第14章 Kubernetes集群监控
创建Kubernetes集群并部署容器化应用只是第一步。一旦集群运行起来,我们需要确保集群一起都是正常的,所有必要组件就位并各司其职,有足够的资源满足应用的需求。Kubernetes是一个复杂系统,运维团队需要有一套工具帮助他们获知集群的实时状态,并为故障排查提供及时和准确的数据支持。
本章重点讨论Kubernetes常用的监控方案,下一章会讨论日志管理。
14.1 Weave Scope
Weave Scope是Docker和Kubernetes可视化监控工具。Scope提供了自上而下的集群基础设施和应用的完整视图,用户可以轻松对分布式的容器化应用进行实时监控和问题诊断。
14.1.1 安装Scope
安装Scope的方法很简单,执行如下命令:
kubectl apply --namespace kube-system -f "https://cloud.weave.works/k8s/scope.yaml?k8s-version=$(kubectl version | base64 | tr -d '\n')"
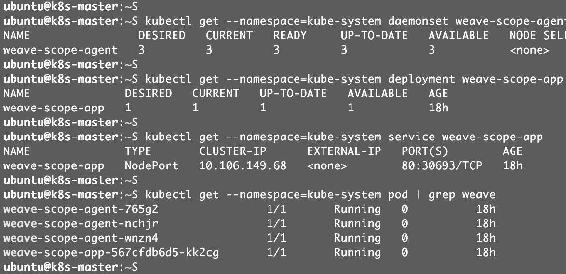
部署成功后,有如图14-1所示的相关组件。
图14-1
(1)DaemonSet weave-scope-agent,集群每个节点上都会运行的scope agent程序,负责收集数据。
(2)Deployment weave-scope-app,scope应用,从agent获取数据,通过Web UI展示并与用户交互。
(3)Service weave-scope-app,默认是ClusterIP类型,为了方便,已通过kubectl edit修改为NodePort。
14.1.2 使用Scope
浏览器访问http://192.168.56.106:30693/,Scope默认显示当前所有的Controller(Deployment、DaemonSet等),如图14-2所示。
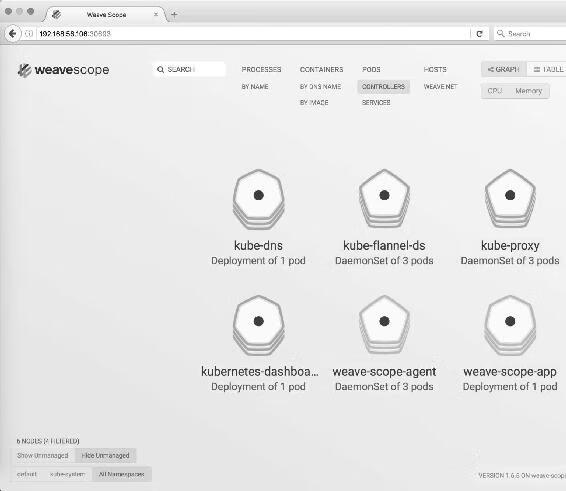
图14-2
1. 拓扑结构
Scope会自动构建应用和集群的逻辑拓扑,比如单击顶部PODS,会显示所有Pod以及Pod之间的依赖关系,如图14-3所示。
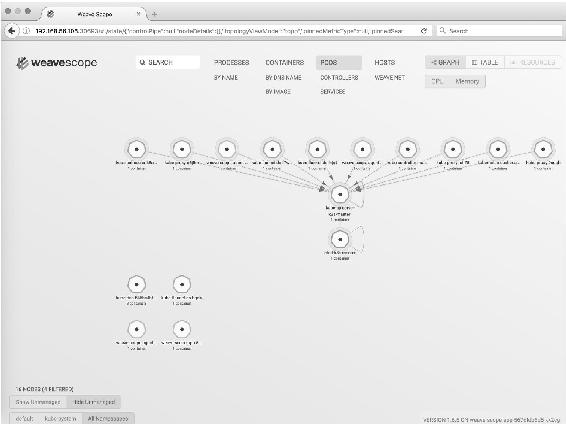
图14-3
单击HOSTS,会显示各个节点之间的关系,如图14-4所示。
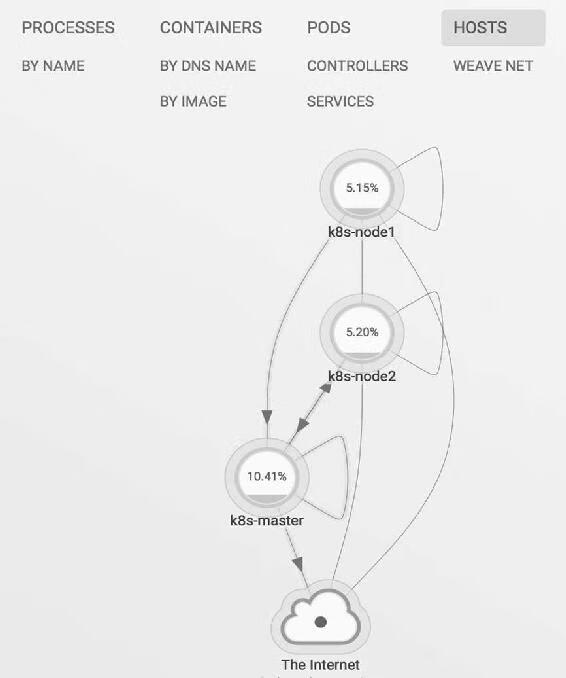
图14-4
2. 实时资源监控
可以在Scope中查看资源的CPU和内存使用情况,如图14-5所示。
图14-5
支持的资源有Host、Pod和Container,如图14-6、图14-7所示。
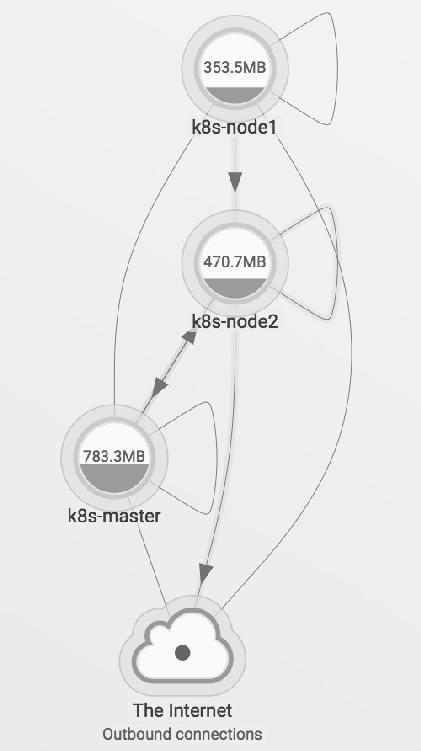
