本章主要内容
通常程序会被编写为一个顺序执行并完成一个独立任务的代码。如果没有特别的需求,最好总是这样写代码,因为这种类型的程序通常很容易写,也很容易维护。不过也有一些情况下,并行执行多个任务会有更大的好处。一个例子是,Web服务需要在各自独立的套接字(socket)上同时接收多个数据请求。每个套接字请求都是独立的,可以完全独立于其他套接字进行处理。具有并行执行多个请求的能力可以显著提高这类系统的性能。考虑到这一点,Go语言的语法和运行时直接内置了对并发的支持。
Go语言里的并发指的是能让某个函数独立于其他函数运行的能力。当一个函数创建为goroutine时,Go会将其视为一个独立的工作单元。这个单元会被调度到可用的逻辑处理器上执行。Go语言运行时的调度器是一个复杂的软件,能管理被创建的所有goroutine并为其分配执行时间。这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。调度器在任何给定的时间,都会全面控制哪个goroutine要在哪个逻辑处理器上运行。
Go语言的并发同步模型来自一个叫作通信顺序进程(Communicating Sequential Processes,CSP)的范型(paradigm)。CSP是一种消息传递模型,通过在goroutine之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。用于在goroutine之间同步和传递数据的关键数据类型叫作通道(channel)。对于没有使用过通道写并发程序的程序员来说,通道会让他们感觉神奇而兴奋。希望读者使用后也能有这种感觉。使用通道可以使编写并发程序更容易,也能够让并发程序出错更少。
让我们先来学习一下抽象程度较高的概念:什么是操作系统的线程(thread)和进程(process)。这会有助于后面理解Go语言运行时调度器如何利用操作系统来并发运行goroutine。当运行一个应用程序(如一个IDE或者编辑器)的时候,操作系统会为这个应用程序启动一个进程。可以将这个进程看作一个包含了应用程序在运行中需要用到和维护的各种资源的容器。
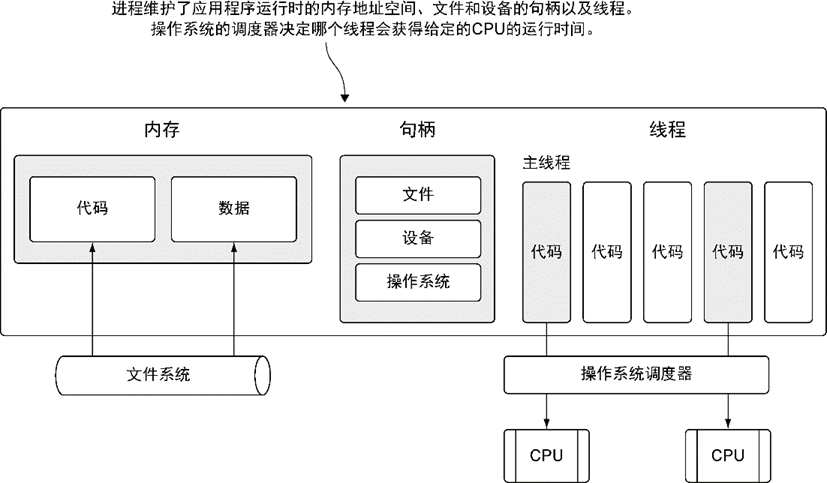
图6-1展示了一个包含所有可能分配的常用资源的进程。这些资源包括但不限于内存地址空间、文件和设备的句柄以及线程。一个线程是一个执行空间,这个空间会被操作系统调度来运行函数中所写的代码。每个进程至少包含一个线程,每个进程的初始线程被称作主线程。因为执行这个线程的空间是应用程序的本身的空间,所以当主线程终止时,应用程序也会终止。操作系统将线程调度到某个处理器上运行,这个处理器并不一定是进程所在的处理器。不同操作系统使用的线程调度算法一般都不一样,但是这种不同会被操作系统屏蔽,并不会展示给程序员。
图6-1 一个运行的应用程序的进程和线程的简要描绘
操作系统会在物理处理器上调度线程来运行,而Go语言的运行时会在逻辑处理器上调度goroutine来运行。每个逻辑处理器都分别绑定到单个操作系统线程。在1.5版本 上,Go语言的运行时默认会为每个可用的物理处理器分配一个逻辑处理器。在1.5版本之前的版本中,默认给整个应用程序只分配一个逻辑处理器。这些逻辑处理器会用于执行所有被创建的goroutine。即便只有一个逻辑处理器,Go也可以以神奇的效率和性能,并发调度无数个goroutine。
上,Go语言的运行时默认会为每个可用的物理处理器分配一个逻辑处理器。在1.5版本之前的版本中,默认给整个应用程序只分配一个逻辑处理器。这些逻辑处理器会用于执行所有被创建的goroutine。即便只有一个逻辑处理器,Go也可以以神奇的效率和性能,并发调度无数个goroutine。
在图6-2中,可以看到操作系统线程、逻辑处理器和本地运行队列之间的关系。如果创建一个goroutine并准备运行,这个goroutine就会被放到调度器的全局运行队列中。之后,调度器就将这些队列中的goroutine分配给一个逻辑处理器,并放到这个逻辑处理器对应的本地运行队列中。本地运行队列中的goroutine会一直等待直到自己被分配的逻辑处理器执行。

图6-2 Go调度器如何管理goroutine
有时,正在运行的goroutine需要执行一个阻塞的系统调用,如打开一个文件。当这类调用发生时,线程和goroutine会从逻辑处理器上分离,该线程会继续阻塞,等待系统调用的返回。与此同时,这个逻辑处理器就失去了用来运行的线程。所以,调度器会创建一个新线程,并将其绑定到该逻辑处理器上。之后,调度器会从本地运行队列里选择另一个goroutine来运行。一旦被阻塞的系统调用执行完成并返回,对应的goroutine会放回到本地运行队列,而之前的线程会保存好,以便之后可以继续使用。
如果一个goroutine需要做一个网络I/O调用,流程上会有些不一样。在这种情况下,goroutine会和逻辑处理器分离,并移到集成了网络轮询器的运行时。一旦该轮询器指示某个网络读或者写操作已经就绪,对应的goroutine就会重新分配到逻辑处理器上来完成操作。调度器对可以创建的逻辑处理器的数量没有限制,但语言运行时默认限制每个程序最多创建10 000个线程。这个限制值可以通过调用runtime/debug包的SetMaxThreads方法来更改。如果程序试图使用更多的线程,就会崩溃。
并发(concurrency)不是并行(parallelism)。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情”的哲学,也是指导Go语言设计的哲学。
如果希望让goroutine并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将goroutine平等分配到每个逻辑处理器上。这会让goroutine在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕Go语言运行时使用多个线程,goroutine依然会在同一个物理处理器上并发运行,达不到并行的效果。
图6-3展示了在一个逻辑处理器上并发运行goroutine和在两个逻辑处理器上并行运行两个并发的goroutine之间的区别。调度器包含一些聪明的算法,这些算法会随着Go语言的发布被更新和改进,所以不推荐盲目修改语言运行时对逻辑处理器的默认设置。如果真的认为修改逻辑处理器的数量可以改进性能,也可以对语言运行时的参数进行细微调整。后面会介绍如何做这种修改。
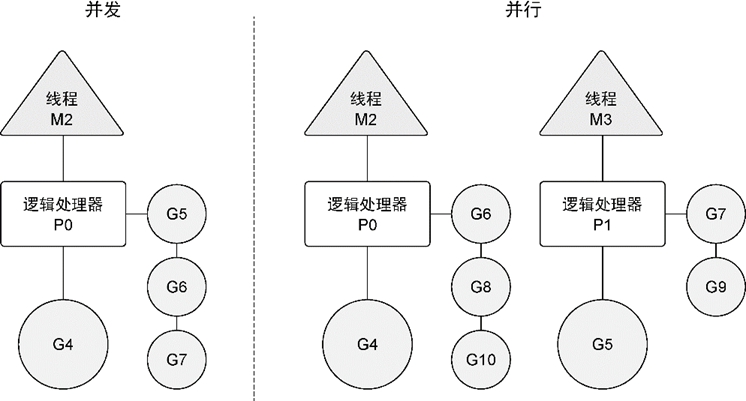
图6-3 并发和并行的区别
让我们再深入了解一下调度器的行为,以及调度器是如何创建goroutine并管理其寿命的。我们会先通过在一个逻辑处理器上运行的例子来讲解,再来讨论如何让goroutine并行运行。代码清单6-1所示的程序会创建两个goroutine,以并发的形式分别显示大写和小写的英文字母。
