第12章 网络
本章我们讨论Kubernetes网络这个重要主题。
Kubernetes作为编排引擎管理着分布在不同节点上的容器和Pod。Pod、Service、外部组件之间需要一种可靠的方式找到彼此并进行通信,Kubernetes网络则负责提供这个保障。本章包括如下内容:
(1)Kubernetes网络模型。
(2)各种网络方案。
(3)Network Policy。
12.1 Kubernetes网络模型
Kubernetes采用的是基于扁平地址空间的网络模型,集群中的每个Pod都有自己的IP地址,Pod之间不需要配置NAT就能直接通信。另外,同一个Pod中的容器共享Pod的IP,能够通过localhost通信。
这种网络模型对应用开发者和管理员相当友好,应用可以非常方便地从传统网络迁移到Kubernetes。每个Pod可被看作是一个个独立的系统,而Pod中的容器则可被看作同一系统中的不同进程。
下面讨论在这个网络模型下集群中的各种实体如何通信。知识点前面都已经涉及,这里可当作复习和总结。
1. Pod内容器之间的通信
当Pod被调度到某个节点,Pod中的所有容器都在这个节点上运行,这些容器共享相同的本地文件系统、IPC和网络命名空间。
不同Pod之间不存在端口冲突的问题,因为每个Pod都有自己的IP地址。当某个容器使用localhost时,意味着使用的是容器所属Pod的地址空间。
比如Pod A有两个容器container-A1和container-A2,container-A1在端口1234上监听,当container-A2连接到localhost:1234时,实际上就是在访问container-A1。这不会与同一个节点上的Pod B冲突,即使Pod B中的容器container-B1也在监听1234端口。
2. Pod之间的通信
Pod的IP是集群可见的,即集群中的任何其他Pod和节点都可以通过IP直接与Pod通信,这种通信不需要借助任何网络地址转换、隧道或代理技术。Pod内部和外部使用的是同一个IP,这也意味着标准的命名服务和发现机制,比如DNS可以直接使用。
3. Pod与Service的通信
Pod间可以直接通过IP地址通信,但前提是Pod知道对方的IP。在Kubernetes集群中,Pod可能会频繁地销毁和创建,也就是说Pod的IP不是固定的。为了解决这个问题,Service提供了访问Pod的抽象层。无论后端的Pod如何变化,Service都作为稳定的前端对外提供服务。同时,Service还提供了高可用和负载均衡功能,Service负责将请求转发给正确的Pod。
4. 外部访问
无论是Pod的IP还是Service的Cluster IP,它们只能在Kubernetes集群中可见,对集群之外的世界,这些IP都是私有的。
Kubernetes提供了两种方式让外界能够与Pod通信:
12.2 各种网络方案
网络模型有了,如何实现呢?
为了保证网络方案的标准化、扩展性和灵活性,Kubernetes采用了Container Networking Interface(CNI)规范。
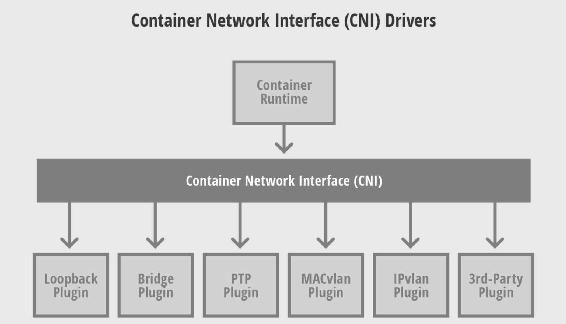
CNI是由CoreOS提出的容器网络规范,使用了插件(Plugin)模型创建容器的网络栈,如图12-1所示。
图12-1
CNI的优点是支持多种容器runtime,不仅仅是Docker。CNI的插件模型支持不同组织和公司开发的第三方插件,这对运维人员来说很有吸引力,可以灵活选择适合的网络方案。