图14-6
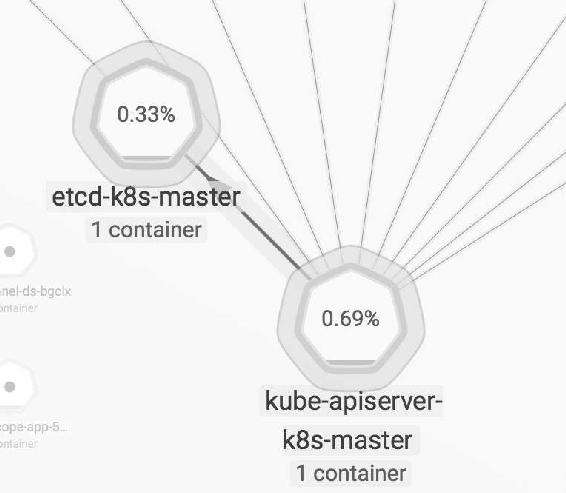
图14-7
3. 在线操作
Scope还提供了便捷的在线操作功能,比如选中某个Host,单击>_按钮可以直接在浏览器中打开节点的命令行终端,如图14-8所示。
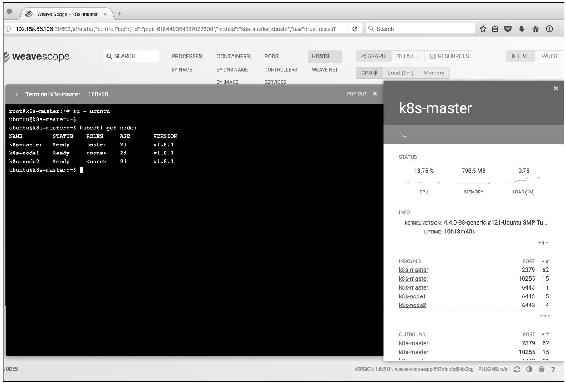
图14-8
单击Deployment的+可以执行Scale Up操作,如图14-9所示。
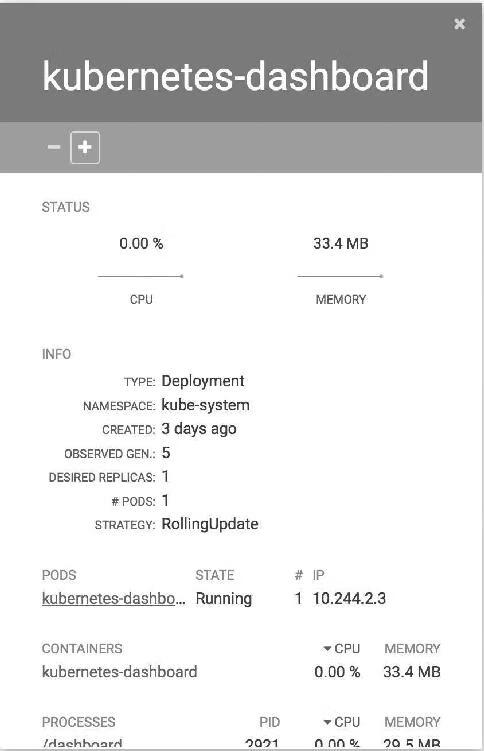
图14-9
查看Pod的日志,如图14-10所示。
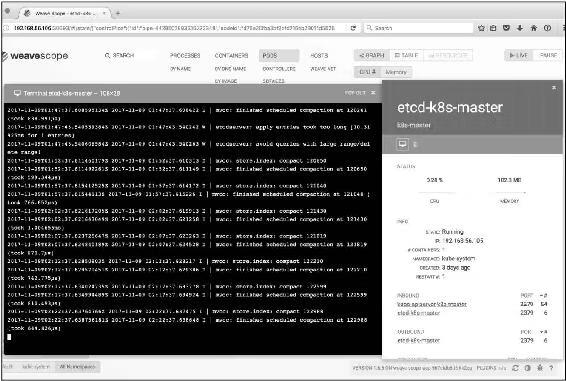
图14-10
可以查看attach、restart、stop容器,以及直接在Scope中排查问题,如图14-11所示。
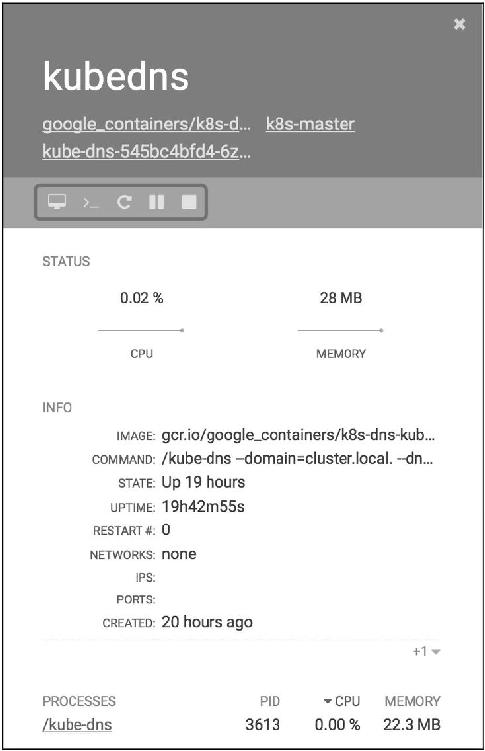
图14-11
4. 强大的搜索功能
Scope支持关键字搜索和定位资源,如图14-12所示。还可以进行条件搜索,比如查找和定位MEMORY大于100MB的Pod,如图14-13所示。
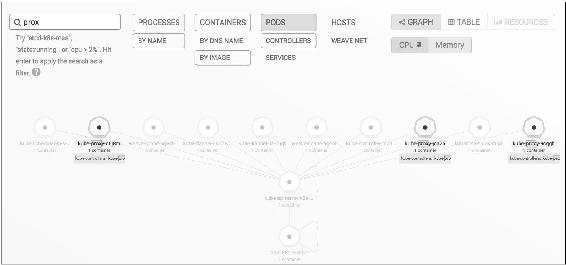
图14-12
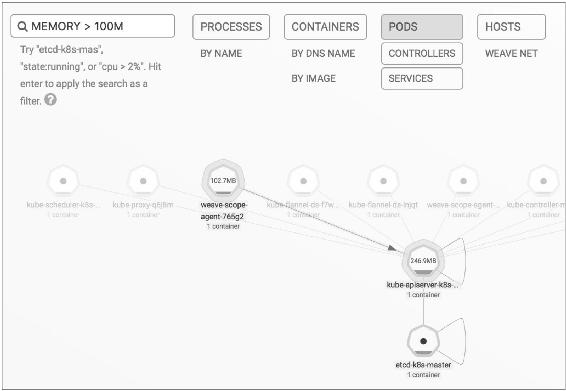
图14-13
Weave Scope界面极其友好,操作简洁流畅,更多功能留给大家去探索。
14.2 Heapster
Heapster是Kubernetes原生的集群监控方案。Heapster以Pod的形式运行,它会自动发现集群节点,从节点上的Kubelet获取监控数据。Kubelet则是从节点上的cAdvisor收集数据。
Heapster将数据按照Pod进行分组,将它们存储到预先配置的backend并进行可视化展示。Heapster当前支持的backend有InfluxDB(通过Grafana展示)、Google Cloud Monitoring等。Heapster的整体架构如图14-14所示。
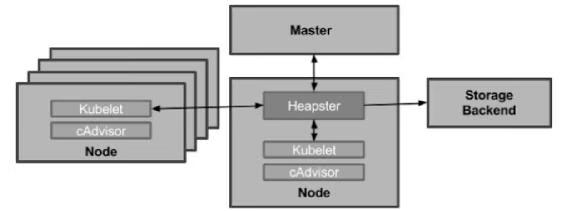
图14-14
下面我们将实践由Heapster、InfluxDB和Grafana组成的监控方案。Kubelet和cAdvisor是Kubernetes的自带组件,无须额外部署。
14.2.1 部署
Heapster本身是一个Kubernetes应用,部署方法很简单,运行如下命令:
git clone https://github.com/kubernetes/heapster.git
kubectl apply -f heapster/deploy/kube-config/influxdb/
kubectl apply -f heapster/deploy/kube-config/rbac/heapster-rbac.yaml