代码清单6-1 listing01.go
01 // 这个示例程序展示如何创建goroutine
02 // 以及调度器的行为
03 package main
04
05 import (
06 "fmt"
07 "runtime"
08 "sync"
09 )
10
11 // main是所有Go程序的入口
12 func main() {
13 // 分配一个逻辑处理器给调度器使用
14 runtime.GOMAXPROCS(1)
15
16 // wg用来等待程序完成
17 // 计数加2,表示要等待两个goroutine
18 var wg sync.WaitGroup
19 wg.Add(2)
20
21 fmt.Println("StartGoroutines")
22
23 // 声明一个匿名函数,并创建一个goroutine
24 go func() {
25 // 在函数退出时调用Done来通知main函数工作已经完成
26 defer wg.Done()
27
28 // 显示字母表3次
29 for count := 0; count < 3; count++ {
30 for char := 'a'; char < 'a'+26; char++ {
31 fmt.Printf("%c ", char)
32 }
33 }
34 }()
35
36 // 声明一个匿名函数,并创建一个goroutine
37 go func() {
38 // 在函数退出时调用Done来通知main函数工作已经完成
39 defer wg.Done()
40
41 // 显示字母表3次
42 for count := 0; count < 3; count++ {
43 for char := 'A'; char < 'A'+26; char++ {
44 fmt.Printf("%c ", char)
45 }
46 }
47 }()
48
49 // 等待goroutine结束
50 fmt.Println("Waiting To Finish")
51 wg.Wait()
52
53 fmt.Println("\nTerminating Program")
54 }在代码清单6-1的第14行,调用了runtime包的GOMAXPROCS函数。这个函数允许程序更改调度器可以使用的逻辑处理器的数量。如果不想在代码里做这个调用,也可以通过修改和这个函数名字一样的环境变量的值来更改逻辑处理器的数量。给这个函数传入1,是通知调度器只能为该程序使用一个逻辑处理器。
在第24行和第37行,我们声明了两个匿名函数,用来显示英文字母表。第24行的函数显示小写字母表,而第37行的函数显示大写字母表。这两个函数分别通过关键字go创建goroutine来执行。根据代码清单6-2中给出的输出可以看到,每个goroutine执行的代码在一个逻辑处理器上并发运行的效果。
代码清单6-2 listing01.go的输出
StartGoroutines
Waiting To Finish
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M
N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m
n o p q r s t u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z
Terminating Program第一个goroutine完成所有显示需要花时间太短了,以至于在调度器切换到第二个goroutine之前,就完成了所有任务。这也是为什么会看到先输出了所有的大写字母,之后才输出小写字母。我们创建的两个goroutine一个接一个地并发运行,独立完成显示字母表的任务。
如代码清单6-3所示,一旦两个匿名函数创建goroutine来执行,main中的代码会继续运行。这意味着main函数会在goroutine完成工作前返回。如果真的返回了,程序就会在goroutine有机会运行前终止。因此,在第51行,main函数通过WaitGroup,等待两个goroutine完成它们的工作。
代码清单6-3 listing01.go:第17行到第19行,第23行到第26行,第49行到第51行
16 // wg用来等待程序完成
17 // 计数加2,表示要等待两个goroutine
18 var wg sync.WaitGroup
19 wg.Add(2)
23 // 声明一个匿名函数,并创建一个goroutine
24 go func() {
25 // 在函数退出时调用Done来通知main函数工作已经完成
26 defer wg.Done()
49 // 等待goroutine结束
50 fmt.Println("Waiting To Finish")
51 wg.Wait()WaitGroup是一个计数信号量,可以用来记录并维护运行的goroutine。如果WaitGroup的值大于0,Wait方法就会阻塞。在第18行,创建了一个WaitGroup类型的变量,之后在第19行,将这个WaitGroup的值设置为2,表示有两个正在运行的goroutine。为了减小WaitGroup的值并最终释放main函数,要在第26和39行,使用defer声明在函数退出时调用Done方法。
关键字defer会修改函数调用时机,在正在执行的函数返回时才真正调用defer声明的函数。对这里的示例程序来说,我们使用关键字defer保证,每个goroutine一旦完成其工作就调用Done方法。
基于调度器的内部算法,一个正运行的goroutine在工作结束前,可以被停止并重新调度。调度器这样做的目的是防止某个goroutine长时间占用逻辑处理器。当goroutine占用时间过长时,调度器会停止当前正运行的goroutine,并给其他可运行的goroutine运行的机会。
图6-4从逻辑处理器的角度展示了这一场景。在第1步,调度器开始运行goroutine A,而goroutine B在运行队列里等待调度。之后,在第2步,调度器交换了goroutine A和goroutine B。由于goroutine A并没有完成工作,因此被放回到运行队列。之后,在第3步,goroutine B完成了它的工作并被系统销毁。这也让goroutine A继续之前的工作。
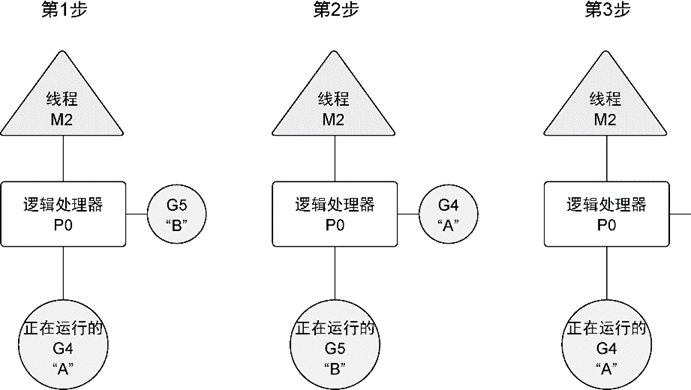
图6-4 goroutine在逻辑处理器的线程上进行交换
可以通过创建一个需要长时间才能完成其工作的goroutine来看到这个行为,如代码清单6-4所示。
代码清单6-4 listing04.go
