1.CRD升级的影响分析
在升级CRD的过程中,对于集群内服务之间的调用、网关到服务之间的调用均没有产生断连影响。
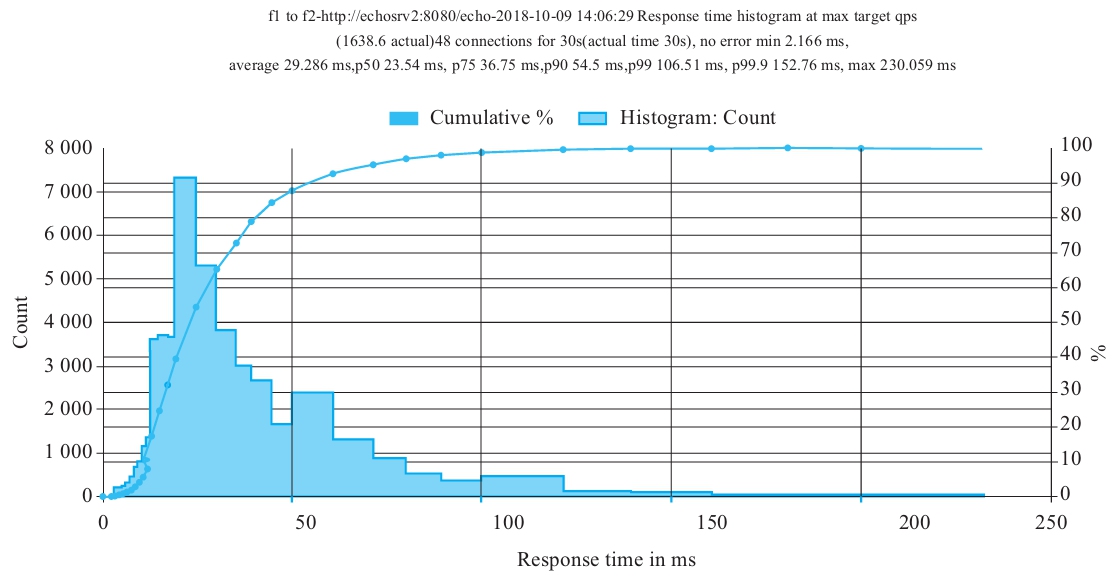
如图9-3所示为集群内服务间的调用在CRD升级过程中的执行情况,执行结果中显示no error。
图9-3 集群内服务间的调用在CRD升级过程中的执行情况
图9-4为在CRD升级过程中,入口网关ingressgateway到网格内的服务间的调用情况,执行结果中显示no error。
2.控制平面升级
在没有高可用(HA)的情况下,无论是集群内服务之间的调用,还是通过网关到集群内服务之间的调用,QPS均会下降,也会出现断连情况。测试中发现集群内服务之间的调用失败率为5%左右,网关到集群内服务之间的调用会更糟糕(因为ingressgateway可能会重新创建),如图9-5所示。
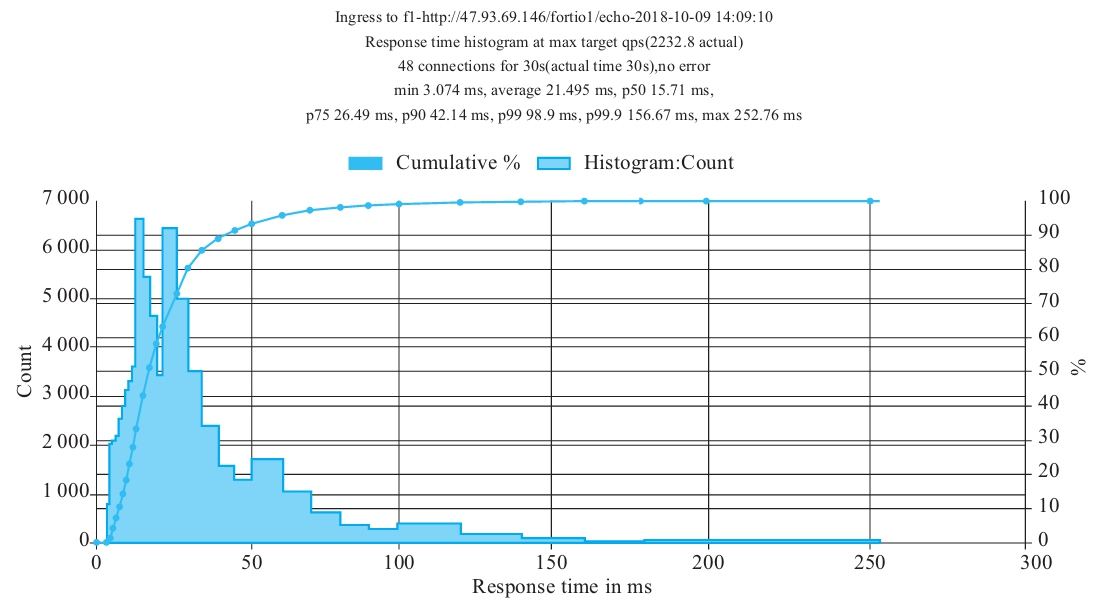
图9-4 在CRD升级过程中,入口网关ingressgateway到网格内的服务间的执行情况
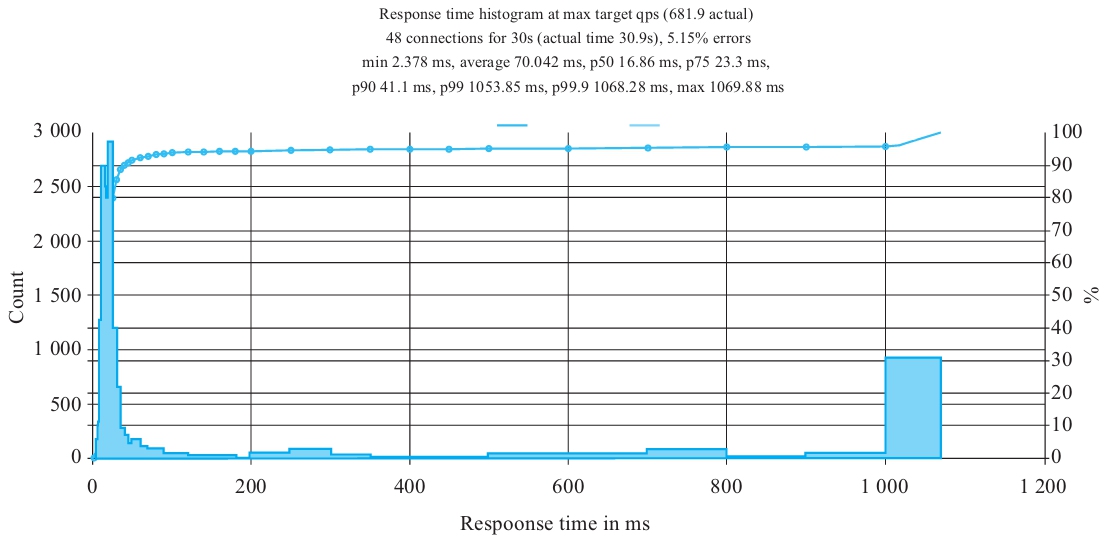
图9-5 网关到集群内服务之间的调用情况
在启用高可用HA(例如pilot的replicas为2)的情况下,可以通过istio-pilot/istio-policy/istio-telemetry的HPA设置:minReplicas:2。
此时,在多次变更版本(升级、回滚)的情况下,测试结果显示:
服务之间的调用QPS基本不变,维持在1500~2000左右,失败率基本为0,如图9-6所示。
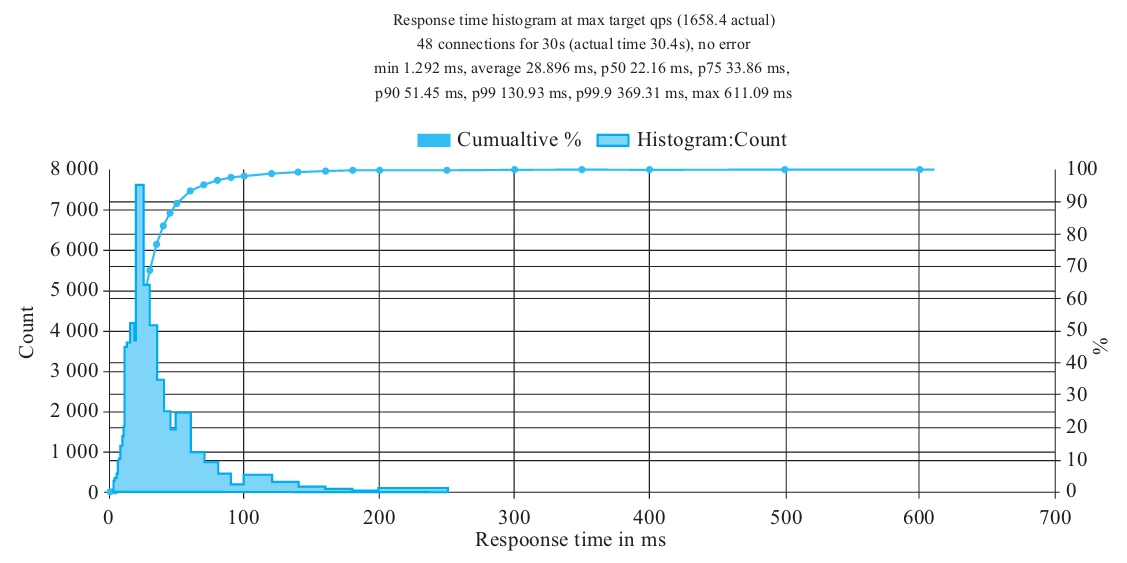
图9-6 服务之间的调用情况
而入口网关ingressgateway到服务间的调用QPS基本不变,失败率基本为<1%。
由此可见,启用高可用HA之后,控制平面的升级对应用的影响会大大缩减。
