标准的Docker支持以下4类网络模式。
◎ host模式:使用--net=host指定。
◎ container模式:使用--net=container:NAME_or_ID指定。
◎ none模式:使用--net=none指定。
◎ bridge模式:使用--net=bridge指定,为默认设置。
在Kubernetes管理模式下通常只会使用bridge模式,所以本节只介绍Docker在bridge模式下是如何支持网络的。
在bridge模式下,Docker Daemon首次启动时会创建一个虚拟网桥,默认的名称是docker0,然后按照RPC1918的模型在私有网络空间中给这个网桥分配一个子网。针对由Docker创建的每一个容器,都会创建一个虚拟以太网设备(Veth设备对),其中一端关联到网桥上,另一端使用Linux的网络命名空间技术映射到容器内的eth0设备,然后在网桥的地址段内给eth0接口分配一个IP地址。
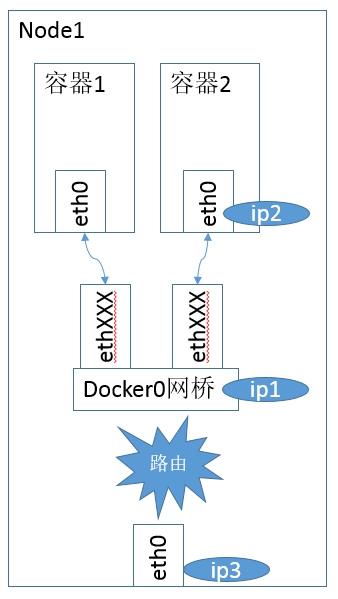
如图7.6所示就是Docker的默认桥接网络模型。
图7.6 Docker的默认桥接网络模型