Heapster相关资源如图14-15所示。
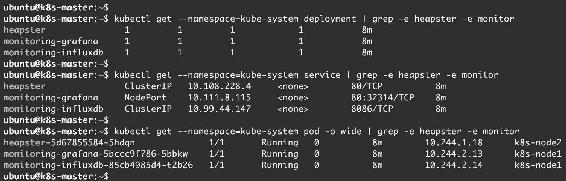
图14-15
为了便于访问,已通过kubectl edit将Service monitoring-grafana的类型修改为NodePort。
14.2.2 使用
浏览器打开Grafana的Web UI:http://192.168.56.105:32314/。
Heapster已经预先配置好了Grafana的DataSource和Dashboard,如图14-16所示。
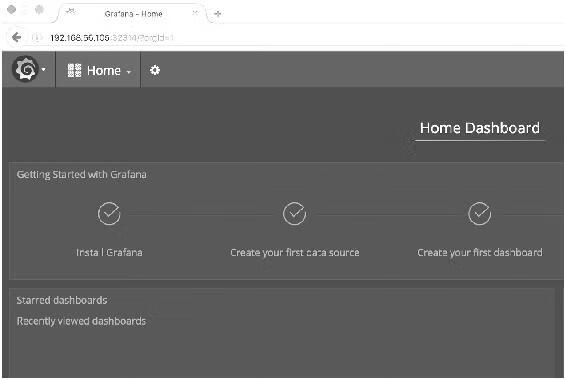
图14-16
单击左上角的Home菜单,可以看到预定义的Dashboard Cluster和Pods,如图14-17所示。
图14-17
单击Cluster,可以查看集群中节点的CPU、内存、网络和磁盘的使用情况,如图14-18所示。
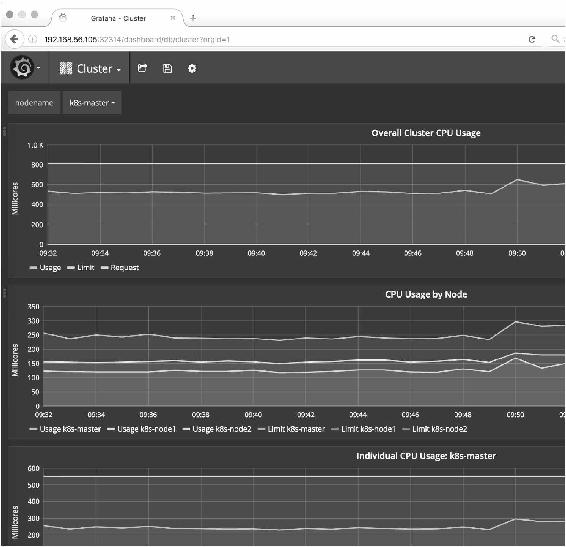
图14-18
在左上角可以切换查看不同节点的数据,如图14-19所示。
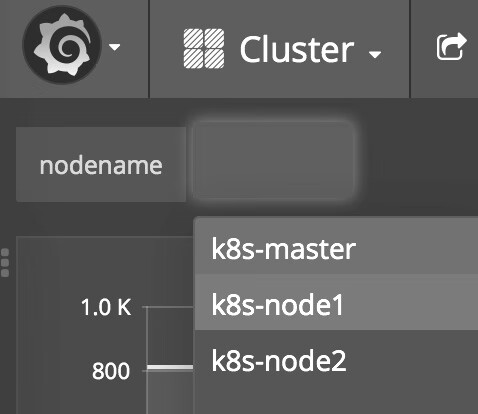
图14-19
切换到Pods Dashboard,可以查看Pod的监控数据,包括单个Pod的CPU、内存、网络和磁盘使用情况,如图14-20所示。
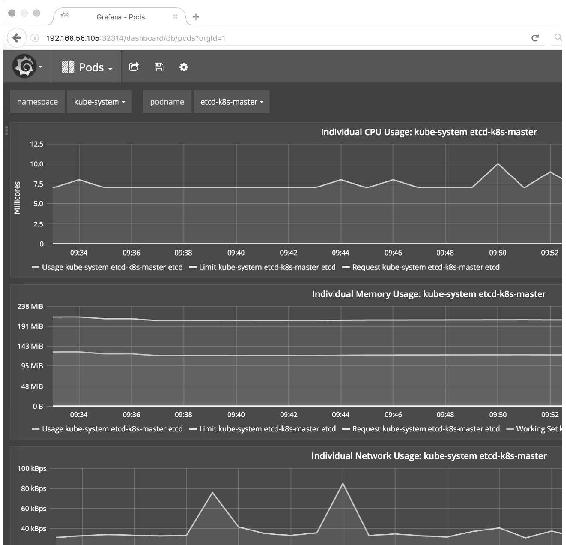
图14-20
在左上角可以切换到不同Namespace的Pod,如图14-21所示。
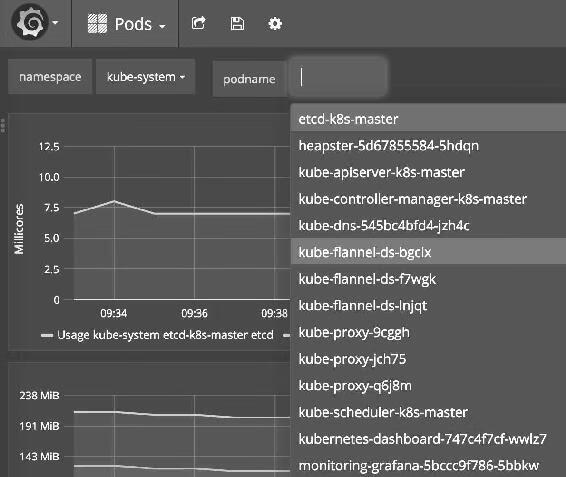
图14-21
Heapster预定义的Dashboard很直观,也很简单。如有必要,可以在Grafana中定义自己的Dashboard,满足特定的业务需求。
14.3 Prometheus Operator
前面我们介绍了Kubernetes的两种监控方案,即Weave Scope和Heapster,它们主要的监控对象是Node和Pod。这些数据对Kubernetes运维人员是必需的,但还不够。我们通常还希望监控集群本身的运行状态,比如Kubernetes的API Server、Scheduler、Controller Manager等管理组件是否正常工作以及负荷是否过大等。
本节我们将学习监控方案Prometheus Operator,它能回答上面这些问题。
Prometheus Operator是CoreOS开发的基于Prometheus的Kubernetes监控方案,也可能是目前功能最全面的开源方案。我们先通过截图了解一下它能干什么。
Prometheus Operator通过Grafana展示监控数据,预定义了一系列的Dashboard,如图14-22所示。

