图10-1 例10-1运行结果
★ 掌握auto、decltype、=default和=delete关键字的使用
★ 掌握基于范围的for循环的使用
★ 掌握lambda表达式的使用
★ 掌握C++11标准三个智能指针的使用
★ 掌握右值引用与移动构造
★ 了解move()函数与完美转发
★ 了解委托构造函数与继承构造函数
★ 了解函数包装
★ 掌握C++11标准中的多线程
★ 掌握互斥锁、lock_guard和unique_lock在多线程中的使用
★ 掌握条件变量和原子类型在多线程中的使用
★ 了解原生字符串、C++11标准对Unicode的支持
★ 了解C++11标准新增的一些常用库以及alignof和alginas运算符
C++11是由C++标准委员会于2011年发布的最新标准,在兼容早期C++98和C++03标准的基础上,增加了很多新特性,扩充了C++标准程序库,提高了语言的稳定性和兼容性。本章将为初学者介绍一些C++11中常用的新特性。
C++11标准具有的一个很大的特性就是提供了很多更有效、更便捷的代码编写方式,程序设计者可以使用更简短的代码实现C++98标准中同样的功能。本节将针对C++11标准中简洁的编程方式进行介绍。
C++11新增了很多关键字,这些关键字都各有用途,有的关键字功能很复杂,可以用在编程的各个方面。通过使用这些有特殊功能的关键字,可以极大地缩减代码量。下面重点介绍几个常用的C++11标准新增关键字。
1.auto
在C++11标准之前,auto关键字已经存在,其作用是限定变量的作用域。在C++11标准中,auto被赋予了新的功能,使用它可以让编译器自动推导出变量的类型。示例代码如下所示:
auto x = 10; //变量x为int类型
在上述代码中,使用auto定义了变量x,并赋值为10,则变量x的类型由它的初始化值决定。由于编译器根据初始化值推导并确定变量的类型,因此auto修饰的变量必须初始化。除了修饰变量,auto还可以作为函数的返回值,示例代码如下所示:
auto func()
{
//……功能代码
return 1;
}
需要注意的是,auto可以修饰函数的返回值,但是auto不能修饰函数参数。
除了修饰变量、函数返回值等,auto最大的用途就是简化模板编程中的代码,示例代码如下所示:
map<string, vector<int>> m;
for(auto value = m.begin(); value != m.end(); value++)
{
//……
}
如果不使用auto,则代码如下所示:
map<string, vector<int>> m;
map<string, vector<int>>::iterator value;
for(value = m.begin(); value != m.end(); value++)
{
//……
}
此外,在模板编程中,变量的类型依赖于模板参数,有时很难确定变量的类型。当不确定变量类型时,可以使用auto关键字解决,示例代码如下:
template<class T1, class T2>
void multiply(T1 x, T2 y)
{
auto result = x * y; //使用auto修饰变量result
}
2.decltype
decltype关键字是C++11标准新增的关键字,功能与auto关键字类似,也是在编译时期进行类型推导,但decltype的用法与auto不同,decltype关键字的使用格式如下所示:
decltype(表达式)
在上述格式中,decltype关键字会根据表达式的结果推导出数据类型,但它并不会真正计算出表达式的值。需要注意的是,decltype关键字的参数表达式不能是具体的数据类型。
decltype关键字的用法示例代码如下所示:
int a; int b; float f; cout << typeid(decltype(a+b)).name() << endl; //推导结果:int cout << typeid(decltype(a+f)).name() << endl; //推导结果:float cout << typeid(decltype(int)).name() << endl; //错误,不能通过编译
在程序设计中,可以使用decltype关键字推导出的类型定义新变量,示例代码如下所示:
int a; int b; float f; decltype(a + b) x; //定义int类型变量x decltype(a + f) y; //定义float类型变量y
decltype关键字最为强大的功能是在泛型编程中,与auto关键字结合使用推导函数返回值类型。auto作为函数返回值占位符,->decltype()放在函数后面用于推导函数返回值类型。示例代码如下所示:
template<class T1, class T2>
auto multiply(T1 x, T2 y)->decltype(x * y)
{
}
在泛型编程中,这种方式称为追踪返回类型,也称尾推导。有了->decltype(),程序设计者在编写代码时就无须关心任何时段的类型选择,编译器会进行合理的推导。
3.nullptr
在C语言中,为避免野指针的出现,通常使用NULL为指针赋值。C语言中NULL的定义如下所示:
#define NULL ((void *)0)
由上述定义可知,NULL是一个void*类型的指针,其值为0。在使用NULL给其他指针赋值时,发生了隐式类型转换,即将void*类型指针转换为要赋值的指针类型。
NULL的值被定义为字面常量0,这样会导致指针在使用过程中产生一些不可避免的错误。例如,有两个函数,函数声明如下所示:
void func(int a,int *p); void func(int a,int b)
在上述代码中,有两个重载函数func(),如果在调用第一个func()函数时,传入的第二个参数为0或NULL,则编译器总会调用第二个func()函数,即两个参数都是int类型的函数。这就与实际想要调用的函数相违背。如果想要根据传入的参数成功调用相应的func()函数,则需要使用static_cast转换运算符将0强制转换,示例代码如下所示:
func(1,0); //调用func(int a,int b) func(1,static_cast<int *>(0)); //调用func(int a,int *p)
虽然使用static_cast转换运算符解决了此问题,但是这种方式极易出错,而且会增加代码的复杂程度。
为了修复上述缺陷,C++11标准引入了一个新的关键字nullptr,nullptr也表示空指针,可以为指针赋值,避免出现野指针。但是,nullptr是一个有类型的空指针常量,当使用nullptr给指针赋值时,nullptr可以隐式转换为等号左侧的指针类型。需要注意的是,nullptr只能被转换为其他指针类型,不能转换为非指针类型。示例代码如下所示:
int* p = nullptr; //正确 int x = nullptr; //错误,nullptr不能转换为int类型
由于nullptr只能转换为其他指针类型,因此它能够消除字面常量0带来的二义性。在调用func()函数时,如果传入nullptr作为第二个参数,则func()函数能够被正确调用。示例代码如下所示:
func(1,0); //调用func(int a,int b) func(1,nullptr); //调用func(int a,int *p)
4.=default与=delete
构造函数、析构函数、拷贝构造函数等是类的特殊成员函数,如果在类中没有显式定义这些成员函数,编译器会提供默认的构造函数、析构函数、拷贝构造函数等。但是,如果在类中显式定义了这些函数,编译器将不会再提供默认的版本。例如,定义了动物类Anim al,并且在类中显式定义了构造函数,示例代码如下所示:
class Animal
{
public:
Animal(string name);
private:
string _name;
};
在上述代码中,定义了有参构造函数,则编译器不再提供默认的构造函数。如果在程序中需要调用无参构造函数,就需要程序设计者自己定义一个无参构造函数,即使这个无参构造函数体为空,并没有实现任何功能。在实际开发中,一个项目工程中的类非常多,这样做势必会增加代码量。
为了使代码更简洁、高效,C++11标准引入了一个新特性,在默认函数声明后面添加“=default”,显式地指示编译器生成该函数的默认版本。例如,在Anim al类中,使用“=default”指示编译器提供默认的构造函数,示例代码如下所示:
class Animal
{
public:
Animal() = default; //编译器会提供默认的构造函数
Animal(string name);
private:
string _name;
};
有时,我们不希望类的某些成员函数在类外被调用,例如,在类外禁止调用类的拷贝构造函数。在C++98标准中,通常的做法是显式声明类的拷贝构造函数,并将其声明为类的私有成员。而C++11标准提供了一种更简便的方法,在函数的声明后面加上“=delete”,编译器就会禁止函数在类外调用,这样的函数称为已删除函数。例如,禁止调用Anim al类的拷贝构造函数,则可以声明Anim al类的拷贝构造函数,并使用“=delete”进行修饰,示例代码如下所示:
class Animal
{
public:
//…
Animal(const Animal&) = delete; //在类外禁止调用拷贝构造函数
};
在上述代码中,使用“=delete”修饰拷贝构造函数,则在Anim al类外就无法再调用拷贝构造函数了。
除了修饰类的成员函数,“=delete”还可以修饰普通函数,被“=delete”修饰的普通函数,在程序中也会被禁止调用。示例代码如下所示:
void func(char ch) = delete;
func('a'); //错误
在上述代码中,func()函数被“=delete”修饰,当传入字符'a'调用func()函数时,编译器就会报错,提示“func()函数是已删除函数”。
在传统C++中,使用for循环遍历一组数据时,必须要明确指定for循环的遍历范围,但是在很多时候,对于一个有范围的集合,明确指定遍历范围是多余的,而且容易出现错误。针对这个问题,C++11标准提出了基于范围的for循环,该for循环语句可以自动确定遍历范围。基于范围的for循环语法格式如下所示:
for(变量:对象)
{
//…
}
在上述语法格式中,for循环语句会遍历对象,将取到的值赋给变量,执行完循环体中的操作之后,再自动获取对象中的下一个值赋给变量,直到对象中的数据被迭代完毕。
基于范围的for循环的用法示例代码如下所示:
vector<int> v = { 1,2,3,4,5,6 };
for(auto i:v)
cout << i <<" ";
lambda表达式是C++11标准中非常重要的一个新特性,它用于定义匿名函数,使得代码更加灵活、简洁。lambda表达式与普通函数类似,也有参数列表、返回值类型和函数体,只是它的定义方式更简洁,并且可以在函数内部定义。lambda表达式的语法格式如下所示:
[捕获列表](参数列表)->返回值类型 { 函数体 }
在上述语法格式中,参数列表、返回值类型、函数体的含义都与普通函数相同。如果lambda表达式不需要参数,并且函数没有返回值,则可以将()、->和返回值类型一起省略。捕获列表是lambda表达式的标识,编译器根据“[]”判断接下来的代码是否是lambda表达式。捕获列表能够捕获lambda表达式上下文中的变量,以供lambda表达式使用。
根据捕获规则,捕获列表有以下五种常用的捕获形式。
(1)[]:空捕获,表示lambda表达式不捕获任何变量。
(2)[var]:变量捕获,表示捕获局部变量var。如果捕获多个变量,变量之间用“,”分隔。
(3)[&var]:引用捕获,表示以引用方式捕获局部变量var。
(4)[=]:隐式捕获,表示捕获所有的局部变量。
(5)[&]:隐式引用捕获,表示以引用方式捕获所有的局部变量。
以上捕获方式还可以组合使用,通过组合,捕获列表可以实现更复杂的捕获功能,例如,[=,&a,&b]表示以引用方式捕获变量a和变量b,以值传递方式捕获其他所有变量。
下面通过案例演示lambda表达式的使用,如例10-1所示。
例10-1 lambda.cpp
1 #include<iostream>
2 #include<vector>
3 #include<algorithm>
4 using namespace std;
5 int main()
6 {
7 int num = 100;
8 //lambda表达式
9 auto f = [num](int x)->int {return x + num; };
10 cout << f(10) << endl;
11 //创建vector对象v
12 vector<int> v = { 54,148,3,848,2,89 };
13 //调用for_each()函数遍历输出v容器中的元素
14 for_each(v.begin(), v.end(), [](auto n) {
15 cout << n << " "; });
16 return 0;
17 }
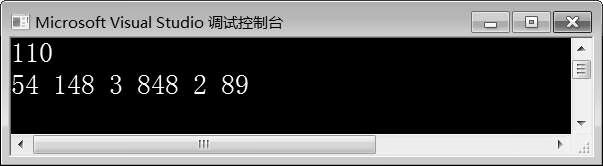
例10-1运行结果如图10-1所示。
图10-1 例10-1运行结果