目前已有多种支持Kubernetes的网络方案,比如Flannel、Calico、Canal、Weave Net等。因为它们都实现了CNI规范,用户无论选择哪种方案,得到的网络模型都一样,即每个Pod都有独立的IP,可以直接通信。区别在于不同方案的底层实现不同,有的采用基于VxLAN的Overlay实现,有的则是Underlay,性能上有区别。再有就是是否支持Network Policy。
12.3 Network Policy
Network Policy是Kubernetes的一种资源。Network Policy通过Label选择Pod,并指定其他Pod或外界如何与这些Pod通信。
默认情况下,所有Pod是非隔离的,即任何来源的网络流量都能够访问Pod,没有任何限制。当为Pod定义了Network Policy时,只有Policy允许的流量才能访问Pod。
不过,不是所有的Kubernetes网络方案都支持Network Policy。比如Flannel就不支持,Calico是支持的。我们接下来将用Canal来演示Network Policy。Canal这个开源项目很有意思,它用Flannel实现Kubernetes集群网络,同时又用Calico实现Network Policy。
12.3.1 部署Canal
部署Canal与部署其他Kubernetes网络方案非常类似,都是在执行了kubeadm init初始化Kubernetes集群之后通过kubectl apply安装相应的网络方案。也就是说,没有太好的办法直接切换使用不同的网络方案,基本上只能重新创建集群。
要销毁当前集群,最简单的方法是在每个节点上执行kubeadm reset,然后就可以按照3.3.1小节“初始化Master”中的方法初始化集群了。
kubeadm init --apiserver-advertise-address 192.168.56.105
--pod-network-cidr=10.244.0.0/16
然后按照文档https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/安装Canal。文档列出了各种网络方案的安装方法,如图12-2所示。
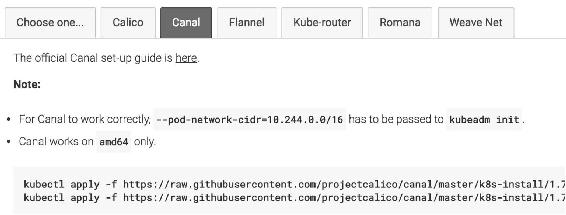
图12-2
执行如下命令部署Canal:
kubectl apply -f
https://raw.githubusercontent.com/projectcalico/canal/master/k8s-install/1.7/rbac.yaml
kubectl apply -f
https://raw.githubusercontent.com/projectcalico/canal/master/k8s-install/1.7/canal.yaml
部署成功后,可以查看到Canal相关组件,如图12-3所示。
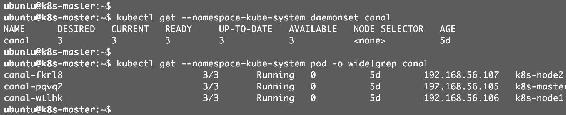
图12-3
Canal作为DaemonSet部署到每个节点,属于kube-system这个namespace。
12.3.2 实践Network Policy
为了演示Network Policy,我们先部署一个httpd应用,其配置文件httpd.yaml如图12-4所示。
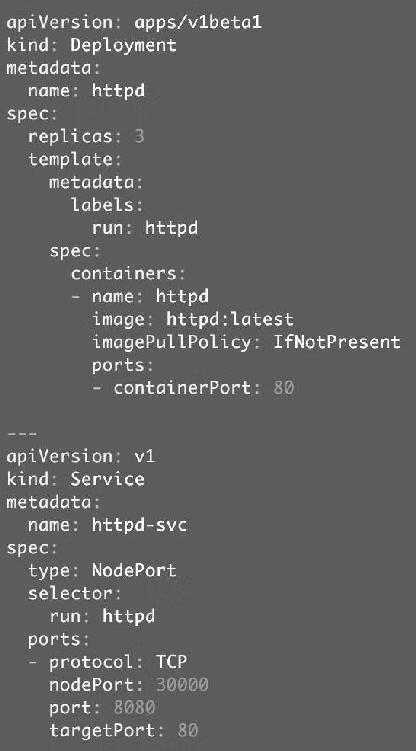