01 // 这个示例程序展示goroutine调度器是如何在单个线程上
02 // 切分时间片的
03 package main
04
05 import (
06 "fmt"
07 "runtime"
08 "sync"
09 )
10
11 // wg用来等待程序完成
12 var wg sync.WaitGroup
13
14 // main是所有Go程序的入口
15 func main() {
16 // 分配一个逻辑处理器给调度器使用
17 runtime.GOMAXPROCS(1)
18
19 // 计数加2,表示要等待两个goroutine
20 wg.Add(2)
21
22 // 创建两个goroutine
23 fmt.Println("CreateGoroutines")
24 go printPrime("A")
25 go printPrime("B")
26
27 // 等待goroutine结束
28 fmt.Println("Waiting To Finish")
29 wg.Wait()
30
31 fmt.Println("Terminating Program")
32 }
33
34 // printPrime 显示5000以内的素数值
35 func printPrime(prefix string) {
36 // 在函数退出时调用Done来通知main函数工作已经完成
37 defer wg.Done()
38
39 next:
40 for outer := 2; outer < 5000; outer++ {
41 for inner := 2; inner < outer; inner++ {
42 if outer%inner == 0 {
43 continue next
44 }
45 }
46 fmt.Printf("%s:%d\n", prefix, outer)
47 }
48 fmt.Println("Completed", prefix)
49 }代码清单6-4中的程序创建了两个goroutine,分别打印1~5000内的素数。查找并显示素数会消耗不少时间,这会让调度器有机会在第一个goroutine找到所有素数之前,切换该goroutine的时间片。
在第12行中,程序启动的时候,声明了一个WaitGroup变量,并在第20行将其值设置为2。之后在第24行和第25行,在关键字go后面指定printPrime函数并创建了两个goroutine来执行。第一个goroutine使用前缀A,第二个goroutine使用前缀B。和其他函数调用一样,创建为goroutine的函数调用时可以传入参数。不过goroutine终止时无法获取函数的返回值。查看代码清单6-5中给出的输出时,会看到调度器在切换第一个goroutine。
代码清单6-5 listing04.go的输出
CreateGoroutines
Waiting To Finish
B:2
B:3
...
B:4583
B:4591
A:3 ** 切换goroutine
A:5
...
A:4561
A:4567
B:4603 ** 切换goroutine
B:4621
...
Completed B
A:4457 ** 切换goroutine
A:4463
...
A:4993
A:4999
Completed A
Terminating Programgoroutine B先显示素数。一旦goroutine B打印到素数4591,调度器就会将正运行的goroutine切换为goroutine A。之后goroutine A在线程上执行了一段时间,再次切换为goroutine B。这次goroutine B完成了所有的工作。一旦goroutine B返回,就会看到线程再次切换到goroutine A并完成所有的工作。每次运行这个程序,调度器切换的时间点都会稍微有些不同。
代码清单6-1和代码清单6-4中的示例程序展示了调度器如何在一个逻辑处理器上并发运行多个goroutine。像之前提到的,Go标准库的runtime包里有一个名为GOMAXPROCS的函数,通过它可以指定调度器可用的逻辑处理器的数量。用这个函数,可以给每个可用的物理处理器在运行的时候分配一个逻辑处理器。代码清单6-6展示了这种改动,让goroutine并行运行。
代码清单6-6 如何修改逻辑处理器的数量
import "runtime"
// 给每个可用的核心分配一个逻辑处理器
runtime.GOMAXPROCS(runtime.NumCPU())包runtime提供了修改Go语言运行时配置参数的能力。在代码清单6-6里,我们使用两个runtime包的函数来修改调度器使用的逻辑处理器的数量。函数NumCPU返回可以使用的物理处理器的数量。因此,调用GOMAXPROCS函数就为每个可用的物理处理器创建一个逻辑处理器。需要强调的是,使用多个逻辑处理器并不意味着性能更好。在修改任何语言运行时配置参数的时候,都需要配合基准测试来评估程序的运行效果。
如果给调度器分配多个逻辑处理器,我们会看到之前的示例程序的输出行为会有些不同。让我们把逻辑处理器的数量改为2,并再次运行第一个打印英文字母表的示例程序,如代码清单6-7所示。
代码清单6-7 listing07.go
01 // 这个示例程序展示如何创建goroutine
02 // 以及goroutine调度器的行为
03 package main
04
05 import (
06 "fmt"
07 "runtime"
08 "sync"
09 )
10
11 // main是所有Go程序的入口
12 func main() {
13 // 分配2个逻辑处理器给调度器使用
14 runtime.GOMAXPROCS(2)
15
16 // wg用来等待程序完成
17 // 计数加2,表示要等待两个goroutine
18 var wg sync.WaitGroup
19 wg.Add(2)
20
21 fmt.Println("StartGoroutines")
22
23 // 声明一个匿名函数,并创建一个goroutine
24 go func() {
25 // 在函数退出时调用Done来通知main函数工作已经完成
26 defer wg.Done()
27
28 // 显示字母表3次
29 for count := 0; count < 3; count++ {
30 for char := 'a'; char < 'a'+26; char++ {
31 fmt.Printf("%c ", char)
32 }
33 }
34 }()
35
36 // 声明一个匿名函数,并创建一个goroutine
37 go func() {
38 // 在函数退出时调用Done来通知main函数工作已经完成
39 defer wg.Done()