其中ip1是网桥的IP地址,Docker Daemon会在几个备选地址段里给它选一个地址,通常是以172开头的一个地址,这个地址和主机的IP地址是不重叠的。ip2是Docker在启动容器时在这个地址段选择的一个没有使用的IP地址,它被分配给容器,相应的MAC地址也根据这个IP地址,在02:42:ac:11:00:00和02:42:ac:11:ff:ff的范围内生成,这样做可以确保不会有ARP冲突。
启动后,Docker还将Veth设备对的名称映射到eth0网络接口。ip3就是主机的网卡地址。
在一般情况下,ip1、ip2和ip3是不同的IP段,所以在默认不做任何特殊配置的情况下,在外部是看不到ip1和ip2的。
这样做的结果就是,在同一台机器内的容器之间可以相互通信,不同主机上的容器不能相互通信,实际上它们甚至有可能在相同的网络地址范围内(不同主机上的docker0的地址段可能是一样的)。
为了让它们跨节点相互通信,就必须在主机的地址上分配端口,然后通过这个端口将网络流量路由或代理到目标容器上。这样做显然意味着一定要在容器之间小心谨慎地协调好端口的分配情况,或者使用动态端口的分配技术。在不同应用之间协调好端口分配情况是十分困难的事情,特别是集群水平扩展时。而动态端口分配也会大大增加复杂度,例如:每个应用程序都只能将端口看作一个符号(因为是动态分配的,所以无法提前设置)。而且API Server要在分配完后,将动态端口插入配置的合适位置,服务也必须能相互找到对方等。这些都是Docker的网络模型在跨主机访问时面临的问题。