在例10-1中,第9行代码定义了一个lambda表达式,该lambda表达式有一个int类型的参数x,返回值为int类型,并以值传递的方式捕获局部变量num;在函数体内部返回x与num之和。第10行代码通过变量f调用lambda表达式,lambda表达式的调用方式与普通函数的调用方式相同,都是使用“()”运算符传入参数。
第12~15行代码创建了vector对象v,并调用for_each()函数遍历对象v,输出其中的元素。for_each()函数的第三个参数是一个lambda表达式,该lambda表达式不捕获任何变量,它有一个int类型的参数n(对象v中的元素),在函数体中输出n的值。
由图10-1可知,程序成功输出了f(10)的结果为110,并成功输出了对象v中的元素。
在C++编程中,如果使用new手动申请了内存,则必须要使用delete手动释放,否则会造成内存泄漏。对内存管理来说,手动释放内存并不是一个好的解决方案,C++98标准提供了智能指针auto_ptr解决了内存的自动释放问题,但是auto_ptr有诸多缺点,例如,不能调用delete[],并且,如果auto_ptr出现错误,只能在运行时检测而无法在编译时检测。为此,C++11标准提出了三个新的智能指针:unique_ptr、shared_ptr和weak_ptr。unique_ptr、shared_ptr和weak_ptr是C++11标准提供的模板类,用于管理new申请的堆内存空间。这些模板类定义了一个以堆内存空间(new申请的)指针为参数的构造函数,在创建智能指针对象时,将new返回的指针作为参数。同样,这些模板类也定义了析构函数,在析构函数中调用delete释放new申请的内存。当智能指针对象生命周期结束时,系统调用析构函数释放new申请的内存空间。本节将针对这三个智能指针进行讲解。
unique_ptr智能指针主要用来代替C++98标准中的auto_ptr,它的使用方法与auto_ptr相同,创建unique_ptr智能指针对象的语法格式如下所示:
unique_ptr<T> 智能指针对象名称(指针);
在上述格式中,unique_ptr<T>是模板类型,后面是智能指针对象名称,遵守标识符命名规范。智能指针对象名称后面的小括号中的参数是一个指针,该指针是new运算符申请堆内存空间返回的指针。
unique_ptr智能指针的用法示例代码如下所示:
unique_ptr<int> pi(new int(10));
class A {…};
unique_ptr<A> pA(new A);
在上述代码中,第一行代码创建了一个unique_ptr智能指针对象pi,用于管理一个int类型堆内存空间指针。后两行代码创建了一个unique_ptr智能指针对象pA,用于管理一个A类型的堆内存空间指针。当程序运行结束时,即使没有delete,编译器也会调用unique_ptr模板类的析构函数释放new申请的堆内存空间。需要注意的是,使用智能指针需要包含m em ory头文件。
unique_ptr智能指针对象之间不可以赋值,错误示例代码如下所示:
unique_ptr<string> ps(new string("C++"));
unique_ptr<string> pt;
pt = ps; //错误,不能对unique_ptr智能指针赋值
在上述代码中,直接将智能指针ps赋值给智能指针pt,编译器会报错。这是因为在unique_ptr模板类中,使用“=delete”修饰了“=”运算符的重载函数。之所以这样做,是因为unique_ptr在实现时是通过所有权的方式管理new对象指针的,一个new对象指针只能被一个unique_ptr智能指针对象管理,即unique_ptr智能指针拥有对new对象指针的所有权。当发生赋值操作时,智能指针会转让所有权。例如,上述代码中的pt=ps语句,如果赋值成功,pt将拥有对new对象指针的所有权,而ps则失去所有权,指向无效的数据,成了危险的悬挂指针。如果后面程序中使用到ps,会造成程序崩溃。C++98标准中的auto_ptr就是这种实现方式,因此auto_ptr使用起来比较危险。C++11标准为了修复这种缺陷,就将unique_ptr限制为不能直接使用“=”进行赋值。
如果需要实现unique_ptr智能指针对象之间的赋值,可以调用C++标准库提供的m ove()函数,示例代码如下所示:
unique_ptr<string> ps(new string("C++"));
unique_ptr<string> pt;
pt = move(ps); //正确,可以通过编译
调用m ove()函数完成赋值之后,pt拥有new对象指针的所有权,而ps则被赋值为nullptr。
shared_ptr是一种智能级别更高的指针,它在实现时采用了引用计数的方式,多个shared_ptr智能指针对象可以同时管理一个new对象指针。每增加一个shared_ptr智能指针对象,new对象指针的引用计数就加1;当shared_ptr智能指针对象失效时,new对象指针的引用计数就减1,而其他shared_ptr智能指针对象的使用并不会受到影响。只有在引用计数归为0时,shared_ptr才会真正释放所管理的堆内存空间。
shared_ptr与unique_ptr用法相同,创建shared_ptr智能指针对象的格式如下所示:
shared_ptr<T> 智能指针对象名称(指针);
shared_ptr提供了一些成员函数以更方便地管理堆内存空间,下面介绍几个常用的成员函数。
(1)get()函数:用于获取shared_ptr管理的new对象指针,函数声明如下所示:
T* get() const;
在上述函数声明中,get()函数返回一个T*类型的指针。当使用cout输出get()函数的返回结果时,会得到new对象的地址。
(2)use_count()函数:用于获取new对象的引用计数,函数声明如下所示:
long use_count() const;
在上述函数声明中,use_count()函数返回一个long类型的数据,表示new对象的引用计数。(3)reset()函数:用于取消shared_ptr智能指针对象对new对象的引用,函数声明如下所示:
void reset();
在上述函数声明中,reset()的声明比较简单,既没有参数也没有返回值。当调用reset()函数之后,new对象的引用计数就会减1。取消引用之后,当前智能指针对象被赋值为nullptr。
下面通过案例演示shared_ptr智能指针的使用,如例10-2所示。
例10-2 shared_ptr.cpp
1 #include<iostream>
2 #include<memory>
3 using namespace std;
4 int main()
5 {
6 //创建shared_ptr智能指针对象language1、language2、language3
7 shared_ptr<string> language1(new string("C++"));
8 shared_ptr<string> language2 = language1;
9 shared_ptr<string> language3 = language1;
10 //通过智能指针对象language1、language2、language3调用get()函数
11 cout << "language1: " << language1.get() << endl;
12 cout << "language2: " << language2.get() << endl;
13 cout << "language3: " << language3.get() << endl;
14 cout << "引用计数:";
15 cout << language1.use_count() <<" ";
16 cout << language2.use_count() <<" ";
17 cout << language3.use_count() <<endl;
18 language1.reset();
19 cout << "引用计数:";
20 cout << language1.use_count()<<" ";
21 cout << language2.use_count()<<" ";
22 cout << language3.use_count() << endl;
23 cout << "language1: " << language1.get() << endl;
24 cout << "language2: " << language2.get() << endl;
25 cout << "language3: " << language3.get() << endl;
26 return 0;
27 }
例10-2的运行结果如图10-2所示。
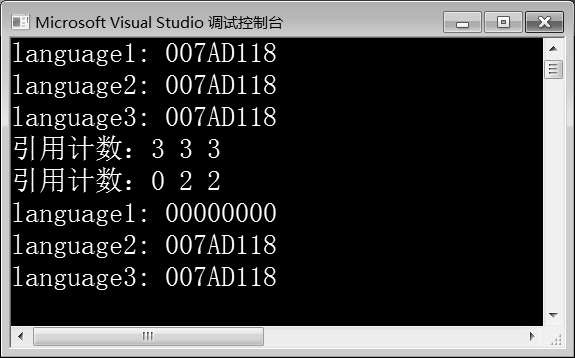
图10-2 例10-2运行结果
在例10-2中,第7~9行代码创建了shared_ptr智能指针对象language1、language2和language3,这三个智能指针对象都指向同一块堆内存空间。第11~13行代码分别通过三个智能指针对象调用get()函数,获取它们所管理的堆内存空间。由图10-2可知,第11~13行代码的输出结果相同,即这三个智能指针对象指向同一块内存空间。第15~17行代码分别通过三个智能指针对象调用use_count()函数,输出new对象的引用计数。第18行代码通过智能指针对象language1调用reset()函数,取消language1对new对象的引用。第20~22行代码再次通过三个智能指针对象调用use_count()函数,计算new对象的引用计数。由图10-2可知,第一次new对象的引用计数为3,当取消language1的引用之后,new对象的引用计数为2,而language1调用use_count()函数的结果为0。第23~25行代码再次通过三个智能指针对象调用get()函数,获取它们所管理的堆内存空间。
由图10-2可知,language2和language3仍旧指向地址为007AD 118的堆内存空间,而language1指向00000000,即nullptr的值。
相比于unique_ptr与shared_ptr,weak_ptr智能指针的使用更复杂一些,它可以指向shared_ptr管理的new对象,却没有该对象的所有权,即无法通过weak_ptr对象管理new对象。shared_ptr、weak_ptr和new对象的关系示意图如图10-3所示。
在图10-3中,shared_ptr对象和weak_ptr对象指向同一个new对象,但weak_ptr对象却不具有new对象的所有权。
weak_ptr模板类没有提供与unique_ptr、shared_ptr相同的构造函数,因此,不能通过传递new对象指针的方式创建weak_ptr对象。weak_ptr最常见的用法是验证shared_ptr对象的有效性。weak_ptr提供了一个成员函数lock(),该函数用于返回一个shared_ptr对象,如果weak_ptr指向的new对象没有shared_ptr引用,则lock()函数返回nullptr。
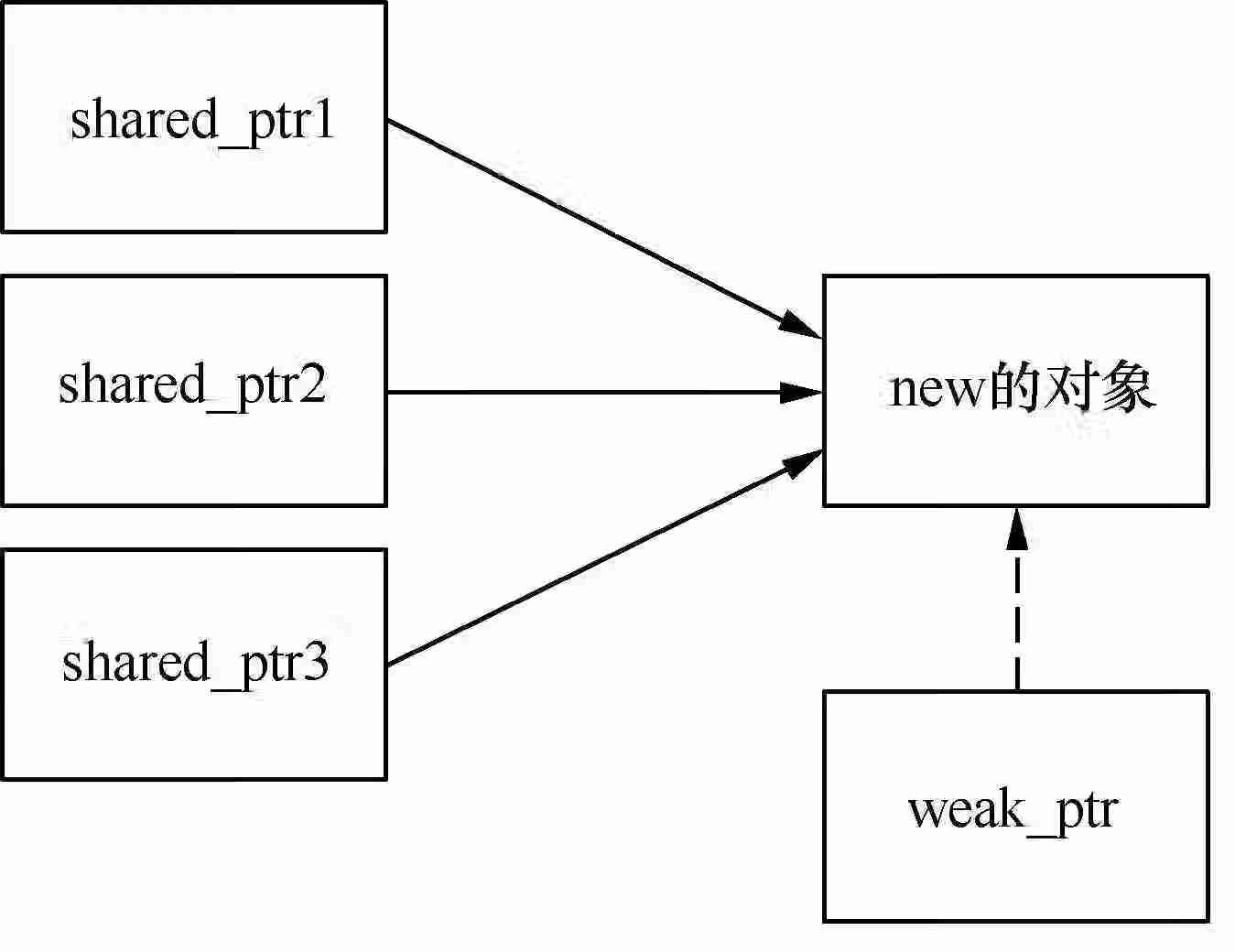
图10-3 shared_ptr、weak_ptr和new的对象的关系示意图
下面通过案例演示weak_ptr智能指针的使用,如例10-3所示。
例10-3 weak_ptr.cpp
1 #include<iostream>
2 #include<memory>
3 using namespace std;
4 void func(weak_ptr<string>& pw)
5 {
6 //通过pw.lock()获取一个shared_ptr对象
7 shared_ptr<string> ps = pw.lock();
8 if(ps != nullptr)
9 cout << "编程语言是" << *ps << endl;
10 else
11 cout << "shared_ptr智能指针失效!" << endl;
12 }
13 int main()
14 {
15 //定义shared_ptr对象pt1与pt2
16 shared_ptr<string> pt1(new string("C++"));
17 shared_ptr<string> pt2 = pt1;
18 //定义weak_ptr对象
19 weak_ptr<string> pw = pt1;
20 func(pw); //调用func()函数
21 *pt1 = "Java";
22 pt1.reset(); //取消pt1的引用
23 func(pw); //调用func()函数
24 pt2.reset(); //取消pt2的引用
25 func(pw); //调用func()函数
26 return 0;
27 }
例10-3的运行结果如图10-4所示。
在例10-3中,第4~12行代码定义了func()函数,该函数参数为weak_ptr<string>引用pw,在函数内部,通过pw调用lock()函数,然后判断返回值是否是有效的shared_ptr对象,如果是有效的shared_ptr对象,就输出shared_ptr对象指向的堆内存空间中的数据;如果不是有效的shared_ptr对象,就输出相应的提示信息。

图10-4 例10-3运行结果
第16~17行代码创建了shared_ptr<string>对象pt1和pt2,它们指向同一块堆内存空间。第19行代码,创建weak_ptr<string>对象pw,并将pt1赋值给pw。此时,pw、pt1和pt2指向同一块堆内存空间。第20行代码调用func()函数,并将pw作为参数传入。由图10-4可知,func()函数的输出结果为“编程语言是C++”。