40
41 // 显示字母表3次
42 for count := 0; count < 3; count++ {
43 for char := 'A'; char < 'A'+26; char++ {
44 fmt.Printf("%c ", char)
45 }
46 }
47 }()
48
49 // 等待goroutine结束
50 fmt.Println("Waiting To Finish")
51 wg.Wait()
52
53 fmt.Println("\nTerminating Program")
54 }代码清单6-7中给出的例子在第14行中通过调用GOMAXPROCS函数创建了两个逻辑处理器。这会让goroutine并行运行,输出结果如代码清单6-8所示。
代码清单6-8 listing07.go的输出
CreateGoroutines
Waiting To Finish
A B C a D E b F c G d H e I f J g K h L i M j N k O l P m Q n R o S p T
q U r V s W t X u Y v Z w A x B y C z D a E b F c G d H e I f J g K h L
i M j N k O l P m Q n R o S p T q U r V s W t X u Y v Z w A x B y C z D
a E b F c G d H e I f J g K h L i M j N k O l P m Q n R o S p T q U r V
s W t X u Y v Z w x y z
Terminating Program如果仔细查看代码清单6-8中的输出,会看到goroutine是并行运行的。两个goroutine几乎是同时开始运行的,大小写字母是混合在一起显示的。这是在一台8核的电脑上运行程序的输出,所以每个goroutine独自运行在自己的核上。记住,只有在有多个逻辑处理器且可以同时让每个goroutine运行在一个可用的物理处理器上的时候,goroutine才会并行运行。
现在知道了如何创建goroutine,并了解这背后发生的事情了。下面需要了解一下写并发程序时的潜在危险,以及需要注意的事情。
如果两个或者多个goroutine在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于相互竞争的状态,这种情况被称作竞争状态(race candition)。竞争状态的存在是让并发程序变得复杂的地方,十分容易引起潜在问题。对一个共享资源的读和写操作必须是原子化的,换句话说,同一时刻只能有一个goroutine对共享资源进行读和写操作。代码清单6-9中给出的是包含竞争状态的示例程序。
代码清单6-9 listing09.go
01 // 这个示例程序展示如何在程序里造成竞争状态
02 // 实际上不希望出现这种情况
03 package main
04
05 import (
06 "fmt"
07 "runtime"
08 "sync"
09 )
10
11 var (
12 // counter是所有goroutine都要增加其值的变量
13 counter int
14
15 // wg用来等待程序结束
16 wg sync.WaitGroup
17 )
18
19 // main是所有Go程序的入口
20 func main() {
21 // 计数加2,表示要等待两个goroutine
22 wg.Add(2)
23
24 // 创建两个goroutine
25 go incCounter(1)
26 go incCounter(2)
27
28 // 等待goroutine结束
29 wg.Wait()
30 fmt.Println("Final Counter:", counter)
31 }
32
33 // incCounter增加包里counter变量的值
34 func incCounter(id int) {
35 // 在函数退出时调用Done来通知main函数工作已经完成
36 defer wg.Done()
37
38 for count := 0; count < 2; count++ {
39 // 捕获counter的值
40 value := counter
41
42 // 当前goroutine从线程退出,并放回到队列
43 runtime.Gosched()
44
45 // 增加本地value变量的值
46 value++
47
48 // 将该值保存回counter
49 counter = value
50 }
51 }对应的输出如代码清单6-10所示。
代码清单6-10 listing09.go的输出
Final Counter: 2变量counter会进行4次读和写操作,每个goroutine执行两次。但是,程序终止时,counter变量的值为2。图6-5提供了为什么会这样的线索。
每个goroutine都会覆盖另一个goroutine的工作。这种覆盖发生在goroutine切换的时候。每个goroutine创造了一个counter变量的副本,之后就切换到另一个goroutine。当这个goroutine再次运行的时候,counter变量的值已经改变了,但是goroutine并没有更新自己的那个副本的值,而是继续使用这个副本的值,用这个值递增,并存回counter变量,结果覆盖了另一个goroutine完成的工作。
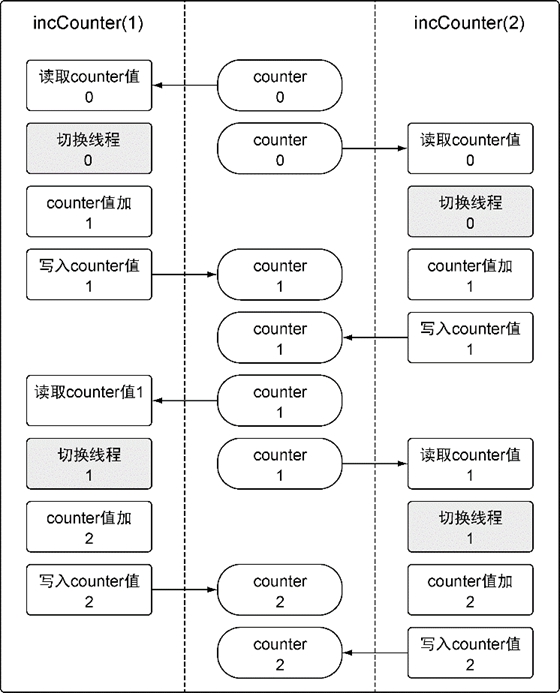
图6-5 竞争状态下程序行为的图像表达
让我们顺着程序理解一下发生了什么。在第25行和第26行,使用incCounter函数创建了两个goroutine。在第34行,incCounter函数对包内变量counter进行了读和写操作,而这个变量是这个示例程序里的共享资源。每个goroutine都会先读出这个counter变量的值,并在第40行将counter变量的副本存入一个叫作value的本地变量。之后在第46行,incCounter函数对value的副本的值加1,最终在第49行将这个新值存回到counter变量。这个函数在第43行调用了runtime包的Gosched函数,用于将goroutine从当前线程退出,给其他goroutine运行的机会。在两次操作中间这样做的目的是强制调度器切换两个goroutine,以便让竞争状态的效果变得更明显。
Go语言有一个特别的工具,可以在代码里检测竞争状态。在查找这类错误的时候,这个工具非常好用,尤其是在竞争状态并不像这个例子里这么明显的时候。让我们用这个竞争检测器来检测一下我们的例子代码,如代码清单6-11所示。
代码清单6-11 用竞争检测器来编译并执行listing09的代码