我们已经知道,Docker网络在bridge模式下Docker Daemon启动时创建docker0网桥,并在网桥使用的网段为容器分配IP。接下来让我们看看实际操作。
在刚刚启动Docker Daemon并且还没有启动任何容器时,网络协议栈的配置如下:
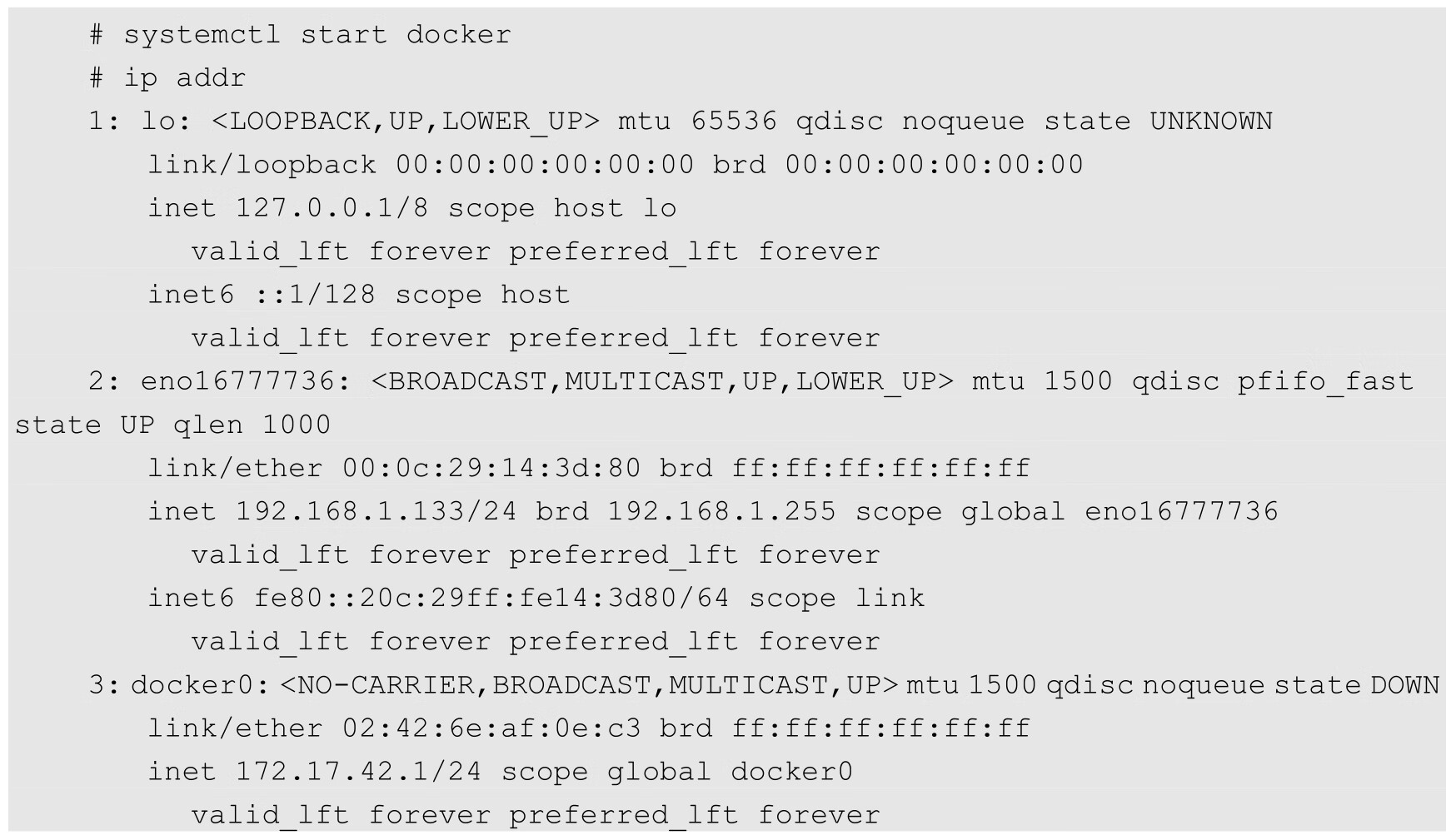
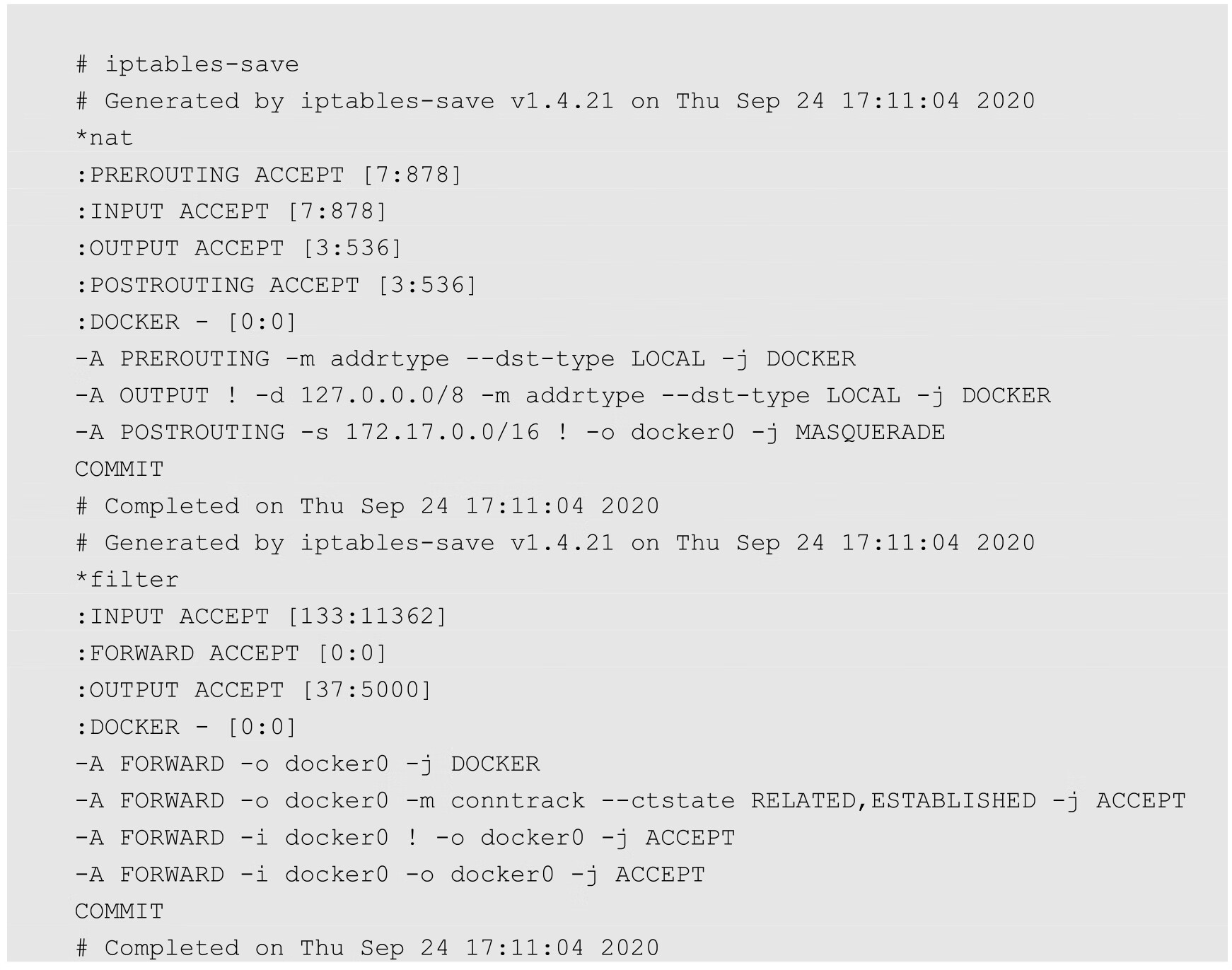
可以看到,Docker创建了docker0网桥,并添加了iptables规则。docker0网桥和iptables规则都处于root命名空间中。通过解读这些规则,我们发现,在还没有启动任何容器时,如果启动了Docker Daemon,那么它已经做好了通信准备。对这些规则的说明如下。
(1)在NAT表中有3条记录,在前两条匹配生效后,都会继续执行DOCKER链,而此时DOCKER链为空,所以前两条只是做了一个框架,并没有实际效果。