第21~23行代码,通过pt1将堆内存空间中的数据修改为“Java”,并取消pt1对new对象的引用,然后调用func()函数。由图10-4可知,本次func()函数的输出结果为“编程语言是Java”。
第24~25行代码,取消pt2对new对象的引用,并调用func()函数。此时,new对象的shared_ptr引用计数为0,weak_ptr的lock()函数返回值为nullptr。由图10-4可知,本次func()函数的输出结果为“shared_ptr智能指针失效!”,表明weak_ptr的lock()函数返回值为nullptr。
在例10-3中,可以通过pt1修改new对象中的数据,但是,由于weak_ptr对new对象没有所有权,因此无法通过pw修改new对象中的数据。
除了简化编程方式,C++11标准也提高了C++语言编程效率,如定义了右值引用、移动构造等。效率就是语言的生命,因此,提高编程效率才是对语言改进的目标。本节将针对C++11标准中能够提高编程效率的常用部分进行讲解。
在C++11标准出现之前,程序中只有左值与右值的概念,简单来说,左值就是“=”符号左边的值,右值就是“=”符号右边的值。区分左值与右值的一个简单、有效的方法为:可以取地址的是左值,不可以取地址的是右值。
C++11标准对右值进行了更详细的划分,将右值分为纯右值与将亡值。纯右值是指字面常量、运算表达式、lambda表达式等;将亡值是那些即将被销毁却可以移动的值,如函数返回值。随着对右值的详细划分,C++11标准提出了右值引用的概念,右值引用就是定义一个标识符引用右值,右值引用通过“&&”符号定义,定义格式如下所示:
类型&& 引用名称=右值;
在上述格式中,类型是要引用的右值的数据类型,“&&”符号表明这是一个右值引用,引用名称遵守标识符命名规范,“=”符号后面是要引用的右值。
下面定义一些右值引用,示例代码如下所示:
int x = 10, y = 20; int&& r1 = 100; //字面常量100是一个右值 int&& r2 = x + y; //表达式x+y是一个右值 int&& r3 = sqrt(9.0); //函数返回值是一个右值
与左值引用相同,右值引用在定义时也必须初始化。右值引用只能引用右值,不能引用左值,错误示例代码如下所示:
int x = 10, y = 20; int&& a = x; //错误 int&& b = y; //错误
在上述代码中,变量x、y都是左值,因此不能将它们绑定到右值引用。需要注意的是,一个已经定义的右值引用是一个左值,即已经定义的右值引用是可以被赋值的变量,因此不能使用右值引用来引用另一个右值引用,示例代码如下所示:
int&& m = 100; int&& n = m; //错误,m是变量,是左值,不能被绑定到右值引用n上
C++11标准提出右值引用主要的目的就是在函数调用中解决将亡值(临时对象)带来的效率问题。下面通过案例演示传统C++程序对函数返回值的处理,如例10-4所示。
例10-4 func.cpp
1 #include<iostream>
2 using namespace std;
3 class A //定义类A
4 {
5 public:
6 A(){ cout << "构造函数" << endl; }
7 A(const A& a) { cout << "拷贝构造函数" << endl; }
8 ~A(){ cout << "析构函数" << endl; }
9 };
10 A func() //定义func()函数
11 {
12 A a; //创建对象a
13 return a; //返回对象a
14 }
15 int main()
16 {
17 A b = func(); //调用func()函数
18 return 0;
19 }
例10-4的运行结果如图10-5所示。
在例10-4中,第3~9行代码定义了类A,该类中定义了构造函数、拷贝构造函数和析构函数。第10~14行代码定义了func()函数,在函数内部创建对象a,并将对象a返回。第17行代码调用func()函数构造对象b。由图10-5可知,程序运行时先调用了构造函数、拷贝构造函数,然后调用了两次析构函数。
在func()函数的调用过程中,func()函数并不会直接将对象a返回出去,而是创建一个临时对象,将对象a的值赋给临时对象,在返回时,将临时对象返回给对象b。func()函数的返回过程如图10-6所示。
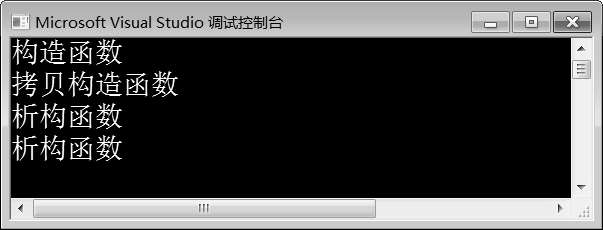
图10-5 例10-4运行结果

图10-6 func()函数的返回过程
由图10-6可知,func()函数在返回过程中经过了两次拷贝。函数调用结束后,对象a和临时对象都会被析构,这个过程就是重复的分配、释放内存。需要注意的是,图10-6只显示了一次拷贝构造函数的调用,因为VS2019编译器(遵守C++11标准)对程序进行了优化,减少了临时对象的生成。
如果函数返回的数据是非常大的堆内存数据,那么频繁的拷贝、析构过程会严重影响程序的运行效率。针对这个问题,C++11标准提出了右值引用的方法,在构造对象b时,直接通过右值引用的方式,让对象b引用临时对象,即对象b指向临时对象的内存空间。返回右值引用的func()函数返回过程如图10-7所示。

图10-7 返回右值引用的func()函数返回过程
由图10-7可知,使用右值引用时,对象b就指向了临时对象的内存空间,这块内存空间只有等到对象b被析构时才会被回收。右值引用实质上延长了临时对象的生命周期,减少了对象的拷贝、析构的次数,在实际项目开发中可以极大地提高程序运行效率。
要实现图10-7的构造过程,就需要定义相应的构造函数,这样的构造函数称为移动构造函数。移动构造函数也是特殊的成员函数,函数名称与类名相同,有一个右值引用作为参数。移动构造函数定义格式如下所示:
class 类名
{
public:
移动构造函数名称(类名&& 对象名)
{
函数体
}
…
};
在定义移动构造函数时,由于需要在函数内部修改参数对象,因此不使用const修饰引用的对象。下面通过修改例10-4演示移动构造函数的定义与调用,如例10-5所示。
例10-5 moveConstructor.cpp
1 #include<iostream>
2 using namespace std;
3 class A
4 {
5 public:
6 A(int n); //构造函数
7 A(const A& a); //拷贝构造函数
8 A(A&& a); //移动构造函数
9 ~A(); //析构函数
10 private:
11 int* p; //成员变量
12 };
13 A::A(int n):p(new int(n))
14 {
15 cout << "构造函数" << endl;
16 }
17 A::A(const A& a)
18 {
19 p = new int(*(a.p));
20 cout << "拷贝构造函数" << endl;
21 }
22 A::A(A&& a) //类外实现移动构造函数
23 {
24 p = a.p; //将当前对象指针指向a.p指向的空间
25 a.p = nullptr; //将a.p赋值为nullptr
26 cout << "移动构造函数" << endl;
27 }
28 A::~A()
29 {
30 cout << "析构函数" << endl;
31 }
32 A func()
33 {
34 A a(10);
35 return a;
36 }
37 int main()
38 {
39 A m = func();
40 return 0;
41 }
例10-5运行结果如图10-8所示。
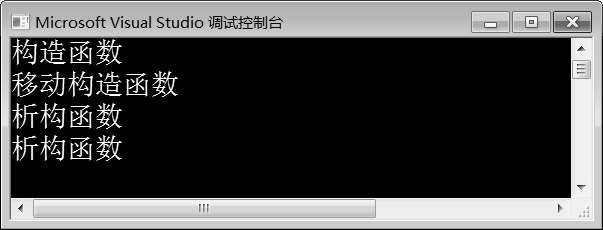
图10-8 例10-5运行结果
例10-5是对例10-4的修改,在类A中增加了一个成员变量int*p,并且定义了移动构造函数。在例10-5中,第22~27行代码在类外实现移动构造函数,在函数内部,首先使用a.p给当前对象的指针p赋值,即将当前对象的指针p指向参数对象a的指针指向的内存空间,然后将a.p赋值为nullptr。这样,一块内存空间只有一个指针是有效的,避免了同一块内存空间被析构两次。
由图10-8可知,程序调用了移动构造函数,而没有调用拷贝构造函数。在函数调用过程中,编译器会判断函数是否产生临时对象,如果产生临时对象,就会优先调用移动构造函数。若类中没有定义移动构造函数,编译器会调用拷贝构造函数。
与拷贝构造函数相比,移动构造函数是高效的,但它没有拷贝构造函数安全。例如,当程序抛出异常时,移动构造可能还未完成,这样可能会产生悬挂指针,导致程序崩溃。程序设计者在定义移动构造函数时,需要对类的资源有全面了解。
移动构造函数是通过右值引用实现的,对于左值,也可以将其转化为右值,实现程序的性能优化。C++11在标准库utility中提供了m ove()函数,该函数的功能就是将一个左值强制转换为右值,以便可以通过右值引用使用该值。
m ove()函数的用法示例代码如下所示:
int x = 10; int&& r = move(x); //将左值x强制转换为右值
在上述代码中,m ove()函数将左值x强制转换为右值,赋值给右值引用r。
如果类中有指针或者动态数组成员,在对象被拷贝或赋值时,可以直接调用m ove()函数将对象转换为右值,去初始化另一个对象。使用右值进行初始化,调用的是移动构造函数,而不是拷贝构造函数,这样就可以避免大量数据的拷贝,能够极大地提高程序的运行效率。例如,在例10-5中,如果使用左值对象初始化另一个对象,则会调用拷贝构造函数,示例代码如下所示:
A a(100); A b(a); //对象a是左值,调用拷贝构造函数
但是,如果将对象a转换为右值,则会调用移动构造函数,示例代码如下所示:
A a(100); A c(move(a)); //对象a被转换为右值,调用移动构造函数
当对象内部有较大的堆内存数据时,应当定义移动构造函数,并使用m ove()函数完成对象之间的初始化,以避免没有意义的深拷贝。
10.3.1节讲解过,一个已经定义的右值引用其实是一个左值,这样在参数转发(传递)时就会产生一些问题。例如,在函数的嵌套调用时,外层函数接收一个右值作为参数,但外层函数将参数转发给内层函数时,参数就变成了一个左值,并不是它原来的类型了。下面通过案例演示参数转发的问题,如例10-6所示。
例10-6 transimit.cpp
1 #include<iostream>
2 using namespace std;
3 template<typename T>
4 void transimit(T& t) { cout << "左值" << endl; }
5 template<typename T>
6 void transimit(T&& t) { cout << "右值" << endl; }
7 template<typename U>
8 void test(U&& u)
9 {
10 transimit(u); //调用transimit()函数
11 transimit(move(u)); //调用transimit()函数
12 }
13 int main()
14 {
15 test(1); //调用test()函数
16 return 0;
17 }
例10-6运行结果如图10-9所示。
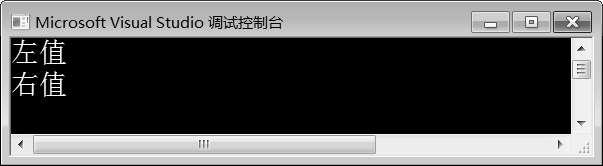
图10-9 例10-6运行结果
在例10-6中,第3~6行代码定义了两个重载的模板函数transim it(),第一个重载函数接收一个左值引用作为参数,第二个重载函数接收一个右值引用作为参数。第7~12行代码定义模板函数test(),在test()函数内部以不同的参数调用transim it()函数。第15行代码调用test()函数,传入右值1作为参数。由图10-9可知,使用右值1调用test()函数时,test()函数的输出结果是“左值”“右值”。在调用过程中,右值1到test()函数内部变成了左值,因此transim it(u)其实是接收的左值,输出了“左值”;第二次调用transim it()函数时,使用m ove()函数将左值转换为右值,因此transim it(m ove(u))输出结果为“右值”。
在例10-6中,调用test()函数时,传递的是右值,但在test()函数内部,第一次调用transim it()函数时,右值变为左值,这显然不符合程序设计者的期望。针对这种情况,C++11标准提供了一个函数forward(),它能够完全依照模板的参数类型,将参数传递给函数模板中调用的函数,即参数在转发过程中,参数类型一直保持不变,这种转发方式称为完美转发。例如,将例10-6中的第10行代码修改为下列形式:
transimit(forward<U>(u)); //调用forward()函数实现完美转发
此时,再调用test(1)函数时,其输出结果均为“右值”。forward()函数在实现完美转发时遵循引用折叠规则,该规则通过形参和实参的类型推导出内层函数接收到的参数的实际类型。引用折叠规则如表10-1所示。
表10-1 引用折叠规则实参类型
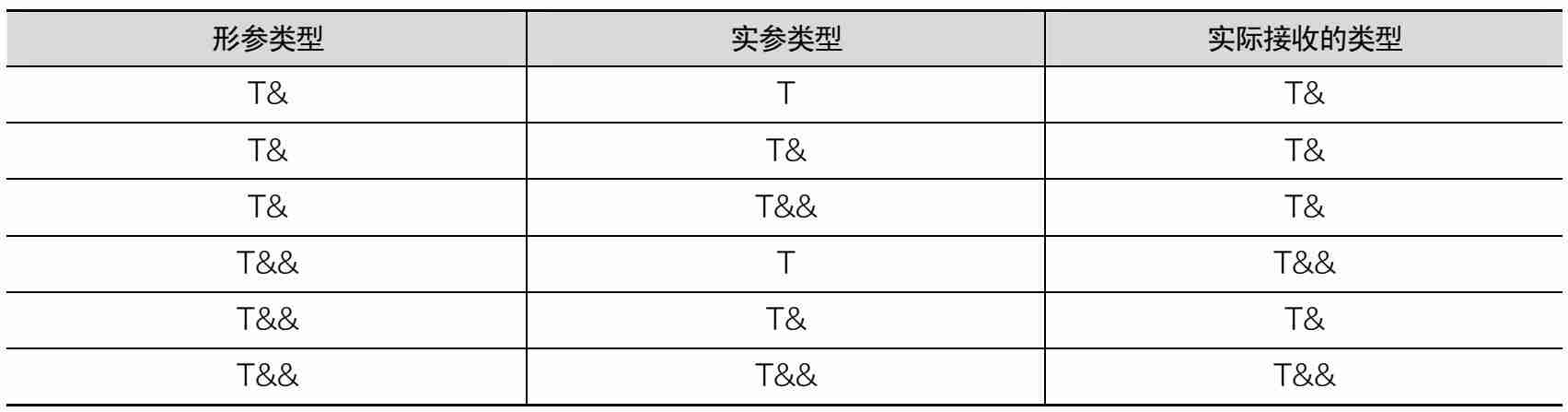
根据表10-1可推导出内层函数最终接收到的参数是左值引用还是右值引用。在引用折叠规则中,所有的右值引用都可以叠加,最后变成一个右值引用;所有的左值引用也都可以叠加,最后变成一个左值引用。
