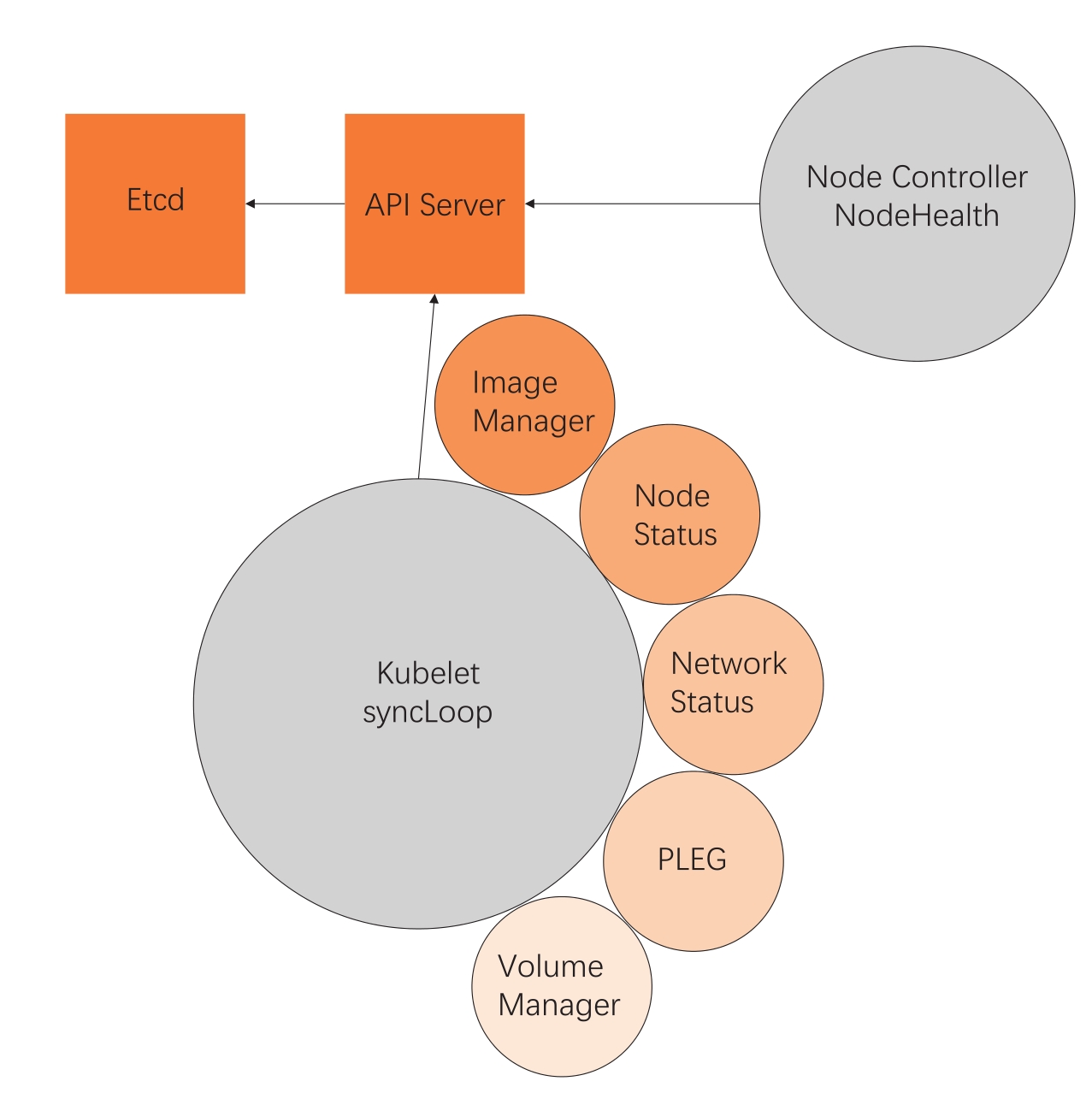
在具体分析这个问题之前,我们先来看一下集群节点就绪状态背后的大逻辑。在Kubernetes集群中,与节点就绪状态有关的组件主要有四个,分别是集群的核心数据库Etcd、集群的入口API Server、节点控制器(Node Controller),以及驻守在集群节点上,直接管理节点的Kubelet,如图14-2所示。
一方面,Kubelet扮演的是集群控制器的角色,它定期从API Server那里获取Pod等相关资源的信息,并依照这些信息,控制运行在节点上的Pod的执行;另外一方面,Kubelet作为节点状况的监视器,获取节点信息,并以集群客户端的角色,把这些状况同步到API Server中。
在这个问题中,Kubelet扮演的是第二种角色。Kubelet会使用上图中的NodeStatus机制,定期检查集群节点状况,并把节点状况同步到API Server中。而NodeStatus判断节点就绪状况的一个主要依据就是PLEG。
PLEG是Pod Lifecycle Events Generator的缩写,它的执行逻辑,基本上是定期检查节点上Pod的运行情况,如果发现感兴趣的变化,PLEG就会把这种变化包装成Event,发送给Kubelet的主同步机制syncLoop处理。
但是,在PLEG的Pod检查机制不能定期执行的时候,NodeStatus机制就会认为,这个节点的状况是不对的,从而把这种状况同步到API Server中。
图14-2 节点状态机
而最终把Kubelet上报的节点状况落实到节点状态的是节点控制这个组件。这里我们故意区分了Kubelet上报的节点状况和节点的最终状态,因为前者其实是我们describe node时看到的Condition,而后者是真正的节点列表里的NotReady状态,如图14-3所示。

图14-3 节点状态事件的上报