(2)NAT表第3条的含义是,若本地发出的数据包不是发往docker0的,而是发往主机之外的设备的,则都需要进行动态地址修改(MASQUERADE),将源地址从容器的地址(172段)修改为宿主机网卡的IP地址,之后就可以发送给外面的网络了。
(3)在FILTER表中,第1条也是一个框架,因为后续的DOCKER链是空的。
(4)在FILTER表中,第3条的含义是,docker0发出的包,如果需要转发到非docker0本地IP地址的设备,则是允许的。这样,docker0设备的包就可以根据路由规则中转到宿主机的网卡设备,从而访问外面的网络了。
(5)在FILTER表中,第4条的含义是,docker0的包还可以被中转给docker0本身,即连接在docker0网桥上的不同容器之间的通信也是允许的。
(6)在FILTER表中,第2条的含义是,如果接收到的数据包属于以前已经建立好的连接,那么允许直接通过。这样,接收到的数据包自然又走回docker0,并中转到相应的容器。
除了这些Netfilter的设置,Linux的ip_forward功能也被Docker Daemon打开了:

另外,我们可以看到刚刚启动Docker后的Route表,它和启动前没有什么不同:

刚才查看了Docker服务启动后的网络配置。现在启动一个Registry容器(不使用任何端口镜像参数),看一下网络堆栈部分相关的变化:
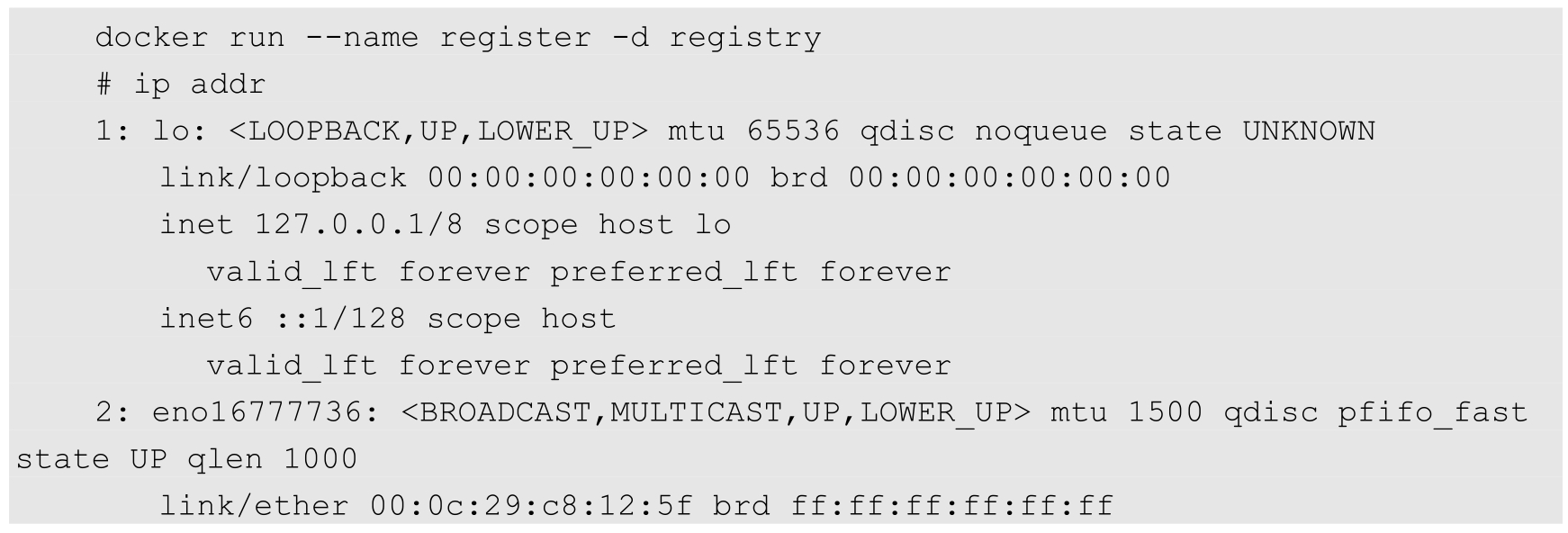


可以看到如下情况。
(1)宿主机器上的Netfilter和路由表都没有变化,说明在不进行端口映射时,Docker的默认网络是没有特殊处理的。相关的NAT和FILTER这两个Netfilter链还是空的。
(2)宿主机上的Veth设备对已经建立,并连接到容器内。
我们再次进入刚刚启动的容器内,看看网络栈是什么情况。容器内部的IP地址和路由如下:
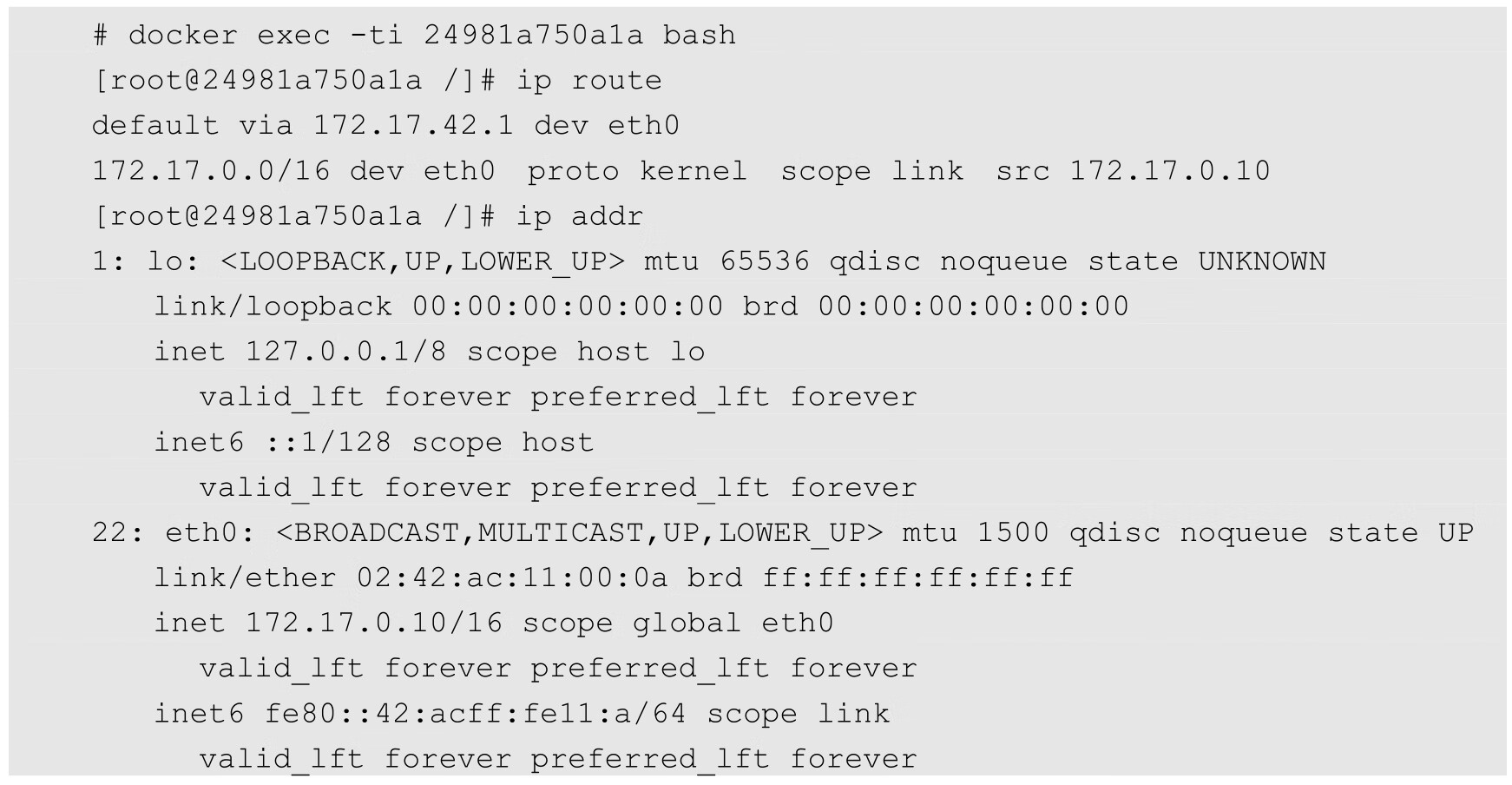
可以看到,默认停止的回环设备lo已被启动,外面宿主机连接进来的Veth设备也被命名成了eth0,并且已经配置了地址172.17.0.10。
路由信息表包含一条到docker0的子网路由和一条到docker0的默认路由。
下面用带端口映射的命令启动registry:

在启动后查看iptables的变化:
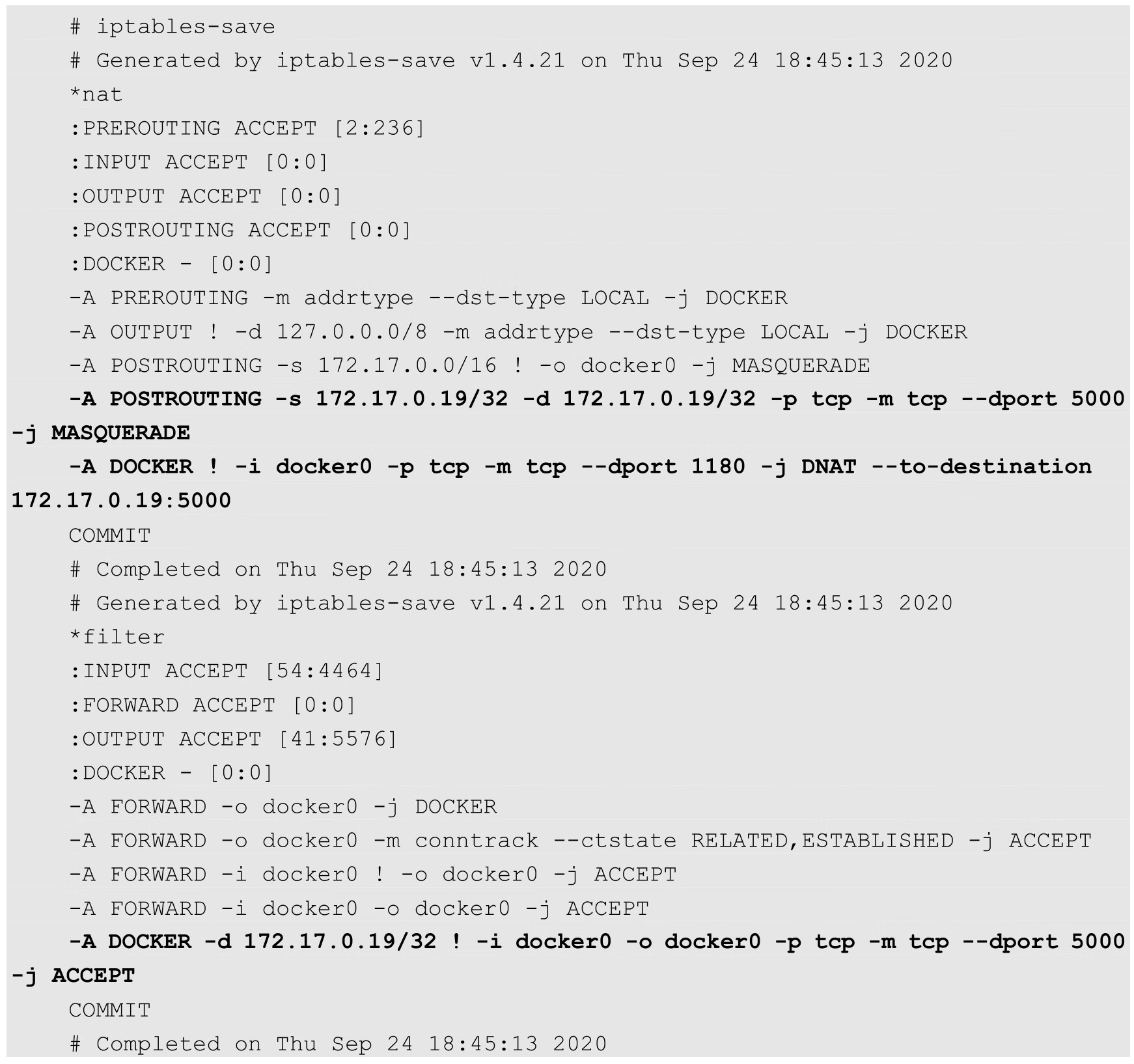
从新增的规则可以看出,Docker服务在NAT和FILTER两个表内添加的两个DOCKER子链都是给端口映射用的。在本例中,我们需要把外面宿主机的 1180 端口映射到容器的5000端口。