图14-22
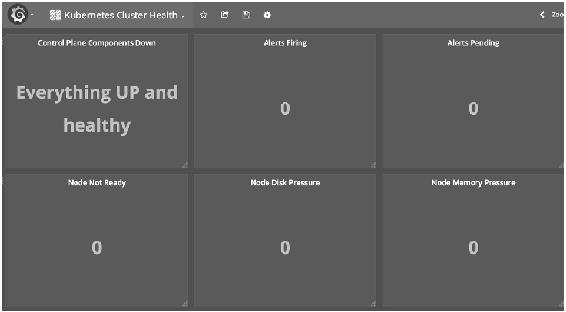
图14-23

图14-24
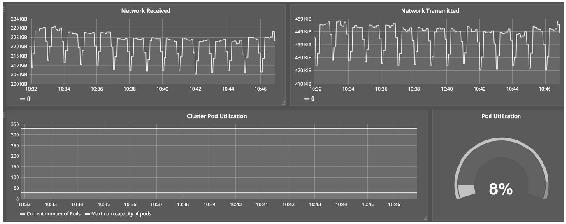
图14-25
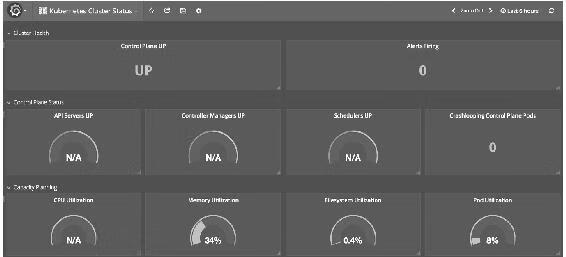
图14-26
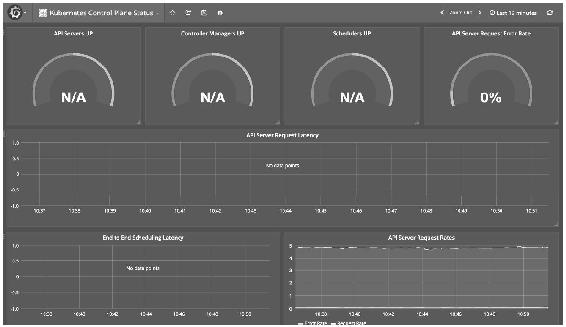
图14-27
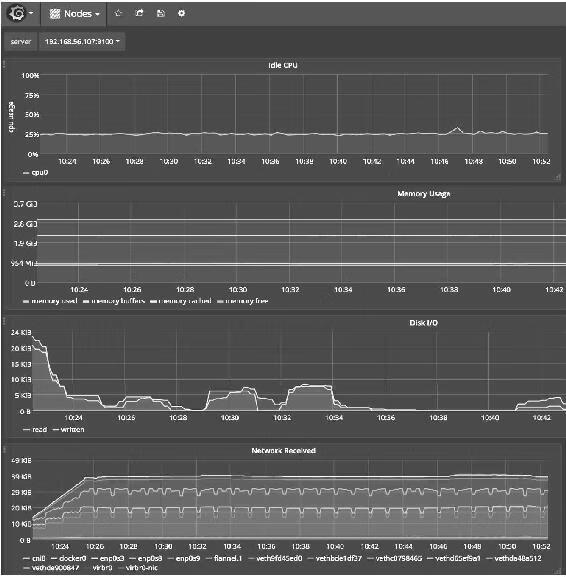
图14-28(a)
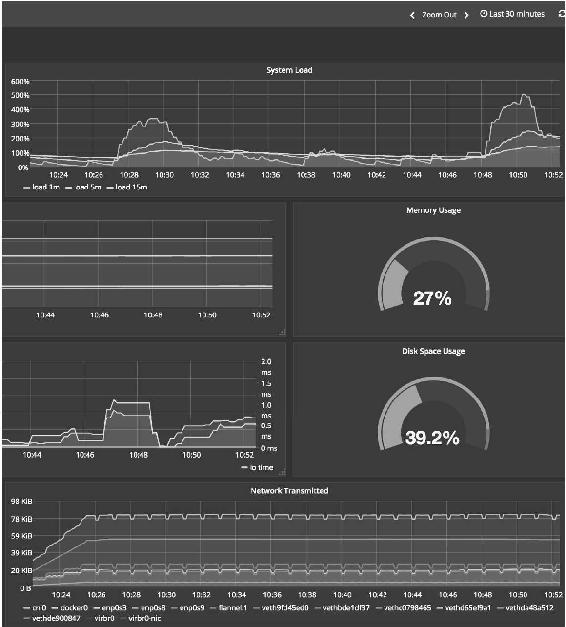
图14-28(b)
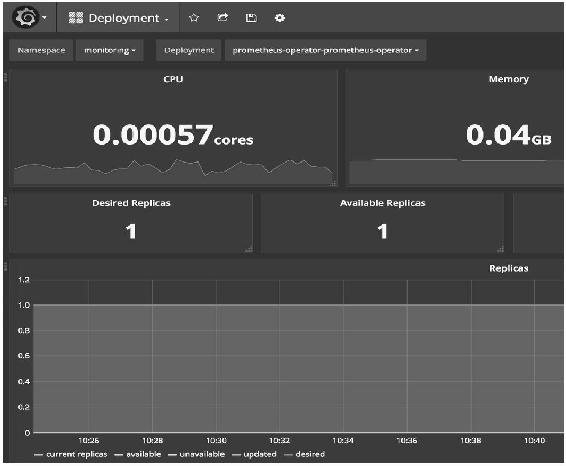
图14-29
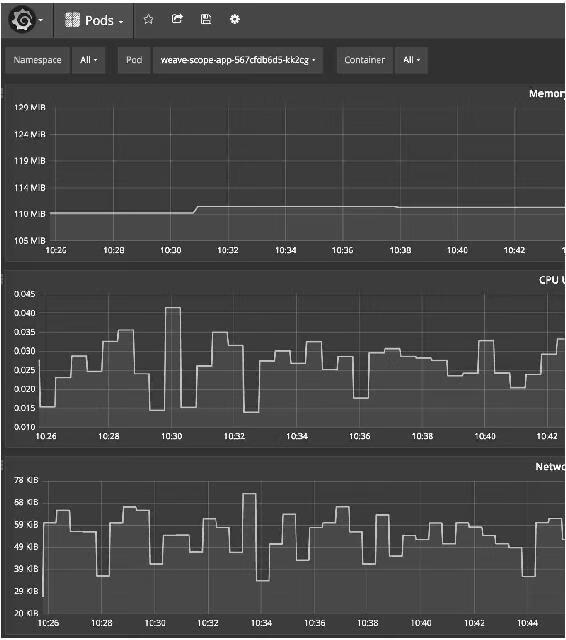
图14-30
这些Dashboard展示了从集群到Pod的运行状况,能够帮助用户更好地运维Kubernetes,而且Prometheus Operator迭代非常快,相信会继续开发出更多更好的功能,所以值得我们花些时间学习和实践。
14.3.1 Prometheus架构
因为Prometheus Operator是基于Prometheus的,所以我们需要先了解一下Prometheus。
Prometheus是一个非常优秀的监控工具。准确地说应该是监控方案。Prometheus提供了数据搜集、存储、处理、可视化和告警一套完整的解决方案。Prometheus的架构如图14-31所示。
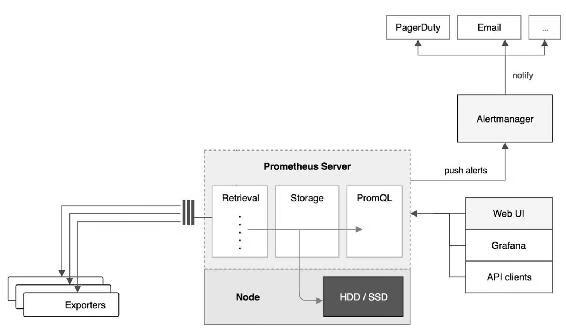
图14-31
官网上的原始架构图比上面这张要复杂一些,为了避免注意力分散,这里只保留了最重要的组件。
1. Prometheus Server
Prometheus Server负责从Exporter拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)供用户使用。
2. Exporter
Exporter负责收集目标对象(host、container等)的性能数据,并通过HTTP接口供Prometheus Server获取。
3. 可视化组件
监控数据的可视化展现对于监控方案至关重要。以前Prometheus自己开发了一套工具,不过后来废弃了,因为开源社区出现了更为优秀的产品Grafana。Grafana能够与Prometheus无缝集成,提供完美的数据展示能力。
4. Alertmanager
用户可以定义基于监控数据的告警规则,规则会触发告警。一旦Alermanager收到告警,就会通过预定义的方式发出告警通知,支持的方式包括Email、PagerDuty、Webhook等。
14.3.2 Prometheus Operator架构