在C++11标准库中,完美转发的应用非常广泛,如一些简单好用的函数(如m ake_pair()、m ake_unique()等)都使用了完美转发,它们减少了函数版本的重复,并且充分利用了右值引用,既简化了代码量,又提高了程序的运行效率。
如果一个类定义了多个构造函数,这些构造函数就可能会有大量的重复代码。例如,有如下类定义:
class Student
{
public:
Student() {/*...其他代码*/ } //无参构造函数
Student(string name) //只有一个参数的构造函数
{
_name = name;
_id = 1001;
_score = 97.6;
//...其他代码
}
Student(string name,int id) //有两个参数的构造函数
{
_name = name;
_id = id;
_score = 98.5;
//...其他代码
}
Student(string name, int id, double score) //有三个参数的构造函数
{
_name = name;
_id = id;
_score = score;
//...其他代码
}
private:
string _name;
int _id;
double _score;
};
在上述代码中,每一个构造函数都需要给成员变量赋值,这些赋值语句都很重复。为了简化构造函数的编写,C++11标准提出了委托构造函数。委托构造函数就是在构造函数定义时,调用另一个已经定义好的构造函数完成对象的初始化。被委托的构造函数称为目标构造函数。例如,修改上述代码中Student类的定义,在类中定义委托构造函数,示例代码如下所示:
class Student
{
public:
Student():Student("lili",1003,99) { /*...其他代码*/ } //委托构造函数
Student(string name):Student(name,1001,97.6) //委托构造函数
{
//...其他代码
}
Student(string name, int id):Student(name,id,98.5) //委托构造函数
{
//...其他代码
}
private:
string _name;
int _id;
double _score;
Student(const string name, int id, double score) //目标构造函数
{
_name = name;
_id = id;
_score = score;
//...其他代码
}
};
上述代码中,无参构造函数、一个参数的构造函数、两个参数的构造函数都是委托构造函数,它们都委托有三个参数的目标构造函数完成对象的初始化工作。
委托构造函数体中的语句在目标构造函数完全执行后才被执行。目标构造函数体中的局部变量不在委托构造函数体中起作用。在定义委托构造函数时,目标构造函数还可以再委托给另一个构造函数。但是,需要注意的是,委托构造函数不能递归定义(即构造函数C1不能委托给另一个构造函数C2,而C2再委托给C1)。
在传统C++编程中,派生类不能继承基类的构造函数,无法通过继承直接调用基类构造函数完成基类成员变量的初始化。如果想要在派生类中完成基类成员变量的初始化,只能在派生类中定义若干构造函数,通过参数传递的方式,调用基类构造函数完成基类成员变量的初始化。
为了简化代码的编写,C++11标准提出了继承构造函数的概念,使用using关键字在派生类中引入基类的构造函数,格式如下所示:
using 基类名::构造函数名;
在派生类中使用using关键字引入基类构造函数之后,派生类就不需要再定义用于参数传递的构造函数了。C++11标准将继承构造函数设计为派生类的隐匿声明函数,如果某个继承构造函数不被调用,编译器不会为其生成真正的函数代码。
继承构造函数可以简化派生类的代码编写,但是它只能初始化基类的成员变量,无法初始化派生类的成员变量。如果要初始化派生类的成员变量,还需要定义相应的派生类构造函数。下面通过案例演示继承构造函数的调用,如例10-7所示。
例10-7 heritages.cpp
1 #include<iostream>
2 #include<string>
3 using namespace std;
4 class Base //定义基类Base
5 {
6 public:
7 Base(); //无参构造函数
8 Base(int num); //有一个int类型参数的构造函数
9 Base(double d); //有一个double类型参数的构造函数
10 Base(int num, double d); //有两个参数的构造函数
11 private:
12 int _num; //成员变量_num
13 double _d; //成员变量_d
14 };
15 Base::Base() :_num(0), _d(0)
16 {
17 cout << "Base无参构造函数" << endl;
18 }
19 Base::Base(int num):_num(num),_d(1.2)
20 {
21 cout << "Base构造函数,初始化int num" << endl;
22 }
23 Base::Base(double d):_num(100),_d(d)
24 {
25 cout << "Base构造函数,初始化double d" << endl;
26 }
27 Base::Base(int num, double d):_num(num),_d(d)
28 {
29 cout << "Base两个参数构造函数" << endl;
30 }
31 class Derive :public Base //定义派生类Derive
32 {
33 public:
34 using Base::Base; //继承基类构造函数
35 Derive(); //派生类无参构造函数
36 Derive(string name); //派生类有参构造函数
37 private:
38 string _name; //派生类成员变量_name
39 };
40 Derive::Derive():_name("xixi")
41 {
42 cout << "Derive无参构造函数" << endl;
43 }
44 Derive::Derive(string name):_name(name)
45 {
46 cout << "Derive有参构造函数" << endl;
47 }
48 int main()
49 {
50 Derive d1(); //调用Derive类的无参构造函数
51 Derive d2("qiqi"); //调用Derive类的有参构造函数
52 Derive d3(6); //调用Base类的有参构造函数,初始化int num
53 Derive d4(12.8); //调用Base类的有参构造函数,初始化double d
54 Derive d5(100, 2.9); //调用Base类的有两个参数的构造函数
55 return 0;
56 }
例10-7运行结果如图10-10所示。
在例10-7中,第4~14行代码定义了基类Base,该类中定义了两个成员变量和四个重载构造函数。第31~39行代码定义了派生类D erive,D erive类公有继承Base类,在D erive类中定义了一个成员变量和两个构造函数,并且使用using关键字继承了基类Base的构造函数。
第50行代码创建了对象d1,由于没有参数,因此对象d1会调用D erive类的无参构造函数。调用D erive类无参构造函数之前,编译器会调用Base类的无参构造函数,即先调用基类构造函数再调用派生类构造函数。由图10-10可知,创建对象d1时,先调用Base类无参构造函数,然后调用D erive类无参构造函数。

图10-10 例10-7运行结果
第51行代码创建了对象d2,传入了一个字符串参数。由图10-10可知,创建对象d2时,首先调用Base类无参构造函数,然后调用D erive类有参构造函数。这是因为创建对象d2时没有传入基类成员的初始化数据。
第52~54行代码创建了对象d3、d4和d5,对象d3传入一个int类型参数,对象d4传入一个double类型参数,对象d5传入一个int类型参数和一个double类型参数。由于D erive类没有相应的构造函数,因此编译器会调用继承构造函数。由图10-10可知,创建对象d3、d4、d5时,调用的是Base类的相应构造函数。
需要注意的是,在使用继承构造函数时,如果基类构造函数有默认值,则每个默认值使用与否的不同组合都会创建出新的构造函数,例如下面的代码:
class Base{
public:
Base(int n = 3, double d = 3.14) {} //带有默认值的构造函数
};
class Derive:public Base //Derive类公有继承Base类
{
using Base::Base; //继承构造函数
};
在上述代码中,基类Base中定义了一个构造函数,该构造函数的两个参数均有默认值,则基类的构造函数在调用时会存在多种情况,分别如下所示。
由于基类构造函数的版本有多个,因此派生类中的继承构造函数的版本也会有多个,分别如下所示。
由此可知,若基类的构造函数是带有参数默认值的构造函数,会产生多个构造函数,应特别小心。
此外,若派生类继承自多个基类,多个基类中的构造函数可能会导致派生类中的继承构造函数的函数名、参数相同,从而引发冲突。示例代码如下所示:
class Base1
{
public:
Base1(int x) {}
};
class Base2
{
public:
Base2(int x){}
};
class Derive:public Base1, public Base2
{
public:
using Base1::Base1;
using Base2::Base2;
};
在上述代码中,两个基类构造函数都拥有int类型参数,这会导致派生类中重复定义相同类型的继承构造函数。例如,通过D erive d(100)创建对象时,编译器会提示D erive()构造函数调用不明确。此时,可以通过显式定义派生类构造函数解决这种冲突,示例代码如下所示:
class Derive:public Base1, public Base2
{
public:
Derive(int x):Base1(x), Base2(x) {}
};
C++11标准提供了一个函数包装器function,function是一个类模板,它能够为多种类似的函数提供统一的调用接口,即对函数进行包装。function可以包装除类成员函数之外的所有函数,包括普通函数、函数指针、lambda表达式和仿函数。
在模板编程中,function能够用统一的方式处理函数,减少函数模板的实例化,因此可以提高程序的运行效率。在学习function之前来看一个案例,如例10-8所示。
例10-8 call.cpp
1 #include<iostream>
2 using namespace std;
3 //定义一个模板函数func()
4 template<typename T,typename U>
5 T func(T t, U u)
6 {
7 static int count = 0;
8 count++;
9 cout << "count= " << count << ",&count = " << &count << endl;
10 return u(t);
11 }
12 //定义普通函数square(),用于计算参数的平方
13 int square(int a)
14 {
15 return a * a;
16 }
17 class Student //定义类Student
18 {
19 private:
20 int _id;
21 public:
22 Student(int id = 1001) :_id(id) {}
23 int operator()(int num) { return _id + num; }
24 };
25 int main()
26 {
27 int x = 10;
28 //调用func()函数,第二个参数传入square()函数名
29 cout << "square()函数:" << func(x, square) << endl;
30 //调用func()函数,第二个参数传入仿函数Student()
31 cout << "Student类:" << func(x, Student(1002)) << endl;
32 //调用func()函数,第二个参数传入lambda表达式
33 cout << "lambda表达式:" << func(x, [](int b) {return b/2; }) << endl;
34 return 0;
35 }
例10-8运行结果如图10-11所示。
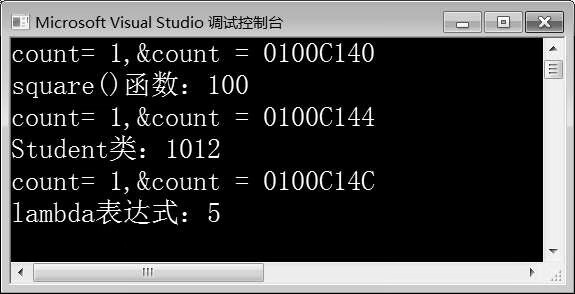
图10-11 例10-8运行结果
在例10-8中,第4~11行代码定义了函数模板func(),该函数模板有两个类型参数,并返回T类型的返回值。在函数模板内部,定义了静态变量count用于标识函数模板的调用情况。第13~16行代码定义了普通函数square(),用于计算一个整数的平方,并返回计算结果。第17~24行代码定义了学生类Student,该类重载了“()”运算符。
第29~33行代码在m ain()函数中调用func()函数。第29行代码调用func()函数,第二个参数传入square()函数名。第31行代码调用func()函数,第二个参数传入仿函数Student()。第33行代码调用func()函数,第二个参数传入一个lambda表达式。