通过前面的分析,我们知道,无论是宿主机接收到的还是宿主机本地协议栈发出的,目标地址是本地IP地址的包都会经过NAT表中的DOCKER子链。Docker为每一个端口映射都在这个链上增加了到实际容器目标地址和目标端口的转换。
经过这个DNAT的规则修改后的IP包,会重新经过路由模块的判断进行转发。由于目标地址和端口已经是容器的地址和端口,所以数据自然被转发到docker0上,从而被转发到对应的容器内部。
当然在转发时,也需要在DOCKER子链中添加一条规则,如果目标端口和地址是指定容器的数据,则允许通过。
在Docker按照端口映射的方式启动容器时,主要的不同就是上述iptables部分。而容器内部的路由和网络设备,都和不做端口映射时一样,没有任何变化。
我们从Docker对Linux网络协议栈的操作可以看到,Docker一开始没有考虑到多主机互联的网络解决方案。
Docker一直以来的理念都是“简单为美”,几乎所有尝试Docker的人都被它用法简单、功能强大的特性所吸引,这也是Docker迅速走红的一个原因。
我们都知道,虚拟化技术中最为复杂的部分就是虚拟化网络技术,即使是单纯的物理网络部分,也是一个门槛很高的技能领域,通常只被少数网络工程师所掌握,所以掌握结合了物理网络的虚拟网络技术很难。