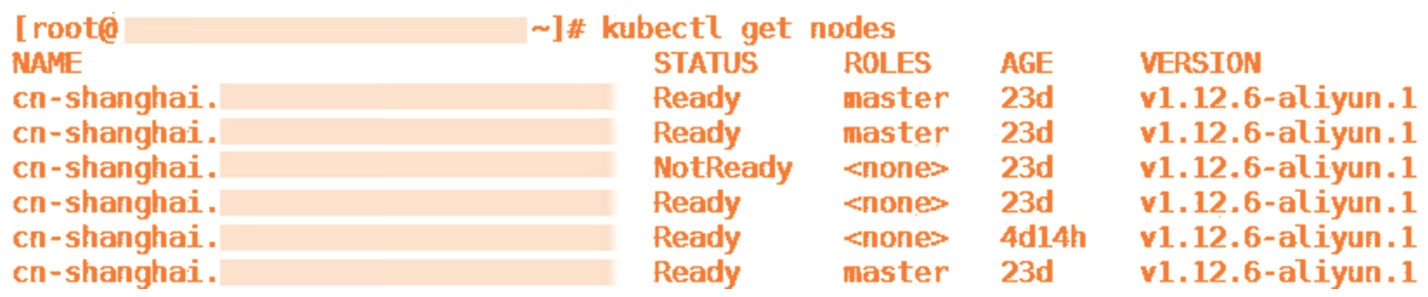
阿里云有自己的Kubernetes容器集群产品。随着Kubernetes集群出货量剧增,线上用户零星地发现,集群会非常低概率地出现节点NotReady(集群就绪状态异常)的情况。据我们观察,这个问题差不多每个月都会有一两个用户遇到。在节点NotReady之后,集群Master没有办法对这个节点做任何控制,比如下发新的Pod,又如抓取节点上正在运行的Pod的实时信息,如图13-1所示。
图13-1 节点就绪状态异常
这里我们稍微补充一点Kubernetes集群的基本知识。Kubernetes集群的“硬件基础”是以单机形态存在的集群节点,这些节点可以是物理机,也可以是虚拟机。集群节点分为Master节点和Worker节点。
Master节点主要用来承载集群管控组件,比如调度器和控制器。而Worker节点主要用来“跑”业务。Kubelet是“跑”在各个节点上的代理,它负责与管控组件沟通,并按照管控组件的指示,直接管理Worker节点,如图13-2所示。
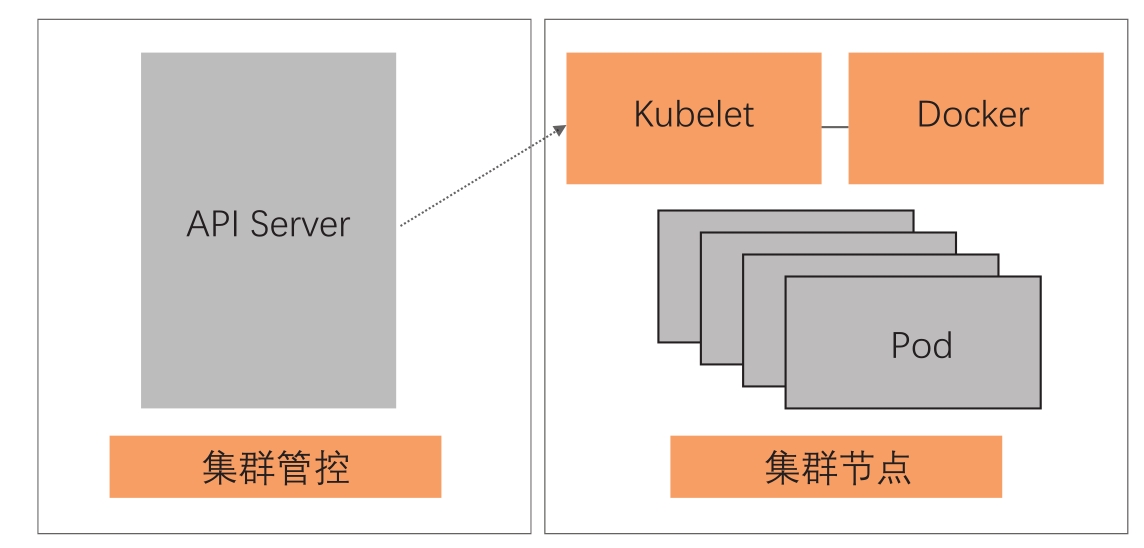
图13-2 集群简易架构图