3.数据平面Sidecar升级
为保证你的服务在Sidecar升级的过程中不中断业务流量,首先确保你的服务实例数大于等于2,升级策略为滚动升级(rollingUpdate)。相关滚动升级策略如下所示:
spec:
replicas: 2
selector:
matchLabels:
app: productpage
version: v1
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
其中,参数说明如下:
·服务实例数:deployment.spec.replicas>=2
·升级策略:deployment.spec.strategy.type==RollingUpdate
·滚动升级最小存活实例数:deployment.spec.replicas-deployment.spec.strategy.max Unavailable>0
在滚动升级过程中,首先会移除旧的服务实例pod的endpoint,并将实例pod的状态置为Terminating,这时Kubernetes会发送SIGTERM信号给pod实例,并等待优雅关闭时间后,将pod强制杀掉。可以利用这段时间,处理未完成的请求。具体的优雅关闭时间参数为deployment.spec.template.spec.terminationGracePeriodSeconds,默认值为30s,可根据业务诉求适当调整。
另外,通过添加readiness探针,可以保证新实例的pod在真正准备就绪时,才开始接管业务流量。这就避免了在新实例pod未启动时,接管业务流量造成的访问中断问题。
而另外一个参数minReadySeconds描述了服务就绪时间,即用于标识pod的ready时间至少保持多久才会认为服务是运行中。具体的服务就绪时间参数为deployment.spec.minReadySeconds,可根据你业务的实际情况确定。