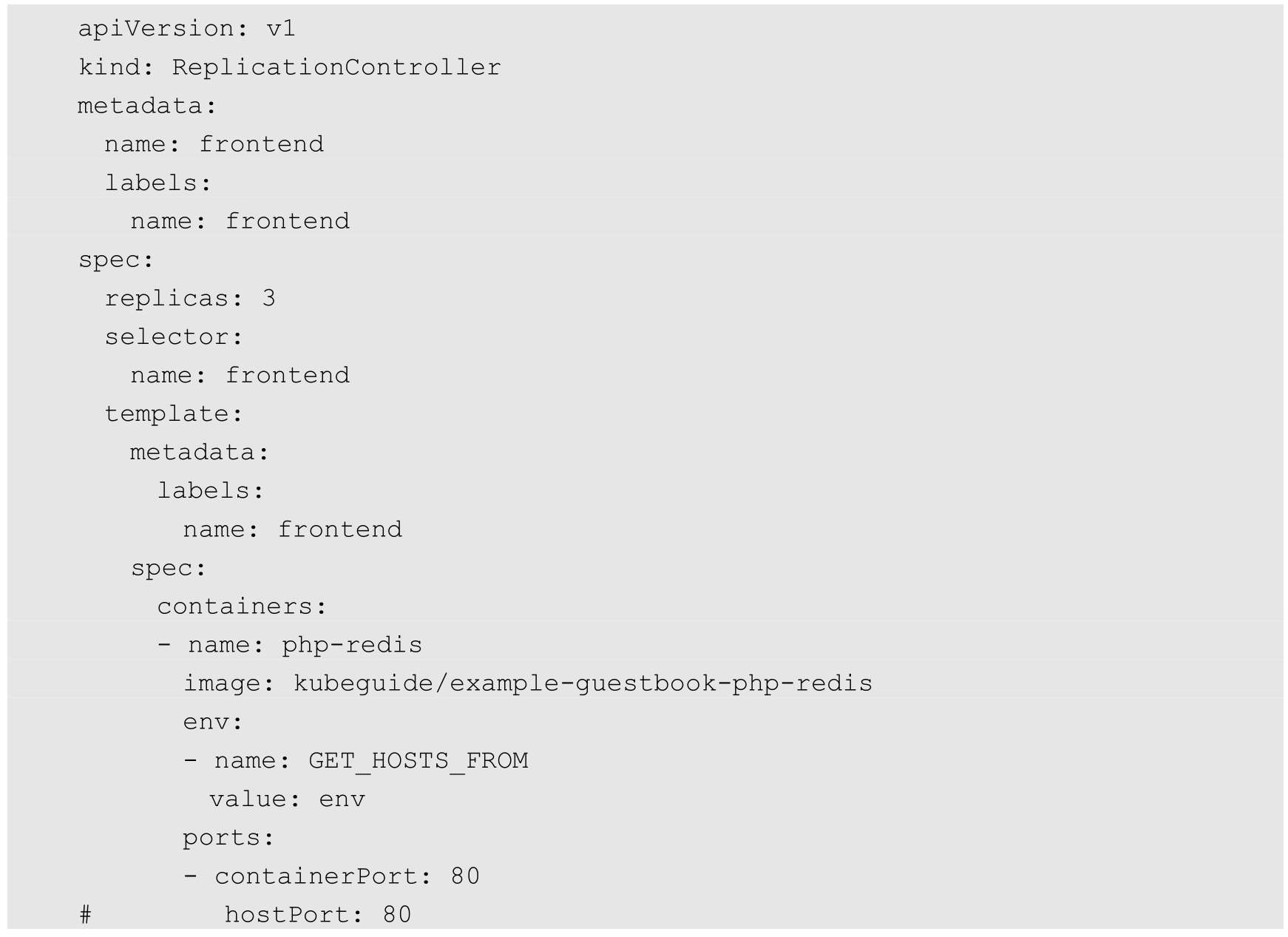
在集群发布以上配置文件后,等待并观察,确保所有Pod都运行起来了:

现在所有的Pod都运行起来了,Service将会把客户端的请求负载分发到包含name=frontend标签的所有Pod上。现在的实验环境如图7.14所示。
Kubernetes的kube-proxy看起来只是一个夹层,但实际上它只是在Node上运行的一个服务。上述重定向规则的结果就是针对目标地址为服务IP的流量,将Kubernetes的kube-proxy变成了一个中间的夹层。
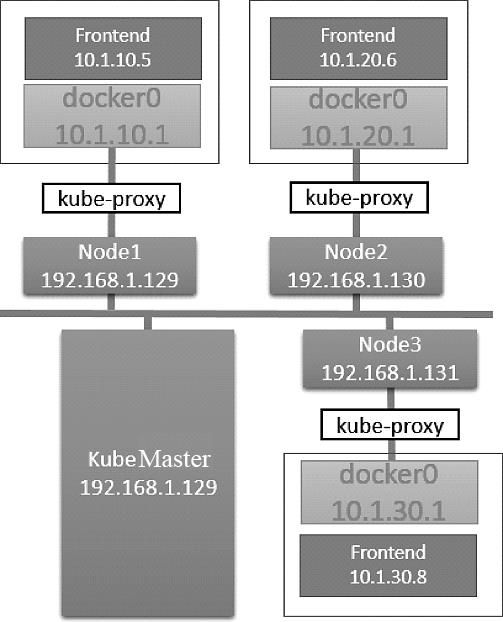
图7.14 现在的实验环境
为了查看具体的重定向动作,我们会使用tcpdump进行网络抓包操作。
首先,安装tcpdump:

安装完成后,登录Node1,运行tcpdump命令:

需要捕获物理服务器以太网接口的数据包,Node1机器上的以太网接口名称是eno16777736。
再打开第1个窗口运行第2个tcpdump程序,不过我们需要一些额外的信息去运行它,即挂接在docker0桥上的虚拟网卡Veth的名称。我们看到只有一个frontend容器在Node1主机上运行,所以可以使用简单的ip addr命令来查看唯一的Veth网络接口:
复制这个接口的名字,在第2个窗口中运行tcpdump命令:

同时运行这两个命令,并且将窗口并排放置,以便同时看到两个窗口的输出:

好了,我们已经在同时捕获两个接口的网络包了。这时再启动第3个窗口,运行docker exec命令连接到我们的frontend容器内部(可以先运行docker ps命令获得这个容器的ID):

进入运行的容器内部:

一旦进入运行的容器内部,我们就可以通过Pod的IP地址来访问服务了。使用curl来尝试访问服务:

在使用curl访问服务时,将在抓包的两个窗口内看到:
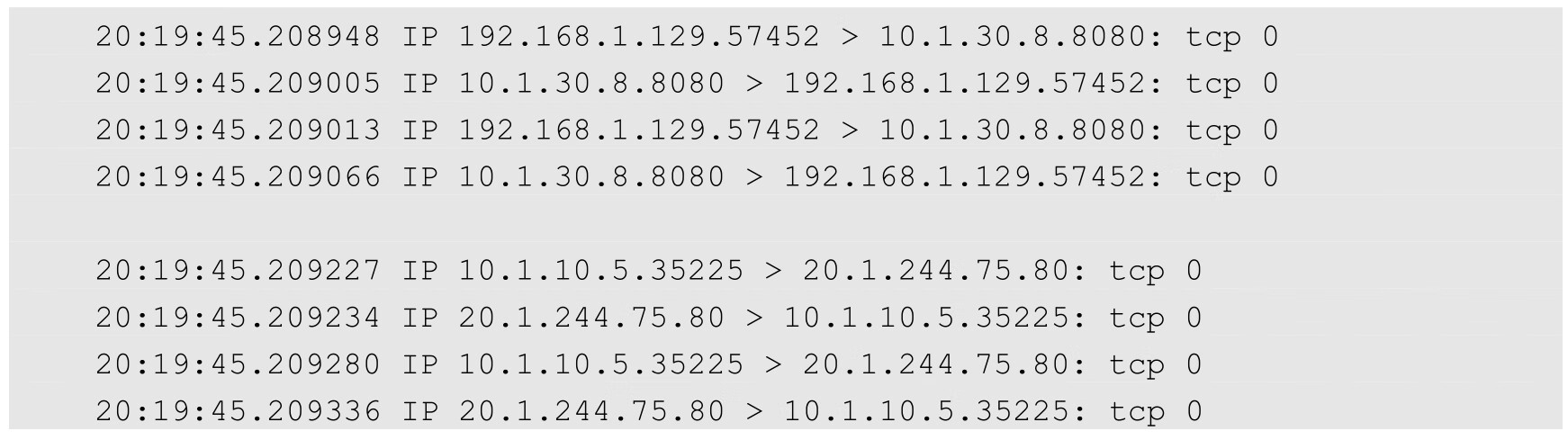
这些信息说明了什么问题呢?让我们在网络图上用实线标出第1个窗口中网络抓包信息的含义(物理网卡上的网络流量),并用虚线标出第2个窗口中网络抓包信息的含义(docker0网桥上的网络流量),如图7.15所示。