当集群节点进入NotReady状态的时候,我们需要做的第一件事情,是检查运行在节点上的Kubelet是否正常。在这个问题出现的时候,使用systemctl命令查看Kubelet状态(Kubelet是Systemd管理的一个daemon)发现它是正常运行的。当我们用journalctl查看Kubelet日志的时候,会发现图13-3中的错误。

图13-3 集群节点异常报错
这个报错清楚地告诉我们,容器运行时是不工作的,且PLEG是不健康的。这里容器运行时指的就是docker daemon。Kubelet通过操作docker daemon来控制容器的生命周期。
而这里的PLEG指的是Pod lifecycle event generator,PLEG是Kubelet用来检查运行时的健康检查机制。这件事情本来可以由Kubelet使用polling的方式来做,但是polling有其成本高的缺陷,所以PLEG应运而生。
PLEG尝试以一种“中断”的形式,来实现对容器运行时的健康检查,虽然实际上它是一种同时使用polling和“中断”的折中方案,如图13-4所示。
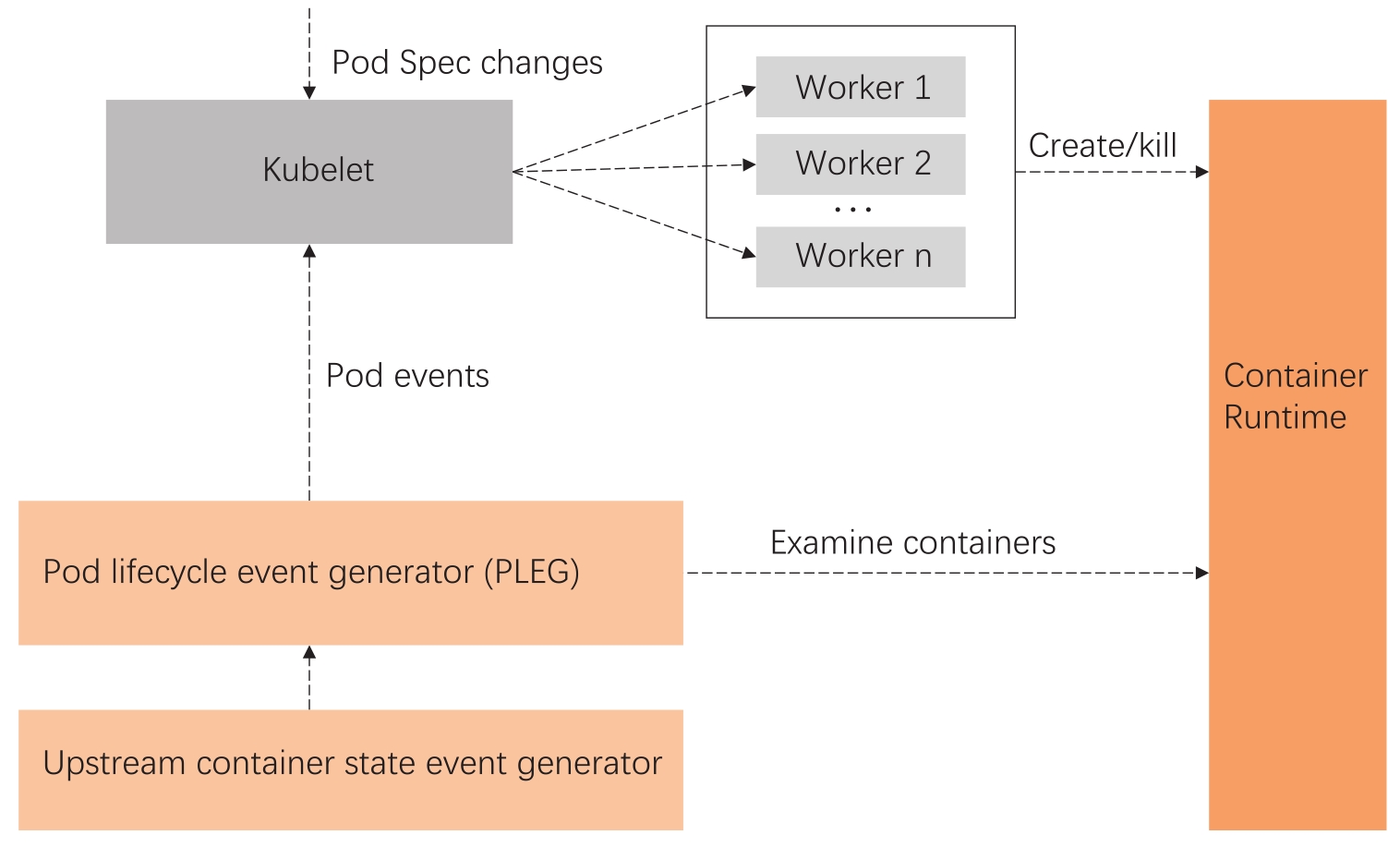
图13-4 PLEG实现架构图
根据上面的报错,我们基本上可以确认容器运行时出了问题。在有问题的节点上,通过docker命令尝试运行新的容器,命令会没有响应,这说明上面的报错是准确的。