go build -race // 用竞争检测器标志来编译程序
./example // 运行程序
==================
WARNING: DATA RACE
Write by goroutine 5:
main.incCounter()
/example/main.go:49 +0x96
Previous read by goroutine 6:
main.incCounter()
/example/main.go:40 +0x66
Goroutine 5 (running) created at:
main.main()
/example/main.go:25 +0x5c
Goroutine 6 (running) created at:
main.main()
/example/main.go:26 +0x73
==================
Final Counter: 2
Found 1 data race(s)代码清单6-11中的竞争检测器指出这个例子里面代码清单6-12所示的4行代码有问题。
代码清单6-12 竞争检测器指出的代码
Line 49: counter = value
Line 40: value := counter
Line 25: go incCounter(1)
Line 26: go incCounter(2)代码清单6-12展示了竞争检测器查到的哪个goroutine引发了数据竞争,以及哪两行代码有冲突。毫不奇怪,这几行代码分别是对counter变量的读和写操作。
一种修正代码、消除竞争状态的办法是,使用Go语言提供的锁机制,来锁住共享资源,从而保证goroutine的同步状态。
Go语言提供了传统的同步goroutine的机制,就是对共享资源加锁。如果需要顺序访问一个整型变量或者一段代码,atomic和sync包里的函数提供了很好的解决方案。下面我们了解一下atomic包里的几个函数以及sync包里的mutex类型。
原子函数能够以很底层的加锁机制来同步访问整型变量和指针。我们可以用原子函数来修正代码清单6-9中创建的竞争状态,如代码清单6-13所示。
代码清单6-13 listing13.go
01 // 这个示例程序展示如何使用atomic包来提供
02 // 对数值类型的安全访问
03 package main
04
05 import (
06 "fmt"
07 "runtime"
08 "sync"
09 "sync/atomic"
10 )
11
12 var (
13 // counter是所有goroutine都要增加其值的变量
14 counter int64
15
16 // wg用来等待程序结束
17 wg sync.WaitGroup
18 )
19
20 // main是所有Go程序的入口
21 func main() {
22 // 计数加2,表示要等待两个goroutine
23 wg.Add(2)
24
25 // 创建两个goroutine
26 go incCounter(1)
27 go incCounter(2)
28
29 // 等待goroutine结束
30 wg.Wait()
31
32 // 显示最终的值
33 fmt.Println("Final Counter:", counter)
34 }
35
36 // incCounter增加包里counter变量的值
37 func incCounter(id int) {
38 // 在函数退出时调用Done来通知main函数工作已经完成
39 defer wg.Done()
40
41 for count := 0; count < 2; count++ {
42 // 安全地对counter加1
43 atomic.AddInt64(&counter, 1)
44
45 // 当前goroutine从线程退出,并放回到队列
46 runtime.Gosched()
47 }
48 }对应的输出如代码清单6-14所示。
代码清单6-14 listing13.go的输出
Final Counter: 4现在,程序的第43行使用了atmoic包的AddInt64函数。这个函数会同步整型值的加法,方法是强制同一时刻只能有一个goroutine运行并完成这个加法操作。当goroutine试图去调用任何原子函数时,这些goroutine都会自动根据所引用的变量做同步处理。现在我们得到了正确的值4。
另外两个有用的原子函数是LoadInt64和StoreInt64。这两个函数提供了一种安全地读和写一个整型值的方式。代码清单6-15中的示例程序使用LoadInt64和StoreInt64来创建一个同步标志,这个标志可以向程序里多个goroutine通知某个特殊状态。
代码清单6-15 listing15.go
01 // 这个示例程序展示如何使用atomic包里的
02 // Store和Load类函数来提供对数值类型
03 // 的安全访问
04 package main
05
06 import (
07 "fmt"
08 "sync"
09 "sync/atomic"
10 "time"
11 )
12
13 var (
14 // shutdown是通知正在执行的goroutine停止工作的标志
15 shutdown int64
16
17 // wg用来等待程序结束
18 wg sync.WaitGroup
19 )
20
21 // main是所有Go程序的入口
22 func main() {
23 // 计数加2,表示要等待两个goroutine
24 wg.Add(2)
25
26 // 创建两个goroutine
27 go doWork("A")
28 go doWork("B")
29
30 // 给定goroutine执行的时间
31 time.Sleep(1 * time.Second)
32
33 // 该停止工作了,安全地设置shutdown标志
34 fmt.Println("Shutdown Now")
35 atomic.StoreInt64(&shutdown, 1)
36
37 // 等待goroutine结束
38 wg.Wait()
39 }
40
41 // doWork用来模拟执行工作的goroutine,
42 // 检测之前的shutdown标志来决定是否提前终止
43 func doWork(name string) {
44 // 在函数退出时调用Done来通知main函数工作已经完成
45 defer wg.Done()
46
47 for {
48 fmt.Printf("Doing %s Work\n", name)
49 time.Sleep(250 * time.Millisecond)
50
51 // 要停止工作了吗?