Prometheus Operator的目标是尽可能简化在Kubernetes中部署和维护Prometheus的工作。其架构如图14-32所示。
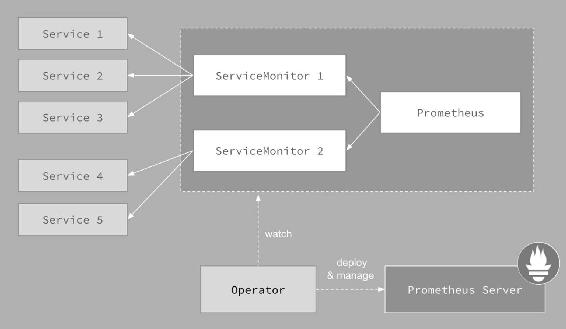
图14-32
图14-32中的每一个对象都是Kubernetes中运行的资源。
1. Operator
Operator即Prometheus Operator,在Kubernetes中以Deployment运行。其职责是部署和管理Prometheus Server,根据ServiceMonitor动态更新Prometheus Server的监控对象。
2. Prometheus Server
Prometheus Server会作为Kubernetes应用部署到集群中。为了更好地在Kubernetes中管理Prometheus,CoreOS的开发人员专门定义了一个命名为Prometheus类型的Kubernetes定制化资源。我们可以把Prometheus看作一种特殊的Deployment,它的用途就是专门部署Prometheus Server。
3. Service
这里的Service就是Cluster中的Service资源,也是Prometheus要监控的对象,在Prometheus中叫作Target。每个监控对象都有一个对应的Service。比如要监控Kubernetes Scheduler,就得有一个与Scheduler对应的Service。当然,Kubernetes集群默认是没有这个Service的,Prometheus Operator会负责创建。
4. ServiceMonitor
Operator能够动态更新Prometheus的Target列表,ServiceMonitor就是Target的抽象。比如想监控Kubernetes Scheduler,用户可以创建一个与Scheduler Service相映射的ServiceMonitor对象。Operator则会发现这个新的ServiceMonitor,并将Scheduler的Target添加到Prometheus的监控列表中。
ServiceMonitor也是Prometheus Operator专门开发的一种Kubernetes定制化资源类型。
5. Alertmanager
除了Prometheus和ServiceMonitor,Alertmanager是Operator开发的第三种Kubernetes定制化资源。我们可以把Alertmanager看作一种特殊的Deployment,它的用途就是专门部署Alertmanager组件。
14.3.3 部署Prometheus Operator
笔者在实践时使用的是Prometheus Operator最新版本v0.14.0。由于项目开发迭代速度很快,部署方法可能会更新,必要时请参考官方文档。