由图10-11可知,三次调用func()时,静态变量count的地址都不相同,表明func()函数模板被实例化了三次。但是,分析square()函数、Student()仿函数、lambda表达式,它们都有一个int类型的参数,并且返回值都为int类型,它们的调用特征标相同。调用特征标由函数的返回值类型和参数列表的类型决定。例如,在例10-8中,square()函数、Student()仿函数、lambda表达式的调用特征标为int(int),即函数有一个int类型的参数,返回值类型为int。
调用特征标相同的函数作为参数去调用函数模板时,只实例化一个对应的函数。为此,C++11标准提供了function函数包装器,function可以从调用特征标的角度定义一个对象,用于包装调用特征标相同的函数指针、函数对象或lambda表达式。
例如,定义一个调用特征标为int(int)的function对象,示例代码如下所示:
function<int(int)> fi;
需要注意的是,function定义在functional标准库中,在使用function时,要包含该头文件。使用function包装调用特征标相同的函数,当使用这些函数作为参数调用函数模板时,function可以保证函数模板只实例化一次,下面通过修改例10-8演示function的使用,如例10-9所示。
例10-9 function.cpp
1 #include<iostream>
2 #include<functional
3 //#include "function.h"
4 using namespace std;
5 //定义一个模板函数func()
6 template<typename T,typename U>
7 T func(T t, U u)
8 {
9 static int count = 0;
10 count++;
11 cout << "count= " << count << ",&count = " << &count << endl;
12 return u(t);
13 }
14 //定义普通函数square(),用于求参数的平方
15 int square(int a)
16 {
17 return a * a;
18 }
19 class Student //定义类Student
20 {
21 private:
22 int _id;
23 public:
24 Student(int id = 1001) :_id(id) {}
25 int operator()(int num) { return _id + num; }
26 };
27 int main()
28 {
29 int x = 10;
30 function<int(int)> fi1 = square;
31 function<int(int)> fi2 = Student(1002);
32 function<int(int)> fi3 = [](int b) {return b / 2; };
33 cout << "square()函数:" << func(x, fi1) << endl;
34 cout << "Student类:" << func(x, fi2) << endl;
35 cout << "lambda表达式:" << func(x, fi3) << endl;
36 return 0;
37 }
例10-9的运行结果如图10-12所示。
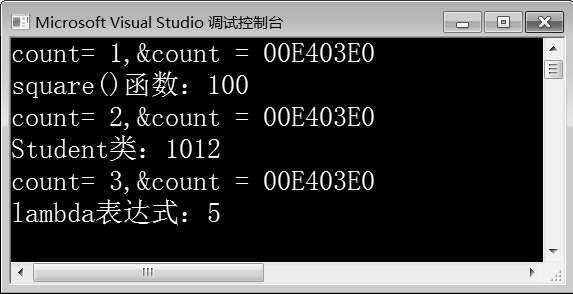
图10-12 例10-9运行结果
在例10-9中,第30~32行代码分别定义了三个function对象fi1、fi2、fi3。第33~35行代码,在调用func()函数时,分别传入fi1、fi2、fi3作为参数。由图10-12可知,三次调用时,静态变量count的数值分别为1、2、3,且三次调用的地址都相同,表明func()函数只实例化了一次。函数模板的实例化次数减少,程序的运行效率就会提高。
在实际开发中,C++项目都非常复杂庞大,函数模板的用途非常多,在调用函数模板时,通过function为调用特征标相同的函数提供统一的接口,可以极大地提高程序运行效率。
在例10-9中,定义了三个function对象,为简化编程,可以只定义一个function对象,在调用时分别传入不同的函数名、函数对象或lambda表达式即可,示例代码如下所示:
typedef function<int(int)> fi;
//…
func(x, fi(square));
func(x, fi(Student(1002)));
func(x, fi([](int b) {return b / 2; }))
在C++11标准之前,C++语言并没有对并行编程提供语言级别的支持,C++使用的多线程都由第三方库提供,如POSIX标准(pthread)、OpenM G库或W indows线程库,它们都是基于过程的多线程,这使得C++并行编程在可移植性方面存在诸多不足。为此,C++11标准增加了线程及线程相关的类,用于支持并行编程,极大地提高了C++并行编程的可移植性。本节将针对C++并行编程的相关知识进行讲解。
C++11标准提供了thread类模板用于创建线程,该类模板定义在thread标准库中,因此在创建线程时,需要包含thread头文件。thread类模板定义了一个无参构造函数和一个变参构造函数,因此在创建线程对象时,可以为线程传入参数,也可以不传入参数。需要注意的是,thread类模板不提供拷贝构造函数、赋值运算符重载等函数,因此线程对象之间不可以进行拷贝、赋值等操作。
除了构造函数,thread类模板还定义了两个常用的成员函数:join()函数和detach()函数。
(1)join()函数:该函数将线程和线程对象连接起来,即将子线程加入程序执行。join()函数是阻塞的,它可以阻塞主线程(当前线程),等待子线程工作结束之后,再启动主线程继续执行任务。
(2)detach()函数:该函数分离线程与线程对象,即主线程和子线程可同时进行工作,主线程不必等待子线程结束。但是,detach()函数分离的线程对象不能再调用join()函数将它与线程连接起来。
下面通过案例演示C++11标准中线程的创建与使用,如例10-10所示。
例10-10 thread.cpp
1 #include<iostream>
2 #include<thread> //包含头文件
3 using namespace std;
4 void func() //定义函数func()
5 {
6 cout << "子线程工作" << endl;
7 cout << "子线程工作结束" << endl;
8 }
9 int main()
10 {
11 cout << "主线程工作" << endl;
12 thread t(func); //创建线程对象t
13 t.join(); //将子线程加入程序执行
14 cout << "主线程工作结束" << endl;
15 return 0;
16 }
例10-10运行结果如图10-13所示。
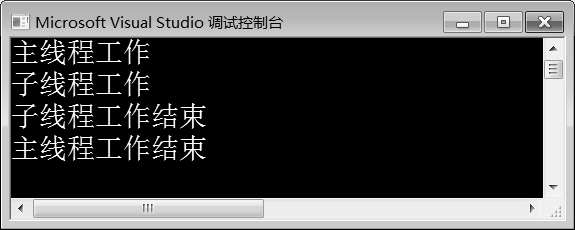
图10-13 例10-10运行结果
在例10-10中,第4~8行代码定义了函数func()。第12行代码创建线程对象t,传入func()函数名作为参数,即创建一个子线程去执行func()函数的功能。第13行代码调用join()函数阻塞主线程。由图10-13可知,主线程等待子线程工作结束之后才结束工作。
在C++多线程中,线程对象与线程是相互关联的,线程对象出了作用域之后就会被析构,如果此时线程函数还未执行完,程序就会发生错误,因此需要保证线程函数的生命周期在线程对象生命周期之内。一般通过调用thread中定义的join()函数阻塞主线程,等待子线程结束,或者调用thread中的detach()函数将线程与线程对象进行分离,让线程在后台执行,这样即使线程对象生命周期结束,线程也不会受到影响。例如,在例10-10中,将join()函数替换为detach()函数,将线程对象与线程分离,让线程在后台运行,再次运行程序,运行结果就可能发生变化。即使m ain()函数(主线程)结束,子线程对象t生命周期结束,子线程依然会在后台将func()函数执行完毕。
C++11标准定义了this_thread命名空间,该空间提供了一组获取当前线程信息的函数,分别如下所示。
(1)get_id()函数:获取当前线程id。
(2)yeild()函数:放弃当前线程的执行权。操作系统会调度其他线程执行未用完的时间片,当时间片用完之后,当前线程再与其他线程一起竞争CPU资源。
(3)sleep_until()函数:让当前线程休眠到某个时间点。
(4)sleep_for()函数:让当前线程休眠一段时间。
在并行编程中,为避免多线程对共享资源的竞争导致程序错误,线程会对共享资源进行保护。通常的做法是对共享资源上锁,当线程修改共享资源时,会获取锁将共享资源锁上,在操作完成之后再进行解锁。加锁之后,共享资源只能被当前线程操作,其他线程只能等待当前线程解锁退出之后再获取资源。为此,C++11标准提供了互斥锁mutex,用于为共享资源加锁,让多个线程互斥访问共享资源。
mutex是一个类模板,定义在mutex标准库中,使用时要包含mutex头文件。mutex类模板定义了三个常用的成员函数:lock()函数、unlock()函数和try_lock()函数,用于实现上锁、解锁功能。下面分别介绍这三个函数。
(1)lock()函数:用于给共享资源上锁。如果共享资源已经被其他线程上锁,则当前线程被阻塞;如果共享资源已经被当前线程上锁,则产生死锁。
(2)unlock()函数:用于给共享资源解锁,释放当前线程对共享资源的所有权。
(3)try_lock()函数:也用于给共享资源上锁,但它是尝试上锁,如果共享资源已经被其他线程上锁,try_lock()函数返回false,当前线程并不会被阻塞,而是继续执行其他任务;如果共享资源已经被当前线程上锁,则产生死锁。
下面通过案例演示C++11标准中mutex的上锁、解锁的过程,如例10-11所示。
例10-11 mutex.cpp
1 #include<iostream>
2 #include<thread>
3 #include<mutex>
4 using namespace std;
5 int num = 0; //定义全局变量num
6 mutex mtx; //定义互斥锁mtx
7 void func()
8 {
9 mtx.lock(); //上锁
10 cout << "线程id: " << this_thread::get_id() << endl; //获取当前线程id
11 num++;
12 cout << "counter:" << num << endl;
13 mtx.unlock(); //解锁
14 }
15 int main()
16 {
17 thread ths[3]; //定义线程数组
18 for(int i = 0; i < 3; i++)
19 ths[i] = thread(func); //分配线程任务
20 for(auto& th : ths)
21 th.join(); //将线程加入程序
22 cout << "主线程工作结束" << endl;
23 return 0;
24 }
例10-11运行结果如图10-14所示。
在例10-11中,第5行代码定义了一个全局变量num,初始值为0;第6行代码定义了互斥锁mtx。第7~14行代码定义了函数func(),在func()函数内部,通过对象mtx调用lock()函数,为后面的代码上锁;第13行代码通过对象mtx调用unlock()函数解锁。当某个线程获取互斥锁mtx时,该线程会为第10~12行代码上锁,即拥有了func()函数的所有权,在解锁之前,其他线程不能执行func()函数。第17行代码定义了一个大小为3的线程数组ths,第18~19行代码通过for循环为每个线程分配任务,即让线程执行func()函数;第20~21行代码通过for循环调用join()函数,将线程加入执行程序,并阻塞当前线程(主线程)。
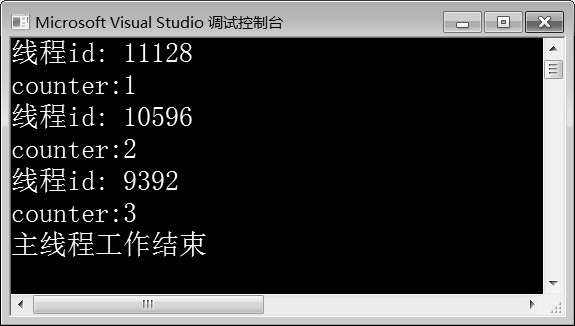
图10-14 例10-11运行结果
由图10-14可知,首先线程“11128”获取了互斥锁mtx,获得了func()函数的执行权,输出counter的值为1,之后解锁;然后线程“10596”获取了互斥锁mtx,获得了func()函数的执行权,输出counter值为2,之后解锁;最后线程“9392”获取了互斥锁m tx,获得了func()函数的执行权,输出counter值为3,之后解锁。
如果注释掉第9行和第13行代码,即不给func()函数中的操作上锁,则三个线程会同时执行func()函数,输出的结果就会超出预期。例如,连续输出三个线程id,或者先输出counter值为3,再输出counter值为1。
如果修改例10-11,调用try_lock()函数为func()函数上锁,示例代码如下所示:
void func()
{
if (mtx.try_lock()) //调用try_lock()函数加锁
{
cout << "线程id: " << this_thread::get_id() << endl;
num++;
cout << "counter:" << num << endl;
mtx.unlock();
}
}