在Docker之前,所有接触过OpenStack的人都对其网络问题讳莫如深,Docker明智地避开这个“雷区”,让其他专业人员去用现有的虚拟化网络技术解决Docker主机的互联问题,以免让用户觉得Docker太难,从而放弃学习和使用Docker。
Docker成名以后,重新开始重视网络解决方案,收购了一家Docker网络解决方案公司—Socketplane,原因在于这家公司的产品广受好评,但有趣的是,Socketplane的方案就是以Open vSwitch为核心的,其还为Open vSwitch提供了Docker镜像,以方便部署程序。之后,Docker开启了一个宏伟的虚拟化网络解决方案—Libnetwork,如图7.7所示是其概念图。这个概念图没有了IP,也没有了路由,已经颠覆了我们的网络常识,对于不怎么懂网络的大多数人来说,它的确很有诱惑力。它未来是否会对虚拟化网络的模型产生深远冲击,我们还不知道,但它仅仅是Docker官方当前的一次尝试。
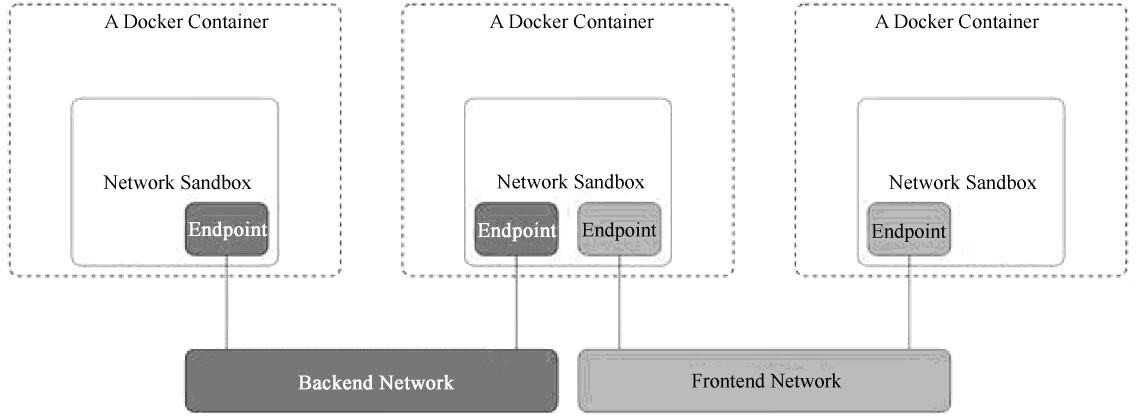
图7.7 Libnetwork概念图
针对目前Docker的网络实现,Docker使用的Libnetwork组件只是将Docker平台中的网络子系统模块化为一个独立库的简单尝试,离成熟和完善还有一段距离。