1.下载最新源码
git clone https://github.com/coreos/prometheus-operator.git
cd prometheus-operator
为方便管理,创建一个单独的Namespace monitoring,Prometheus Operator相关的组件都会部署到这个Namespace。
kubectl create namespace monitoring
2. 安装Prometheus Operator Deployment
helm install --name prometheus-operator --set rbacEnable=true--namespace=monitoring helm/prometheus-operator
Prometheus Operator所有的组件都打包成Helm Chart,安装部署非常方便,如图14-33所示。如果对Helm不熟悉,可以参考前面相关的章节。

图14-33
3. 安装Prometheus、Alertmanager和Grafana
helm install --name prometheus --set serviceMonitorsSelector.app=prometheus--set ruleSelector.app=prometheus --namespace=monitoring helm/prometheus
helm install --name alertmanager --namespace=monitoring helm/alertmanager
helm install --name grafana --namespace=monitoring helm/grafana
可以通过kubectl get prometheus查看Prometheus类型的资源,如图14-34所示。
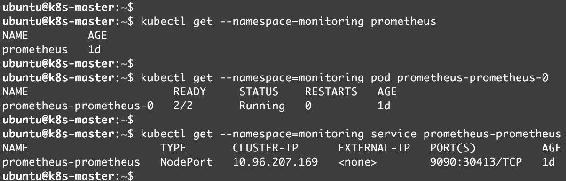
图14-34
为了方便访问Prometheus Server,这里已经将Service类型通过kubectl edit改为NodePort。
同样可以查看Alertmanager和Grafana的相关资源,如图14-35、图14-36所示。
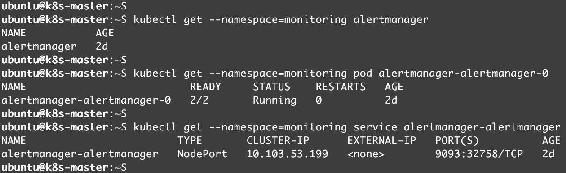
图14-35
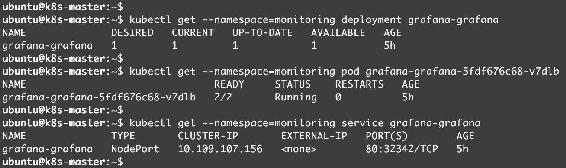
图14-36
Service类型也都已经改为NodePort。
4. 安装kube-prometheus
kube-prometheus是一个Helm Chart,打包了监控Kubernetes需要的所有Exporter和ServiceMonitor。
helm install --name kube-prometheus --namespace=monitoring helm/kube-prometheus