再次运行程序,只有一个线程执行func()函数。当某个线程获取了互斥锁mtx,就会为func()函数上锁,获得func()函数的执行权。另外两个线程调用try_lock()函数尝试上锁时,发现func()函数已经被其他线程上锁,这两个线程并没有被阻塞,而是继续执行其他任务(本案例中线程执行结束)。因此,最终只有一个线程执行func()函数。
在10.4.2节我们学习了互斥锁mutex,通过mutex的成员函数为共享资源上锁、解锁,能够保证共享资源的安全性。但是,通过mutex上锁之后必须要手动解锁,如果忘记解锁,当前线程会一直拥有共享资源的所有权,其他线程不得访问共享资源,造成程序错误。此外,如果程序抛出了异常,mutex对象无法正确地析构,导致已经被上锁的共享资源无法解锁。
为此,C++11标准提供了RAII技术的类模板:lock_guard和unique_lock。lock_guard和unique_lock可以管理mutex对象,自动为共享资源上锁、解锁,不需要程序设计者手动调用mutex的lock()函数和unlock()函数。即使程序抛出异常,lock_guard和unique_lock也能保证mutex对象正确解锁,在简化代码的同时,也保证了程序在异常情况下的安全性。下面分别介绍lock_guard和unique_lock。
1.lock_guard
lock_guard可以管理一个mutex对象,在创建lock_guard对象时,传入mutex对象作为参数。在lock_guard对象生命周期内,它所管理的mutex对象一直处于上锁状态;lock_guard对象生命周期结束之后,它所管理的mutex对象也会被解锁。下面修改例10-11来演示lock_guard的使用,如例10-12所示。
例10-12 lock_guard.cpp
1 #include<iostream>
2 #include<thread>
3 #include<mutex>
4 using namespace std;
5 int num = 0; //定义全局变量num
6 mutex mtx; //定义互斥锁mtx
7 void func()
8 {
9 lock_guard<mutex> locker(mtx); //创建lock_guard对象locker
10 cout << "线程id: " << this_thread::get_id() << endl; //获取当前线程id
11 num++;
12 cout << "counter:" << num << endl;
13 }
14 int main()
15 {
16 thread ths[3]; //定义线程数组
17 for (int i = 0; i < 3; i++)
18 ths[i] = thread(func); //分配线程任务
19 for (auto& th : ths)
20 th.join(); //将线程加入程序
21 cout << "主线程工作结束" << endl;
22 return 0;
23 }
例10-12运行结果如图10-15所示。
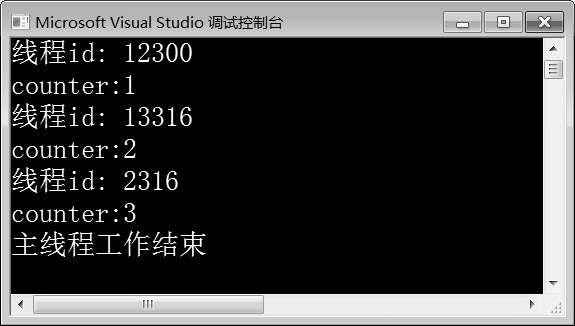
图10-15 例10-12运行结果
在例10-12中,第9行代码创建了lock_guard对象locker,传入互斥锁mtx作为参数,即对象locker管理互斥锁mtx。当线程执行func()函数时,locker会自动完成对func()函数的上锁、解锁功能。由图10-15可知,程序运行时,三个线程依旧是互斥执行func()函数。
需要注意的是,lock_guard对象只是简化了mutex对象的上锁、解锁过程,但它并不负责mutex对象的生命周期。在例10-12中,当func()函数执行结束时,lock_guard对象locker析构,mutex对象mtx自动解锁,线程释放func()函数的所有权,但对象mtx的生命周期并没有结束。
2.unique_lock
lock_guard只定义了构造函数和析构函数,没有定义其他成员函数,因此它的灵活性太低。为了提高锁的灵活性,C++11标准提供了另外一个RAII技术的类模板unique_lock。unique_lock与lock_guard相似,都可以很方便地为共享资源上锁、解锁,但unique_lock提供了更多的成员函数,它有多个重载的构造函数,而且unique_lock对象支持移动构造和移动赋值。需要注意的是,unique_lock对象不支持拷贝和赋值。
下面简单介绍几个常用的成员函数。
(1)lock()函数:为共享资源上锁,如果共享资源已经被其他线程上锁,则当前线程被阻塞;如果共享资源已经被当前线程上锁,则产生死锁。
(2)try_lock()函数:尝试上锁,如果共享资源已经被其他线程上锁,该函数返回false,当前线程继续其他任务;如果共享资源已经被当前线程上锁,则产生死锁。
(3)try_lock_for()函数:尝试在某个时间段内获取互斥锁,为共享资源上锁,如果在时间结束之前一直未获取互斥锁,则线程会一直处于阻塞状态。
(4)try_lock_until()函数:尝试在某个时间点之前获取互斥锁,为共享资源上锁,如果到达时间点之前一直未获取互斥锁,则线程会一直处于阻塞状态。
(5)unlock()函数:解锁。
正是因为提供了更多的成员函数,unique_lock才能够更灵活地实现上锁和解锁控制,例如,转让mutex对象所有权(移动赋值)、在线程等待时期解锁等。但是,更灵活的代价就是空间开销也更大,运行效率相对较低。在编程过程中,如果只是为了保证数据同步,那么lock_guard完全能够满足使用需求。如果除了同步,还需要结合条件变量进行线程阻塞,则要选择unique_lock。
RAII(Resource Acquisition Is Initialization,资源获取初始化)是C++语言管理资源、避免内存泄漏的一个常用技术。RAII技术利用C++创建的对象最终被销毁的原则,在创建对象时获取对应的资源,在对象生命周期内控制对资源的访问,使资源始终有效。当对象生命周期结束后,释放资源。
在多线程编程中,多个线程可能会因为竞争资源而导致死锁,一旦产生死锁,程序将无法继续运行。为了解决死锁问题,C++11标准引入了条件变量condition_variable类模板,用于实现线程间通信,避免产生死锁。
condition_variable类模板定义了很多成员函数,用于实现进程通信的功能,下面介绍几个常用的成员函数。
(1)wait()函数:会阻塞当前线程,直到其他线程调用唤醒函数将线程唤醒。当线程被阻塞时,wait()函数会释放互斥锁,使得被阻塞在互斥锁上的其他线程能够获取互斥锁以继续执行代码。一旦当前线程被唤醒,它就会重新夺回互斥锁。wait()函数有两种重载形式,函数声明分别如下所示:
void wait(unique_lock<mutex>& lck); template<class Predicate> void wait(unique_lock<mutex>& lck, Predicate pred
第一种重载形式称为无条件阻塞,它以mutex对象作为参数,在调用wait()函数阻塞当前线程时,wait()函数会在内部自动通过mutex对象调用unlock()函数解锁,使得阻塞在互斥锁上的其他线程恢复执行。
第二种重载形式称为有条件阻塞,它有两个参数,第一个参数是mutex对象,第二个参数是一个条件,只有当条件为false时,调用wait()函数才能阻塞当前线程;在收到其他线程的通知后,只有当条件为true时,当前线程才能被唤醒。
(2)wait_for()函数:也用于阻塞当前线程,但它可以指定一个时间段,当收到通知或超过时间段时,线程就会被唤醒。wait_for()函数声明如下所示:
cv_status wait_for(unique_lock<mutex>& lck,
const chrono :: duration<Rep,Period>& rel_time);
在上述函数声明中,wait_for()函数第一个参数为unique_lock对象,第二个参数为设置的时间段。函数返回值为cv_status类型,cv_status是C++11标准定义的枚举类型,它有两个枚举值:no-tim eout和tim eout。no-tim eout表示没有超时,即在规定的时间段内,当前线程收到了通知;tim eout表示超时。
(3)wait_until()函数:可以指定一个时间点,当收到通知或超过时间点时,线程就会被唤醒。wait_until()函数声明如下所示:
cv_status wait_until(unique_lock<mutex>& lck,
const chrono::time_point<Clock,Duration>& abs_tim
在上述函数声明中,wait_until()函数第一个参数为unique_lock对象,第二个参数为设置的时间点。函数返回值为cv_status类型。
(4)notify_one()函数:用于唤醒某个被阻塞的线程。如果当前没有被阻塞的线程,则该函数什么也不做;如果有多个被阻塞的线程,则唤醒哪一个线程是随机的。notify_one()函数声明如下所示:
void notify_one() noexcept;
在上述函数声明中,notify_one()函数没有参数,没有返回值,并且不抛出任何异常。
(5)notify_all()函数:用于唤醒所有被阻塞的线程。如果当前没有被阻塞的线程,则该函数什么也不做。notify_all()函数声明如下所示:
void notify_all() noexcept;
条件变量用于实现线程间通信,防止死锁发生,为了实现更灵活的上锁、解锁控制,条件变量通常与unique_lock结合使用。下面通过案例演示条件变量在并行编程中的使用,如例10-13所示。
例10-13 condition_variable.cpp
1 #include<iostream>
2 #include<chrono>
3 #include<thread>
4 #include<mutex>
5 #include<queue>
6 using namespace std;
7 queue<int> products; //创建队列容器products
8 mutex mtx; //创建互斥锁mtx
9 condition_variable cvar; //定义条件变量cvar
10 bool done = false; //定义变量done,表示产品是否生产完毕
11 bool notified = false; //定义变量notified,表示是否唤醒线程
12 void produce() //生产函数
13 {
14 for(int i = 1; i <= 5; i++)
15 {
16 //让当前线程休眠2 s
17 this_thread::sleep_for(chrono::seconds(2));
18 //创建unique_lock对象locker,获取互斥锁mtx
19 unique_lock<mutex> locker(mtx);
20 //生产产品,并将产品存放到products容器中
21 cout << "生产产品" << i << " ";
22 products.push(i);
23 //将notified值设置为true
24 notified = true;
25 //唤醒一个线程
26 cvar.notify_one();
27 }
28 done = true; //生产完毕,设置done的值为true
29 cvar.notify_one(); //唤醒一个线程
30 }
31 void consume() //定义消费函数
32 {
33 //创建unique_lock对象locker,获取互斥锁mtx
34 unique_lock<mutex> locker(mtx);
35 while(!done) //判断产品是否生产完毕
36 {
37 while(!notified) //避免虚假唤醒
38 {
39 cvar.wait(locker); //继续阻塞
40 }
41 while(!products.empty()) //如果products容器不为空
42 {
43 //消费产品
44 cout << "消费产品" << products.front() << endl;
45 products.pop();
46 }
47 notified = false; //消费完之后,将notified的值设置为false
48 }
49 }
50 int main()
51 {
52 thread producer(produce); //创建生产线程
53 thread consumer(consume); //创建消费线程
54 producer.join();
55 consumer.join();
56 return 0;
57 }
例10-13运行结果如图10-16所示。
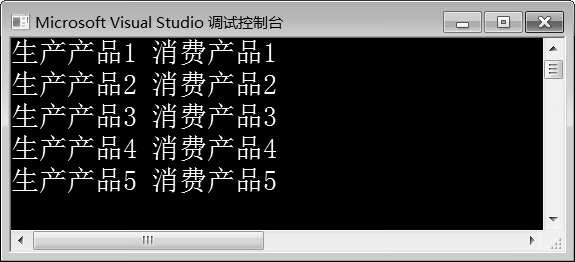
图10-16 例10-13运行结果
在例10-13中,第7~11行代码分别定义了queue<int>类型的容器products、互斥锁mtx、条件变量cvar以及bool类型的变量done、notified。第12~30行代码定义了生产函数produce(),在该函数内部通过for循环生产产品。第17行代码先调用sleep_for()让当前线程休眠2 s。第19行代码创建unique_lock对象locker,获取互斥锁mtx。第21~22行代码生产产品i,并调用push()函数将i存储到proudcts队列容器中。第24~26行代码,每生产完一个产品,就将notified的值设置为true,然后通过条件变量cvar调用notified_one()函数唤醒一个线程。