52 if atomic.LoadInt64(&shutdown) == 1 {
53 fmt.Printf("Shutting %s Down\n", name)
54 break
55 }
56 }
57 }在这个例子中,启动了两个goroutine,并完成一些工作。在各自循环的每次迭代之后,在第52行中goroutine会使用LoadInt64来检查shutdown变量的值。这个函数会安全地返回shutdown变量的一个副本。如果这个副本的值为1,goroutine就会跳出循环并终止。
在第35行中,main函数使用StoreInt64函数来安全地修改shutdown变量的值。如果哪个doWork goroutine试图在main函数调用StoreInt64的同时调用LoadInt64函数,那么原子函数会将这些调用互相同步,保证这些操作都是安全的,不会进入竞争状态。
另一种同步访问共享资源的方式是使用互斥锁(mutex)。互斥锁这个名字来自互斥(mutual exclusion)的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个goroutine可以执行这个临界区代码。我们还可以用互斥锁来修正代码清单6-9中创建的竞争状态,如代码清单6-16所示。
代码清单6-16 listing16.go
01 // 这个示例程序展示如何使用互斥锁来
02 // 定义一段需要同步访问的代码临界区
03 // 资源的同步访问
04 package main
05
06 import (
07 "fmt"
08 "runtime"
09 "sync"
10 )
11
12 var (
13 // counter是所有goroutine都要增加其值的变量
14 counter int
15
16 // wg用来等待程序结束
17 wg sync.WaitGroup
18
19 // mutex 用来定义一段代码临界区
20 mutex sync.Mutex
21 )
22
23 // main是所有Go程序的入口
24 func main() {
25 // 计数加2,表示要等待两个goroutine
26 wg.Add(2)
27
28 // 创建两个goroutine
29 go incCounter(1)
30 go incCounter(2)
31
32 // 等待goroutine结束
33 wg.Wait()
34 fmt.Printf("Final Counter: %d\\n", counter)
35 }
36
37 // incCounter使用互斥锁来同步并保证安全访问,
38 // 增加包里counter变量的值
39 func incCounter(id int) {
40 // 在函数退出时调用Done来通知main函数工作已经完成
41 defer wg.Done()
42
43 for count := 0; count < 2; count++ {
44 // 同一时刻只允许一个goroutine进入
45 // 这个临界区
46 mutex.Lock()
47 {
48 // 捕获counter的值
49 value := counter
50
51 // 当前goroutine从线程退出,并放回到队列
52 runtime.Gosched()
53
54 // 增加本地value变量的值
55 value++
56
57 // 将该值保存回counter
58 counter = value
59 }
60 mutex.Unlock()
61 // 释放锁,允许其他正在等待的goroutine
62 // 进入临界区
63 }
64 }对counter变量的操作在第46行和第60行的Lock()和Unlock()函数调用定义的临界区里被保护起来。使用大括号只是为了让临界区看起来更清晰,并不是必需的。同一时刻只有一个goroutine可以进入临界区。之后,直到调用Unlock()函数之后,其他goroutine才能进入临界区。当第52行强制将当前goroutine退出当前线程后,调度器会再次分配这个goroutine继续运行。当程序结束时,我们得到正确的值4,竞争状态不再存在。
原子函数和互斥锁都能工作,但是依靠它们都不会让编写并发程序变得更简单,更不容易出错,或者更有趣。在Go语言里,你不仅可以使用原子函数和互斥锁来保证对共享资源的安全访问以及消除竞争状态,还可以使用通道,通过发送和接收需要共享的资源,在goroutine之间做同步。
当一个资源需要在goroutine之间共享时,通道在goroutine之间架起了一个管道,并提供了确保同步交换数据的机制。声明通道时,需要指定将要被共享的数据的类型。可以通过通道共享内置类型、命名类型、结构类型和引用类型的值或者指针。
在Go语言中需要使用内置函数make来创建一个通道,如代码清单6-17所示。
代码清单6-17 使用make创建通道
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)在代码清单6-17中,可以看到使用内置函数make创建了两个通道,一个无缓冲的通道,一个有缓冲的通道。make的第一个参数需要是关键字chan,之后跟着允许通道交换的数据的类型。如果创建的是一个有缓冲的通道,之后还需要在第二个参数指定这个通道的缓冲区的大小。
向通道发送值或者指针需要用到<-操作符,如代码清单6-18所示。
代码清单6-18 向通道发送值
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"在代码清单6-18里,我们创建了一个有缓冲的通道,数据类型是字符串,包含一个10个值的缓冲区。之后我们通过通道发送字符串"Gopher"。为了让另一个goroutine可以从该通道里接收到这个字符串,我们依旧使用<-操作符,但这次是一元运算符,如代码清单6-19所示。
代码清单6-19 从通道里接收值
// 从通道接收一个字符串
value := <-buffered当从通道里接收一个值或者指针时,<-运算符在要操作的通道变量的左侧,如代码清单6-19所示。
通道是否带有缓冲,其行为会有一些不同。理解这个差异对决定到底应该使用还是不使用缓冲很有帮助。下面我们分别介绍一下这两种类型。
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。如果两个goroutine没有同时准备好,通道会导致先执行发送或接收操作的goroutine阻塞等待。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
在图6-6里,可以看到一个例子,展示两个goroutine如何利用无缓冲的通道来共享一个值。在第1步,两个goroutine都到达通道,但哪个都没有开始执行发送或者接收。在第2步,左侧的goroutine将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个goroutine会在通道中被锁住,直到交换完成。在第3步,右侧的goroutine将它的手放入通道,这模拟了从通道里接收数据。这个goroutine一样也会在通道中被锁住,直到交换完成。在第4步和第5步,进行交换,并最终,在第6步,两个goroutine都将它们的手从通道里拿出来,这模拟了被锁住的goroutine得到释放。两个goroutine现在都可以去做别的事情了。
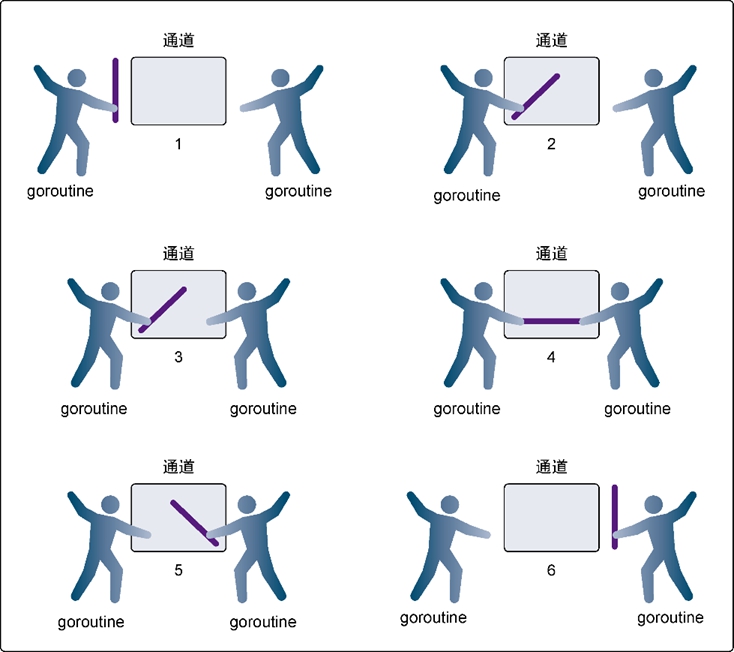
图6-6 使用无缓冲的通道在goroutine之间同步
为了讲得更清楚,让我们来看两个完整的例子。这两个例子都会使用无缓冲的通道在两个goroutine之间同步交换数据。
在网球比赛中,两位选手会把球在两个人之间来回传递。选手总是处在以下两种状态之一:要么在等待接球,要么将球打向对方。可以使用两个goroutine来模拟网球比赛,并使用无缓冲的通道来模拟球的来回,如代码清单6-20所示。
代码清单6-20 listing20.go
01 // 这个示例程序展示如何用无缓冲的通道来模拟
02 // 2个goroutine间的网球比赛
03 package main
04
05 import (
06 "fmt"
07 "math/rand"
08 "sync"
09 "time"
10 )
11
12 // wg用来等待程序结束
13 var wg sync.WaitGroup
14
15 func init() {