每个Exporter会对应一个Service,为Pormetheus提供Kubernetes集群的各类监控数据,如图14-37所示。
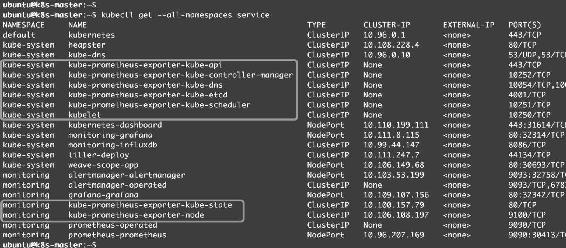
图14-37
每个Service对应一个ServiceMonitor,组成Pormetheus的Target列表,如图14-38所示。
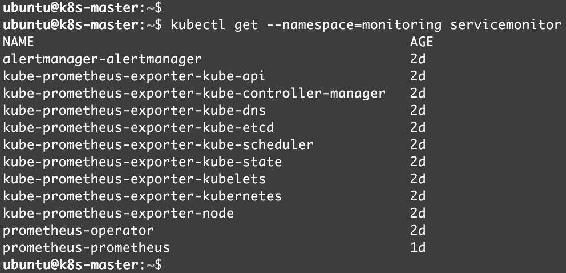
图14-38
与Prometheus Operator相关的所有Pod如图14-39所示。

图14-39
我们注意到有些Exporter没有运行Pod,这是因为像API Server、Scheduler、Kubelet等Kubernetes内部组件原生就支持Prometheus,只需要定义Service就能直接从预定义端口获取监控数据。
通过浏览器打开Pormetheus的Web UI(http://192.168.56.105:30413/targets),如图14-40所示。
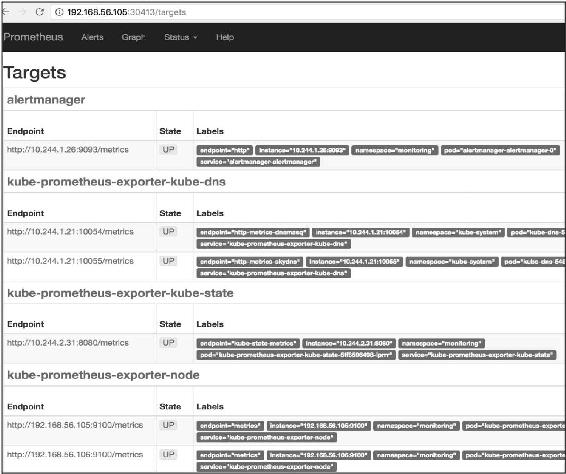
图14-40
可以看到所有Target的状态都是UP。
5. 安装Alert规则
Prometheus Operator提供了默认的Alertmanager告警规则,通过如下命令安装。
sed -ie 's/role: prometheus-rulefiles/app: prometheus/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
sed -ie 's/prometheus: k8s/prometheus: prometheus/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
sed -ie 's/job=\"kube-controller-manager/job=\"kube-prometheus-exporter-kube-controller-manager/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
sed -ie 's/job=\"apiserver/job=\"kube-prometheus-exporter-kube-api/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
sed -ie 's/job=\"kube-scheduler/job=\"kube-prometheus-exporter-kube-scheduler/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