第31~49行代码定义了消费函数consum e()。第34行代码创建了unique_lock对象locker,获取互斥锁mtx。第35~48行代码通过while(!done)循环判断生产是否完毕,在该while循环中消费产品。第37~40行代码通过判断notified的值是否为true,来判断是否唤醒消费线程,避免虚假唤醒。第41~47行代码判断容器products是否为空,如果不为空,就消费产品;当产品消费完之后,即容器products为空,则设置notified的值为false,将消费线程阻塞。
第52~55行代码创建生产线程producer和消费线程consum er,分别调用生产函数produce()和消费函数consum e()。
由图10-16可知,程序运行结果为:生产线程每生产一个产品,消费线程就消费一个产品。生产线程每生产完一个产品,就会将notified的值设置为true,然后通过条件变量cvar调用notify_one()函数唤醒消费线程消费产品。
在并行编程中,共享资源同时只能有一个线程进行操作,这些最小的不可并行执行的操作称为原子操作。原子操作都是通过上锁、解锁实现的,虽然使用lock_guard和unique_lock简化了上锁、解锁过程,但是由于上锁、解锁过程涉及许多对象的创建和析构,内存开销太大。为了减少多线程的内存开销,提高程序运行效率,C++11标准提供了原子类型atom ic。atom ic是一个类模板,它可以接受任意类型作为模板参数。创建的atom ic对象称为原子变量,使用原子变量就不需要互斥锁保护该变量进行的操作了。
在使用原子类型之前来看一个案例,如例10-14所示。
例10-14 lock.cpp
1 #include<iostream>
2 #include<thread>
3 #include<mutex>
4 using namespace std;
5 mutex mtx; //定义互斥锁
6 int num = 0; //定义全局变量num
7 void func()
8 {
9 lock_guard<mutex> locker(mtx); //加锁
10 for(int i = 0; i < 100000; i++)
11 {
12 num++; //通过for循环修改num的值
13 }
14 cout << "func()num: " << num << endl;
15 }
16 int main()
17 {
18 thread t1(func); //创建线程t1执行func()函数
19 thread t2(func); //创建线程t2执行func()函数
20 t1.join();
21 t2.join();
22 cout << "main()num: " << num << endl;
23 return 0;
24 }
例10-14运行结果如图10-17所示。

图10-17 例10-14运行结果
在例10-14中,第5~6行代码定义了互斥锁mtx和全局变量num。第7~15行代码定义了func()函数,在该函数内部,通过for循环修改num的值,循环结束后输出num的值,并且使用lock_guard为func()函数上锁。第18~19行代码创建两个线程t1和t2执行func()函数,两个线程执行结束后输出num的值。m ain()函数输出num值为200000。
在程序执行过程中,一个线程先获取互斥锁,执行func()函数,修改num的值并输出。由图10-17可知,第一次func()函数输出num值为100000。func()函数执行完毕之后,线程释放锁,接着另一个线程获取互斥锁,执行func()函数,再次修改num的值并输出。由图10-17可知,第二次func()函数输出num值为200000。func()函数执行完毕之后,线程释放锁。两个线程执行完毕之后,返回m ain()函数,主线程输出num的值。由图10-17可知,m ain()函数输出num值为200000。
如果使用原子类型定义全局变量num,在修改num的值时,就不需要再给操作代码上锁,也能实现多个线程的互斥访问,保证某一时刻只有一个线程修改num的值。下面修改例10-14,使用原子类型定义全局变量num,如例10-15所示。
例10-15 atomic.cpp
1 #include<iostream>
2 #include<thread>
3 #include<atomic>
4 using namespace std;
5 atomic<int> num = 0;
6 void func()
7 {
8 for(int i = 0; i < 100000; i++)
9 {
10 num++;
11 }
12 cout << "func()num: " << num << endl;
13 }
14 int main()
15 {
16 thread t1(func);
17 thread t2(func);
18 t1.join();
19 t2.join();
20 cout << "main()num: " << num << endl;
21 return 0;
22 }
例10-15运行结果如图10-18所示。
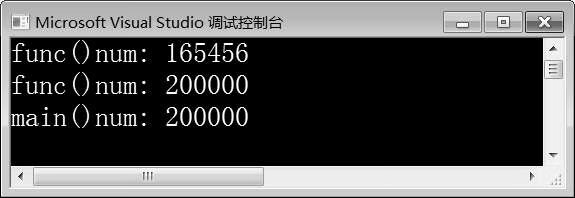
图10-18 例10-15运行结果
例10-15是对例10-14的修改,第5行代码将num定义为全局的原子变量,在func()函数中修改num的值时未上锁。由图10-18可知,第一次func()函数输出的num值并不是100000,但是第二次func()函数输出的num值与m ain()函数输出的最终的num值都为200000,num最终结果是正确的。
例10-15程序运行过程中,线程t1与线程t2交叉执行func()函数,修改num的值,并不是一个线程先执行完成所有for循环。输出num值之后,另一个线程才能去执行for循环进行修改。因此,第一次输出的num值并不是100000,但最终结果是正确的。原子变量只保证“num++”是原子操作(第10行代码),使得原子操作颗粒度更细(例10-14中,原子操作为第10~14行代码)。它相当于是在“num++”操作上上了锁,示例代码如下所示:
int num=0;
for(int i = 0; i < 100000; i++)
{
lock_guard<mutex> locker(mtx); //加锁
num++;
}
上述代码中,在for循环内部上了互斥锁,循环结束,locker对象失效。如果有多个线程修改num,则多个线程会交叉修改num的值。但是,相比于上锁,原子类型实现的是无锁编程,内存开销小,程序的运行效率会得到极大提高,并且代码更简洁。
除了简化代码、提高编程效率,C++11标准还针对一些编程细节做了优化。例如,提供对原生字符串的支持,支持Unicode编码等。本节将针对这些扩展性的C++11标准进行介绍。
在传统C++编程中,编写一个包含特殊字符的字符串是一件非常麻烦的事情。例如,输出一个包含HTM L文本的字符串,示例代码如下所示:
string s = "\
<html>\
< head >\
<title></title>\
<script type = \"text/javascript\">\
if(null)\
alert(\"null为真\");\
else\
alert(\"null为假\");\
</script>\
</head>\
<body>\
</body>\
</html>\
";
在上述代码中,字符串s包含HTM L文本,在每次换行处和双引号前都需要添加转义字符,而且其输出格式也无法达到预期的整齐。为此,C++11标准提供了对原生字符串的支持。所谓原生字符串,就是“所见即所得”,不需要在字符串中添加转义字符或其他的格式控制字符调整字符串的格式。
原生字符串的定义很简单,语法格式如下所示:
R"(字符串)";
在上述格式中,字母R表示这是一个原生字符串,后面是一对双引号,双引号中有一对小括号,字符串就放在小括号中。这样定义的字符串,字符串中所有的字符都保持最原始的字面意思。重新定义包含HTM L文本的字符串s为原生字符串,示例代码如下所示:
string s = R"(
<html>
<head>
<title></title>
<script type="text/javascript">
if(null)
alert("null为真");
else
alert("null为假");
</script>
</head>
<body>
</body>
</html>
)
在上述代码中,字符串s为原生字符串,不必在换行和双引号前再添加转义字符,而且在输出时,输出格式就是字符串所定义的格式。
需要注意的是,在原生字符串中,所有具有特殊意义的字符都不再起作用。
为了支持Unicode编码,C++11标准提供了两个新的内置数据类型,以存储不同编码长度的Unicode数据。
(1)char16_t:用于存储UTF-16编码的Unicode数据,所占内存大小为2字节。
(2)char32_t:用于存储UTF-32编码的Unicode数据,所占内存大小为4字节。
对于UTF-8编码的Unicode数据,C++11标准仍然采用8字节大小的字符数组进行存储。为了区分不同编码方式的Unicode数据,C++11标准还定义了一些前缀,用于告知编译器按照什么样的编码方式编译这些数据,分别如下所示:
再加上wchar_t类型数据的前缀“L”,以及普通字符串字面常量,C++11一共有五种声明字符串的方式。下面通过案例演示C++11标准中字符串的声明方式,如例10-16所示。
例10-16 unicode.cpp
1 #include<iostream>
2 using namespace std;
3 int main()
4 {
5 //普通字符数组
6 char arr1[] = "你好,祖国";
7 //wchar_t类型数组
8 wchar_t arr2[] = L"中国";
9 //UTF-8编码方式
10 char arr3[] = u8"你好";
11 //UTF-16编码方式
12 char16_t arr4[] = u"hello";
13 //UTF-32编码方式
14 char32_t arr5[] = U"hello 和\u4f60\u597d\u554a";
15 cout << "arr1:" << arr1 << endl;
16 cout << "arr2:" << arr2 << endl;
17 cout << "arr3:" << arr3 << endl;
18 cout << "arr4:" << arr4 << endl;
19 cout << "arr5:" << arr5 << endl;
20 return 0;
21 }
例10-16运行结果如图10-19所示。
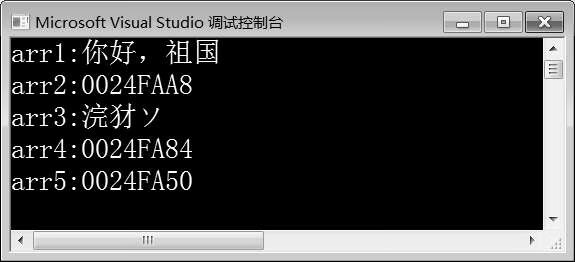
图10-19 例10-16运行结果
在例10-16中,第6~14行代码分别定义普通字符串、wchar_t类型的字符串、UTF-8编码方式的字符串、UTF-16编码方式的字符串和UTF-32编码方式的字符串。第15~19行代码分别输出这5个字符串。由图10-19可知,字符串arr1正常输出,字符串arr3输出的是乱码,而字符串arr2、arr4和arr5则输出的是一个地址,并没有输出预期的字符串。这是因为Unicode数据的输出显示受到多种因素的影响,例如,源文件的保存方式,文件编辑器采用的数据编码方式,编译器是否支持Unicode编码方式,在输出时输出设备是否支持Unicode编码方式等。因此,除了语言层面的支持,Unicode数据的输出与使用还受到编译器、输出环境、代码编辑器等因素的影响,这些影响因素都达到统一才能正确输出Unicode编码的字符串。
C++11标准提供了很多新的标准库,使得程序编写更便捷,下面简单介绍几个常用的新增标准库。
1.tuple
标准库tuple中定义了tuple类模板,tuple类模板可以存储任意多个不同类型的值。示例代码如下所示:
tuple<int, double, string > t= {10, 3.6, "hello"};
上述代码定义了一个tuple对象t,对象t中存储了三个值,分别是int类型的10、double类型的3.6和string类型的“hello”。若要获取tuple对象中的元素,可以调用std提供的函数模板get()。在调用get()函数获取tuple对象元素时,既可以通过索引获取,也可以通过类型获取,示例代码如下所示:
//通过索引获取 get<0>(t); get<1>(t); get<2>(t); //通过数据类型获取 get<int>(t); get<double>(t); get<string>(t)
tuple还有其他很多操作,有兴趣的读者可以查阅C++标准库进行学习。
2.chrono
chrono是C++11标准定义的时间库,chrono时间库的所有实现都在std::chrono命名空间中。chrono时间库定义了三个常用的类模板,分别介绍如下。
(1)duration:表示一段时间,如1小时、30秒等。chrono预定义了六个duration类模板的实例化对象,分别如下。
(2)tim e_point:表示一个具体的时间点,如生日、飞机起飞时间等。
(3)system_clock:表示当前系统时钟,它提供了now()函数用于获取系统当前时间。
下面通过案例演示chrono时间库的使用,如例10-17所示。