16 rand.Seed(time.Now().UnixNano())
17 }
18
19 // main是所有Go程序的入口
20 func main() {
21 // 创建一个无缓冲的通道
22 court := make(chan int)
23
24 // 计数加2,表示要等待两个goroutine
25 wg.Add(2)
26
27 // 启动两个选手
28 go player("Nadal", court)
29 go player("Djokovic", court)
30
31 // 发球
32 court <- 1
33
34 // 等待游戏结束
35 wg.Wait()
36 }
37
38 // player 模拟一个选手在打网球
39 func player(name string, court chan int) {
40 // 在函数退出时调用Done来通知main函数工作已经完成
41 defer wg.Done()
42
43 for {
44 // 等待球被击打过来
45 ball, ok := <-court
46 if !ok {
47 // 如果通道被关闭,我们就赢了
48 fmt.Printf("Player %s Won\n", name)
49 return
50 }
51
52 // 选随机数,然后用这个数来判断我们是否丢球
53 n := rand.Intn(100)
54 if n%13 == 0 {
55 fmt.Printf("Player %s Missed\n", name)
56
57 // 关闭通道,表示我们输了
58 close(court)
59 return
60 }
61
62 // 显示击球数,并将击球数加1
63 fmt.Printf("Player %s Hit %d\n", name, ball)
64 ball++
65
66 // 将球打向对手
67 court <- ball
68 }
69 }运行这个程序会得到代码清单6-21所示的输出。
代码清单6-21 listing20.go的输出
Player Nadal Hit 1
Player Djokovic Hit 2
Player Nadal Hit 3
Player Djokovic Missed
Player Nadal Won在main函数的第22行,创建了一个int类型的无缓冲的通道,让两个goroutine在击球时能够互相同步。之后在第28行和第29行,创建了参与比赛的两个goroutine。在这个时候,两个goroutine都阻塞住等待击球。在第32行,将球发到通道里,程序开始执行这个比赛,直到某个goroutine输掉比赛。
在player函数里,在第43行可以找到一个无限循环的for语句。在这个循环里,是玩游戏的过程。在第45行,goroutine从通道接收数据,用来表示等待接球。这个接收动作会锁住goroutine,直到有数据发送到通道里。通道的接收动作返回时,第46行会检测ok标志是否为false。如果这个值是false,表示通道已经被关闭,游戏结束。在第53行到第60行,会产生一个随机数,用来决定goroutine是否击中了球。如果击中了球,在第64行ball的值会递增1,并在第67行,将ball作为球重新放入通道,发送给另一位选手。在这个时刻,两个goroutine都会被锁住,直到交换完成。最终,某个goroutine没有打中球,在第58行关闭通道。之后两个goroutine都会返回,通过defer声明的Done会被执行,程序终止。
另一个例子,用不同的模式,使用无缓冲的通道,在goroutine之间同步数据,来模拟接力比赛。在接力比赛里,4个跑步者围绕赛道轮流跑(如代码清单6-22所示)。第二个、第三个和第四个跑步者要接到前一位跑步者的接力棒后才能起跑。比赛中最重要的部分是要传递接力棒,要求同步传递。在同步接力棒的时候,参与接力的两个跑步者必须在同一时刻准备好交接。
代码清单6-22 listing22.go
01 // 这个示例程序展示如何用无缓冲的通道来模拟
02 // 4个goroutine间的接力比赛
03 package main
04
05 import (
06 "fmt"
07 "sync"
08 "time"
09 )
10
11 // wg用来等待程序结束
12 var wg sync.WaitGroup
13
14 // main是所有Go程序的入口
15 func main() {
16 // 创建一个无缓冲的通道
17 baton := make(chan int)
18
19 // 为最后一位跑步者将计数加1
20 wg.Add(1)
21
22 // 第一位跑步者持有接力棒
23 go Runner(baton)
24
25 // 开始比赛
26 baton <- 1
27
28 // 等待比赛结束
29 wg.Wait()
30 }
31
32 // Runner模拟接力比赛中的一位跑步者
33 func Runner(baton chan int) {
34 var newRunner int
35
36 // 等待接力棒
37 runner := <-baton
38
39 // 开始绕着跑道跑步
40 fmt.Printf("Runner %d Running With Baton\n", runner)
41
42 // 创建下一位跑步者
43 if runner != 4 {
44 newRunner = runner + 1
45 fmt.Printf("Runner %d To The Line\n", newRunner)
46 go Runner(baton)
47 }
48
49 // 围绕跑道跑
50 time.Sleep(100 * time.Millisecond)
51
52 // 比赛结束了吗?
53 if runner == 4 {
54 fmt.Printf("Runner %d Finished, Race Over\n", runner)
55 wg.Done()
56 return
57 }
58
59 // 将接力棒交给下一位跑步者
60 fmt.Printf("Runner %d Exchange With Runner %d\n",
61 runner,
62 newRunner)
63
64 baton <- newRunner
65 }运行这个程序会得到代码清单6-23所示的输出。
代码清单6-23 listing22.go 的输出
Runner 1 Running With Baton
Runner 1 To The Line
Runner 1 Exchange With Runner 2
Runner 2 Running With Baton
Runner 2 To The Line
Runner 2 Exchange With Runner 3
Runner 3 Running With Baton
Runner 3 To The Line
Runner 3 Exchange With Runner 4
Runner 4 Running With Baton
Runner 4 Finished, Race Over在main函数的第17行,创建了一个无缓冲的int类型的通道baton,用来同步传递接力棒。在第20行,我们给WaitGroup加1,这样main函数就会等最后一位跑步者跑步结束。在第23行创建了一个goroutine,用来表示第一位跑步者来到跑道。之后在第26行,将接力棒交给这个跑步者,比赛开始。最终,在第29行,main函数阻塞在WaitGroup,等候最后一位跑步者完成比赛。
在Runner goroutine里,可以看到接力棒baton是如何在跑步者之间传递的。在第37行,goroutine对baton通道执行接收操作,表示等候接力棒。一旦接力棒传了进来,在第46行就会创建一位新跑步者,准备接力下一棒,直到goroutine是第四个跑步者。在第50行,跑步者围绕跑道跑100 ms。在第55行,如果第四个跑步者完成了比赛,就调用Done,将WaitGroup减1,之后goroutine返回。如果这个goroutine不是第四个跑步者,那么在第64行,接力棒会交到下一个已经在等待的跑步者手上。在这个时候,goroutine会被锁住,直到交接完成。
在这两个例子里,我们使用无缓冲的通道同步goroutine,模拟了网球和接力赛。代码的流程与这两个活动在真实世界中的流程完全一样,这样的代码很容易读懂。现在知道了无缓冲的通道是如何工作的,接下来我们会学习有缓冲的通道的工作方法。