sed -ie 's/job=\"node-exporter/job=\"kube-prometheus-exporter-node/g' contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
kubectl apply -n monitoring -f contrib/kube-prometheus/manifests/prometheus/prometheus-k8s-rules.yaml
6. 安装Grafana Dashboard
Prometheus Operator定义了显示监控数据的默认Dashboard,通过如下命令安装。
sed -ie 's/grafana-dashboards-0/grafana-grafana/g' contrib/kube-prometheus/manifests/grafana/grafana-dashboards.yaml
sed -ie 's/prometheus-k8s.monitoring/prometheus-prometheus.monitoring/g' contrib/kube-prometheus/manifests/grafana/grafana-dashboards.yaml
kubectl apply -n monitoring -f contrib/kube-prometheus/manifests/grafana/grafana-dashboards.yaml
打开Grafana的Web UI(http://192.168.56.105:32342/),如图14-41所示。
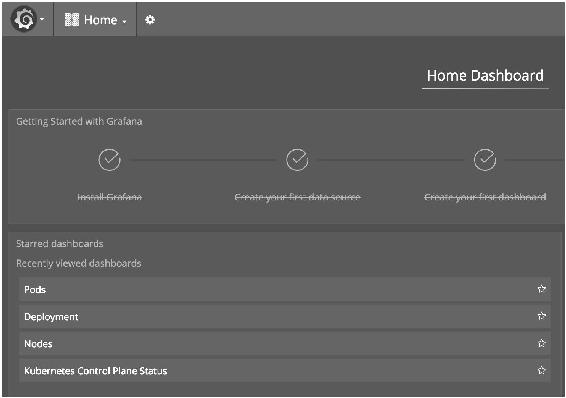
图14-41
Grafana的DataSource和Dashboard已自动配置,单击Home就可以使用我们在最开始讨论过的那些Dashboard了,如图14-42所示。
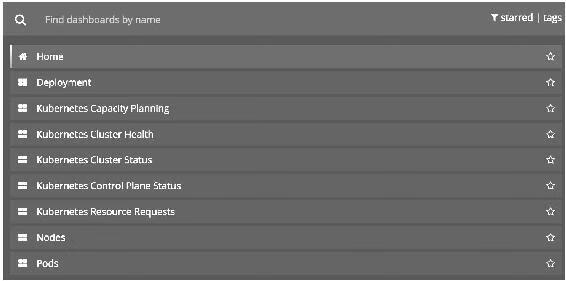
图14-42
14.4 小结
本章我们实践了三种Kubernetes监控方案。
(1)Weave Scope可以展示集群和应用的完整视图。其出色的交互性让用户能够轻松对容器化应用进行实时监控和问题诊断。
(2)Heapster是Kubernetes原生的集群监控方案。预定义的Dashboard能够从Cluster和Pods两个层次监控Kubernetes。
(3)Prometheus Operator可能是目前功能最全面的Kubernetes开源监控方案。除了能够监控Node和Pod,还支持集群的各种管理组件,比如API Server、Scheduler、Controller Manager等。
Kubernetes监控是一个快速发展的领域,随着Kubernetes的普及,一定会涌现出更多的优秀方案。