图12-4
httpd有三个副本,通过NodePort类型的Service对外提供服务。部署应用,如图12-5所示。
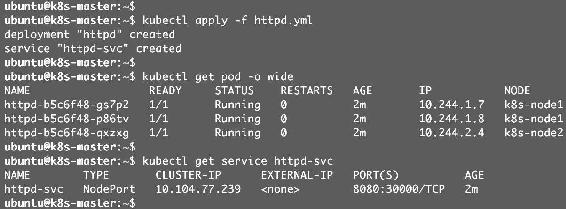
图12-5
当前没有定义任何Network Policy,验证应用可以被访问,如图12-6所示。
(1)启动一个busybox Pod,既可以访问Service,也可以Ping到副本Pod。
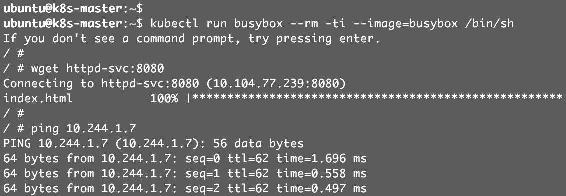
图12-6
(2)集群节点既可以访问Service,也可以Ping到副本Pod,如图12-7所示。
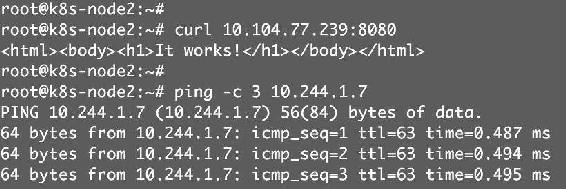
图12-7
(3)集群外(192.168.56.1)可以访问Service,如图12-8所示。

图12-8
现在创建Network Policy,如图12-9所示。
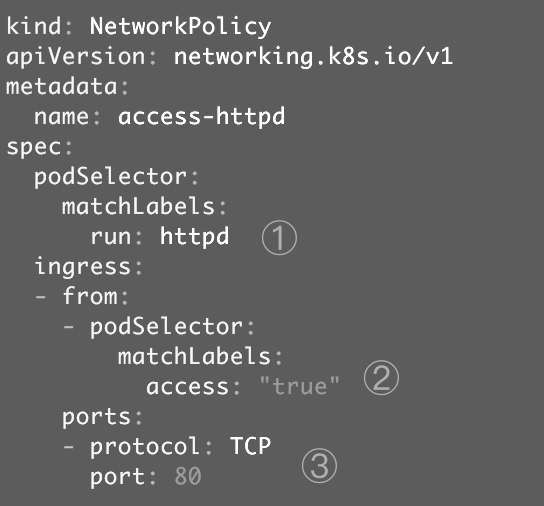
图12-9
① 定义将此Network Policy中的访问规则应用于label为run: httpd的Pod,即httpd应用的三个副本Pod。
② ingress中定义只有label为access: "true"的Pod才能访问应用。
③ 只能访问80端口。
通过kubectl apply创建Network Policy,如图12-10所示。
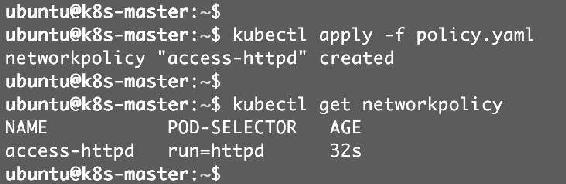
图12-10
验证Network Policy的有效性:
(1)busybox Pod已经不能访问Service,如图12-11所示。
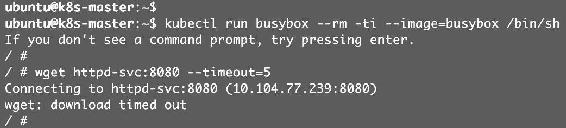
图12-11
如果Pod添加了label access: "true"就能访问到应用,但Ping已经被禁止,如图12-12所示。
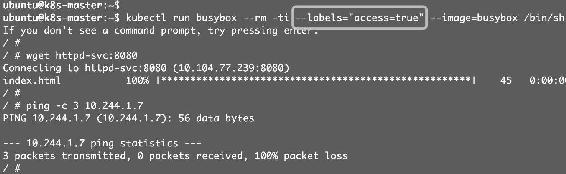
图12-12
(2)集群节点已经不能访问Service,也Ping不到副本Pod,如图12-13所示。
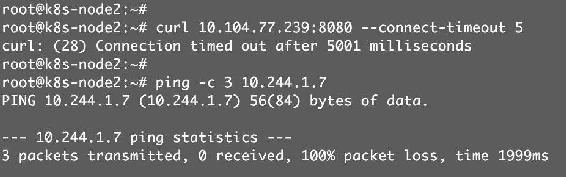
图12-13
(3)集群外(192.168.56.1)已经不能访问Service,如图12-14所示。

图12-14
如果希望让集群节点和集群外(192.168.56.1)也能够访问到应用,可以对Network Policy做如图12-15所示的修改。
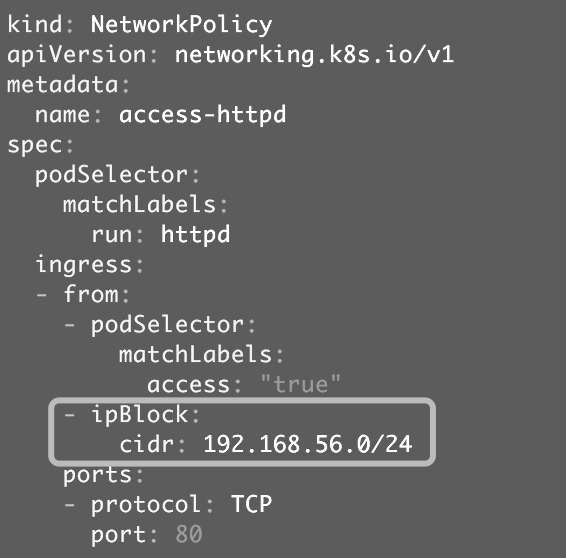
图12-15
应用新的Network Policy,如图12-16所示。

图12-16
现在,集群节点和集群外(192.168.56.1)已经能够访问了,如图12-17、图12-18所示。

图12-17
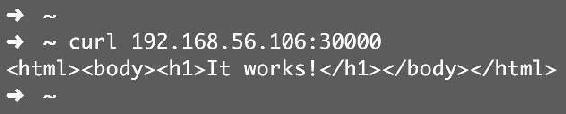
图12-18
除了通过ingress限制进入的流量,也可以用egress限制外出的流量。大家可以参考官网相关文档和示例,这里就不赘述了。
12.4 小结
Kubernetes采用的是扁平化的网络模型,每个Pod都有自己的IP,并且可以直接通信。
CNI规范使得Kubernetes可以灵活选择多种Plugin实现集群网络。
Network Policy赋予了Kubernetes强大的网络访问控制机制。