图7.15 数据流动情况1
注意,在图7.15中,虚线绕过了Node3的kube-proxy,这么做是因为Node3上的kube-proxy没有参与这次网络交互。换句话说,Node1的kube-proxy服务直接和负载均衡到的Pod进行网络交互。
在查看第2个捕获包的窗口时,我们能够站在容器的视角看这些流量。首先,容器尝试使用20.1.244.75:80打开TCP的Socket连接。同时,我们可以看到从服务地址20.1.244.75返回的数据。从容器的视角来看,整个交互过程都是在服务之间进行的。但是在查看一个捕获包的窗口时(上面的窗口),我们可以看到物理机之间的数据交互,可以看到一个TCP连接从Node1的物理地址(192.168.1.129)发出,直接连接到运行Pod的主机Node3上(192.168.1.131)。总而言之,Kubernetes的kube-proxy作为一个全功能的代理服务器管理了两个独立的TCP连接:一个是从容器到kube-proxy:另一个是从kube-proxy到负载均衡的目标Pod。
如果清理一下捕获的记录,再次运行curl,则还可以看到网络流量被负载均衡转发到另一个节点Node2上了:
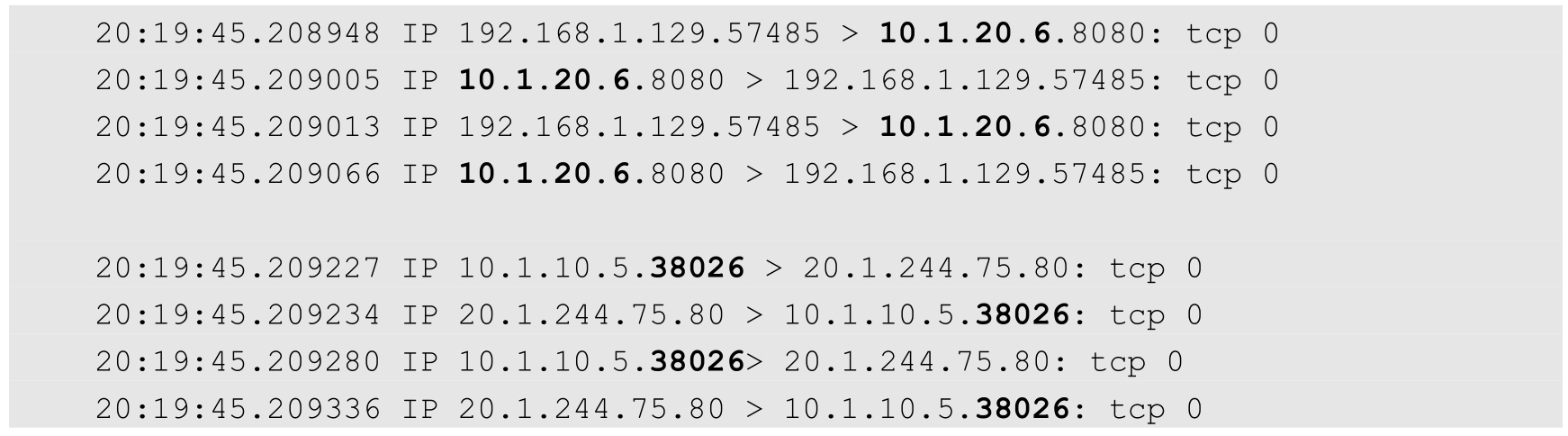
这一次,Kubernetes的Proxy将选择运行在Node2(10.1.20.1)上的Pod作为目标地址。数据流动情况如图7.16所示。
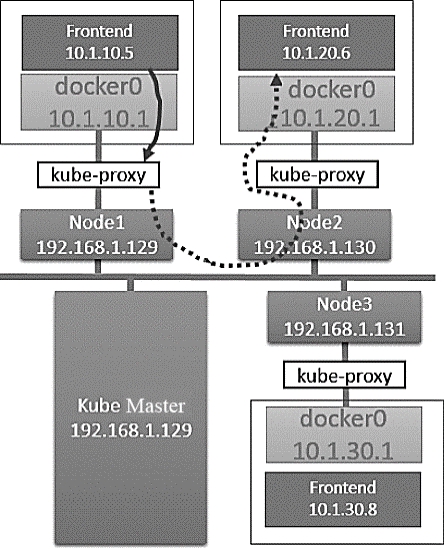
图7.16 数据流动情况2
到这里,你肯定已经知道另一个可能的负载均衡的路由结果了。