例10-17 chrono.cpp
1 #define _CRT_SECURE_NO_WARNINGS
2 #include<iostream>
3 #include<chrono>
4 #include<ratio>
5 using namespace std;
6 int main()
7 {
8 //定义duration对象oneday,表示一天
9 chrono::duration<int, ratio<60 * 60 * 24>> oneday(1);
10 //获取系统当前时间
11 chrono::system_clock::time_point today = chrono::system_clock::now();
12 //计算明天的时间
13 chrono::system_clock::time_point tomorrow = today + oneday;
14 time_t t; //创建time_t时间对象t
15 //将对象today中的时间转换之后存储到时间对象t中
16 t = chrono::system_clock::to_time_t(today);
17 cout << "today:" << ctime(&t);
18 //将对象tomorrow中的时间转换之后存储到时间对象t中
19 t= chrono::system_clock::to_time_t(tomorrow);
20 cout << "tomorrow:" << ctime(&t);
21 return 0;
22 }
例10-17的运行结果如图10-20所示。
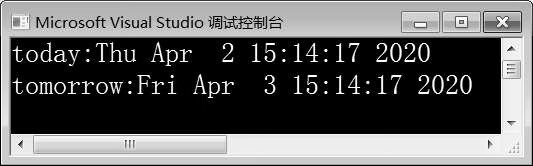
图10-20 例10-17运行结果
在例10-17中,第9行代码创建了duration对象oneday,用于表示一天的时间。第11行代码创建system_clock对象today,并调用now()函数获取系统当前时间,存储到对象today中。第13行代码创建system_clock对象tom orrow,tom orrow的值为对象today和oneday相加的结果。第14~17行创建tim e_t对象t,将对象today中保存的时间转换之后存储到对象t中,然后输出时间。第19~20行代码将对象tom orrow中保存的时间转换之后存储到对象t中,然后输出时间。由图10-20可知,程序正确输出了系统当前时间和对象tom orrow的时间。
3.regex
regex标准库提供了对正则表达式的支持。regex标准库提供了regex类模板,在构造regex对象时,以一个正则表达式作为参数。为了处理正则表达式操作,C++11标准还提供了很多函数,下面简单介绍两个比较常用的匹配函数。
(1)regex_m atch()函数:将字符串与正则表达式匹配,匹配成功返回true,匹配失败返回false。需要注意的是,regex_m atch()函数在匹配的时候,需要整个字符串匹配成功才能返回true。
(2)regex_search()函数:在字符串中查找与正则表达式匹配的子串,查找成功返回true,查找失败返回false。regex_search()函数只要求字符串包含符合正则表达式的子串即可。
regex_m atch()函数和regex_search()函数用法示例代码如下所示:
cout << regex_match("123", regex("\\d")) << endl; //返回false
cout << regex_search("123", regex("\\d")) << endl; //返回true
cout << regex_match("1", regex("\\d")) << endl; //返回true
在上述代码中,正则表达式“\d”表示匹配任意一个数字。第一行代码调用regex_m atch()函数将字符串“123”与“\d”匹配,由于字符串“123”中有三个数字,整个字符串与正则表达式匹配失败,因此返回false。第二行代码调用regex_search()函数从字符串“123”中匹配任意一个数字,由于regex_search()函数匹配到符合要求的子串,因此返回true。第三行代码调用regex_m atch()函数将字符串“1”与“\d”匹配,整个字符串与正则表达式匹配成功,因此返回true。
在处理正则表达式时,更多时候希望将匹配结果保存起来以便于其他操作,regex标准库提供了sm atch容器用于存储正则表达式匹配结果。sm atch容器在存储正则表达式的匹配结果时,第一个元素是完整的字符串序列,第二个元素是匹配的第一个子串,第三个元素是匹配的第二个子串,……下面通过案例演示sm atch容器的用法,如例10-18所示。
例10-18 regex.cpp
1 #include<iostream>
2 #include<regex>
3 using namespace std;
4 int main()
5 {
6 string s = "hello,China"; //定义字符串
7 regex r("(.{5}),(\\w{5})"); //正则表达式
8 smatch sm; //创建smatch容器对象sm
9 regex_search(s, sm, r); //调用regex_search()函数匹配
10 //for循环遍历容器sm,输出匹配的结果
11 for(int i = 0; i < sm.size(); i++)
12 cout << sm[i] << endl;
13 return 0;
14 }
例10-18运行结果如图10-21所示。
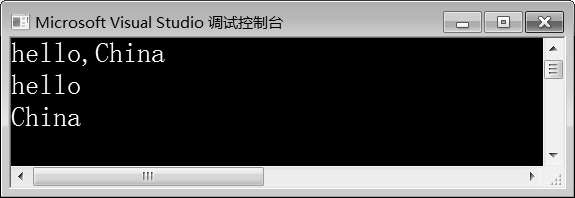
图10-21 例10-18运行结果
在例10-18中,第6行代码定义了字符串s。第7行代码创建regex对象r,用于定义正则表达式,匹配任意5个字符(\n除外)、一个逗号再加任意5个字符而组成的字符串。第8行代码创建sm atch容器sm。第9行代码调用regex_search()函数,在字符串s中查找符合r模式的子串,并将结果存储到容器sm中。第11~12行代码通过for循环遍历输出容器sm中的元素。
由图10-21可知,容器sm中第一个参数是要匹配的完整的字符串序列;第二个元素为“hello”,即第一个匹配的子串;第三个元素为“China”,即第二个匹配的子串。
C++11标准新增了alignof和alignas两个运算符。alignof运算符用于获取结构体和类的内存对齐方式,即按照多少字节对齐。alignof用法的示例代码如下所示:
struct Obj
{
char ch;
int b;
double d;
};
class Student
{
private:
string name;
int num;
char sex;
};
cout << alignof(Obj) << endl; //结果为8
cout << alignof(Student) << endl; //结果为4
在上述代码中,首先定义了struct Obj结构体类型和学生类Student,然后使用alignof运算符分别获取struct Obj结构体类型和学生类Student的对齐字节。如果运行程序,会得出struct Obj结构体类型对齐字节为8,学生类Student的对齐字节为4。这是因为struct Obj结构体类型中最宽基本类型为double(8字节),学生类Student中最宽基本类型为int(4字节)。
alignas运算符也用于设置结构体和类的内存对齐方式,用法也很简单。需要注意的是,在设置结构体和类的对齐方式时,对齐字节数必须是2的幂次方,并且不能小于结构体和类中最宽基本类型所占内存字节数,即不能小于默认对齐字节数。alignas用法示例代码如下所示:
struct alignas(8) A //设置struct A的对齐方式为8字节
{
int num;
char ch;
};
cout << alignof(A) << endl; //结果为8
struct alignas(1) B //错误,对齐字节数小于默认对齐字节数
{
int num;
char ch;
};
struct alignas(6) C //错误,对齐字节数不是2的幂次方
{
int num;
char ch;
};
在上述代码中,首先定义了struct A结构体类型(默认对齐为4字节),使用alignas运算符设置struct A结构体类型对齐方式为8字节。然后定义了struct B结构体类型,使用alignas运算符设置其对齐方式为1字节,编译器会报错,因为1字节小于struct B结构体类型的默认对齐字节数(4字节)。最后定义了struct C结构体类型,使用alignas运算符设置struct C结构体类型对齐方式为6字节,编译器会报错,因为6字节不是2的幂次方。
本章主要介绍了C++11标准的一些常用新特性,这些新特性简化了代码编写,提高了编程效率,其中一些特性用法甚至改变了原有的编程习惯,让读者从一个更高的角度认识C++,提升了C++编程过程中读者认识问题、解决问题的能力。
一、填空题
1. 在类中禁止某个成员函数使用,可以在函数声明后添加___关键字。
2. 在lambda表达式中,捕获列表___表示捕获所有的局部变量。
3. 使用智能指针需要包含___头文件。
4.___函数可以将一个左值强制转换为右值引用。
5.C++11标准提供的函数包装器为___。
6. 创建一个子线程,如果使主线程等待子线程结束任务,则调用___函数。
7. 互斥锁mutex提供的上锁函数___是非阻塞的。
8.C++11标准中,表示原子类型的类模板为___。
二、判断题
1.auto关键字是C++11标准新增的关键字。( )
2. 可以使用decltype关键字推导出的类型定义新的变量。( )
3.lambda表达式没有函数体实现。( )
4.weak_ptr提供的成员函数lock()返回一个auto_ptr对象。( )
5. 代码int x=10;int&&a=x;可以编译通过。( )
6. 线程之间可以进行拷贝、复制操作。( )
7.lock_guard用于管理mutex对象,可以自动为共享资源上锁、解锁。( )
8. 在原生字符串中,所有具有特殊意义的字符都不再起作用。( )
三、选择题
1. 关于关键字auto与decltype,下列说法中错误的是( )。
A.auto关键字用于推导变量类型
B.decltype关键字用于推导变量类型
C.可以使用auto关键字推导出的类型定义新的变量
D.decltype关键字的参数表达式不能是具体的数据类型
2. 关于nullptr,下列说法中错误的是( )。
A.nullptr是一个void*类型的指针
B.nullptr是一个有类型的空指针常量
C.nullptr不能转换为非指针类型
D.nullptr能够消除字面常量0带来的二义性
3. 关于=default和=delete关键字,下列说法中错误的是( )(多选)。
A.在类的默认构造函数后面添加=default,表示让编译器生成该函数的默认版本
B.使用=default修饰的函数需要实现
C.使用=delete修饰的成员函数,在类外不可以被调用
D.=delete不可以修饰普通函数,只能修饰类的成员函数
4. 下列选项中,不属于C++11标准提供的智能指针的是( )。
A.unique_ptr
B.shared_ptr
C.auto_ptr
D.weak_ptr
5. 关于右值引用,下列语句中正确的是( )。
A.int&&a=100;
B.int a=10,b=9;int&&x=a-b;
C.int&&a=10+6;
D.int a=100;int&&b=a;
6. 关于移动构造函数,下列说法中错误的是( )。
A.移动构造函数提高了临时对象的效率问题
B.移动构造函数通过右值引用实现
C.移动构造函数要使用一个右值引用对象作为参数
D.移动构造函数的右值引用对象参数可以使用const修饰
7. 关于C++11多线程,下列说法中错误的是( )。
A.C++11标准通过thread类模板创建多线程
B.在创建线程对象时,可以为线程传入参数
C.线程对象之间可以拷贝、复制
D.detach()函数可以分离线程和线程对象
8. 关于mutex类模板的成员函数,属于非阻塞上锁函数的是( )。
A.lock()
B.try_lock()
C.unlock()
D.yield()
9. 下列选项中,属于C++11标准新增的时间库的是( )。
A.tuple
B.chrono
C.regex
D.thread
10. 关于lock_guard和unique_lock,下列说法中正确的是( )。
A.lock_guard和unique_lock可以管理mutex对象,自动为共享资源上锁、解锁
B.lock_gurad可以负责mutex对象的生命周期
C.lock_gurad不支持拷贝和赋值,但unique_lock对象支持拷贝和赋值
D.lock_gurad提供了多个成员函数,如lock()、try_lock()等,因此其使用更灵活
11. 下列模板中,表示条件变量的模板的是( )。
A.condition_variable
B.atom ic
C.mutex
D.unique_lock
四、简答题
1. 简述lambda表达式常用的捕获列表形式。
2. 简述智能指针unique_ptr与shared_ptr的实现机制。
3. 简述lock_guard与unique_lock的异同。
五、编程题
请编写程序实现以下功能:子线程执行5次任务,主线程执行10次任务,子线程执行5次任务……这样交替循环执行3次。