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求goroutine之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的goroutine会在同一时间进行数据交换;有缓冲的通道没有这种保证。
在图6-7中可以看到两个goroutine分别向有缓冲的通道里增加一个值和从有缓冲的通道里移除一个值。在第1步,右侧的goroutine正在从通道接收一个值。在第2步,右侧的这个goroutine独立完成了接收值的动作,而左侧的goroutine正在发送一个新值到通道里。在第3步,左侧的goroutine还在向通道发送新值,而右侧的goroutine正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。最后,在第4步,所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。

图6-7 使用有缓冲的通道在goroutine之间同步数据
让我们看一个使用有缓冲的通道的例子,这个例子管理一组goroutine来接收并完成工作。有缓冲的通道提供了一种清晰而直观的方式来实现这个功能,如代码清单6-24所示。
代码清单6-24 listing24.go
01 // 这个示例程序展示如何使用
02 // 有缓冲的通道和固定数目的
03 // goroutine来处理一堆工作
04 package main
05
06 import (
07 "fmt"
08 "math/rand"
09 "sync"
10 "time"
11 )
12
13 const (
14 numberGoroutines = 4 // 要使用的goroutine的数量
15 taskLoad = 10 // 要处理的工作的数量
16 )
17
18 // wg用来等待程序完成
19 var wg sync.WaitGroup
20
21 // init初始化包,Go语言运行时会在其他代码执行之前
22 // 优先执行这个函数
23 func init() {
24 // 初始化随机数种子
25 rand.Seed(time.Now().Unix())
26 }
27
28 // main是所有Go程序的入口
29 func main() {
30 // 创建一个有缓冲的通道来管理工作
31 tasks := make(chan string, taskLoad)
32
33 // 启动goroutine来处理工作
34 wg.Add(numberGoroutines)
35 for gr := 1; gr <= numberGoroutines; gr++ {
36 go worker(tasks, gr)
37 }
38
39 // 增加一组要完成的工作
40 for post := 1; post <= taskLoad; post++ {
41 tasks <- fmt.Sprintf("Task : %d", post)
42 }
43
44 // 当所有工作都处理完时关闭通道
45 // 以便所有goroutine退出
46 close(tasks)
47
48 // 等待所有工作完成
49 wg.Wait()
50 }
51
52 // worker作为goroutine启动来处理
53 // 从有缓冲的通道传入的工作
54 func worker(tasks chan string, worker int) {
55 // 通知函数已经返回
56 defer wg.Done()
57
58 for {
59 // 等待分配工作
60 task, ok := <-tasks
61 if !ok {
62 // 这意味着通道已经空了,并且已被关闭
63 fmt.Printf("Worker: %d : Shutting Down\n", worker)
64 return
65 }
66
67 // 显示我们开始工作了
68 fmt.Printf("Worker: %d : Started %s\n", worker, task)
69
70 // 随机等一段时间来模拟工作
71 sleep := rand.Int63n(100)
72 time.Sleep(time.Duration(sleep) * time.Millisecond)
73
74 // 显示我们完成了工作
75 fmt.Printf("Worker: %d : Completed %s\n", worker, task)
76 }
77 }运行这个程序会得到代码清单6-25所示的输出。
代码清单6-25 listing24.go的输出
Worker: 1 : Started Task : 1
Worker: 2 : Started Task : 2
Worker: 3 : Started Task : 3
Worker: 4 : Started Task : 4
Worker: 1 : Completed Task : 1
Worker: 1 : Started Task : 5
Worker: 4 : Completed Task : 4
Worker: 4 : Started Task : 6
Worker: 1 : Completed Task : 5
Worker: 1 : Started Task : 7
Worker: 2 : Completed Task : 2
Worker: 2 : Started Task : 8
Worker: 3 : Completed Task : 3
Worker: 3 : Started Task : 9
Worker: 1 : Completed Task : 7
Worker: 1 : Started Task : 10
Worker: 4 : Completed Task : 6
Worker: 4 : Shutting Down
Worker: 3 : Completed Task : 9
Worker: 3 : Shutting Down
Worker: 2 : Completed Task : 8
Worker: 2 : Shutting Down
Worker: 1 : Completed Task : 10
Worker: 1 : Shutting Down由于程序和Go语言的调度器带有随机成分,这个程序每次执行得到的输出会不一样。不过,通过有缓冲的通道,使用所有4个goroutine来完成工作,这个流程不会变。从输出可以看到每个goroutine是如何接收从通道里分发的工作。
在main函数的第31行,创建了一个string类型的有缓冲的通道,缓冲的容量是10。在第34行,给WaitGroup赋值为4,代表创建了4个工作goroutine。之后在第35行到第37行,创建了4个goroutine,并传入用来接收工作的通道。在第40行到第42行,将10个字符串发送到通道,模拟发给goroutine的工作。一旦最后一个字符串发送到通道,通道就会在第46行关闭,而main函数就会在第49行等待所有工作的完成。
第46行中关闭通道的代码非常重要。当通道关闭后,goroutine依旧可以从通道接收数据,但是不能再向通道里发送数据。能够从已经关闭的通道接收数据这一点非常重要,因为这允许通道关闭后依旧能取出其中缓冲的全部值,而不会有数据丢失。从一个已经关闭且没有数据的通道里获取数据,总会立刻返回,并返回一个通道类型的零值。如果在获取通道时还加入了可选的标志,就能得到通道的状态信息。
在worker函数里,可以在第58行看到一个无限的for循环。在这个循环里,会处理所有接收到的工作。每个goroutine都会在第60行阻塞,等待从通道里接收新的工作。一旦接收到返回,就会检查ok标志,看通道是否已经清空而且关闭。如果ok的值是false,goroutine就会终止,并调用第56行通过defer声明的Done函数,通知main有工作结束。
如果ok标志是true,表示接收到的值是有效的。第71行和第72行模拟了处理的工作。一旦工作完成,goroutine会再次阻塞在第60行从通道获取数据的语句。一旦通道被关闭,这个从通道获取数据的语句会立刻返回,goroutine也会终止自己。
有缓冲的通道和无缓冲的通道的例子很好地展示了如何编写使用通道的代码。在下一章,我们会介绍真实世界里的一些可能会在工程里用到的并发模式。
go创建goroutine来运行函数。直到目前最新的1.8版本都是同一逻辑。可预见的未来版本也会保持这个逻辑。——译者注